Submitted by gouki on 2010, June 27, 7:37 AM
一般来说,限速这东西仅限于FTP,可以给FTP用户进行限速,但,如果你没有FTP,仅有HTTP的情况下如何呢?上次vampire演示过一段,同时还根据URL来读取文件的区块。事实上我们的需要没有那么复杂,向tom zheng博客上的这段就够我们用了。不是吗?再者,现在用nginx的机器应该很多了吧(我没有用,因为,我不可能为线上每个用户都去设置一遍他们的rewrite规则。只能将就一下了。)
原文来自:http://zys.8800.org/index.php/archives/322
nginx可以通过HTTPLimitZoneModule和HTTPCoreModule两个目录来限速。
示例:
limit_zone one $binary_remote_addr 10m;
location / {
limit_conn one 1;
limit_rate 100k;
}
说明:
limit_zone,是针对每个IP定义一个存储session状态的容器。这个示例中定义了一个10m的容器,按照32bytes/session,可以处理320000个session。
然后针对 /目录进行设定。
limit_conn one 1; 是限制每个IP只能发起一个连接。
limit_rate 100k; 是对每个连接限速100k. 注意,这里是对连接限速,而不是对IP限速。如果一个IP允许两个并发连接,那么这个IP就是限速limit_rate x 2。
关于limit_zone的原始文档,请见 http://wiki.nginx.org/NginxHttpLimitZoneModule
关于limit_rate和limit_conn的原始文档,请见 http://wiki.nginx.org/NginxHttpCoreModule
Tags: nginx, 限速
苹果相关 | 评论:0
| 阅读:25163
Submitted by gouki on 2010, June 27, 7:30 AM
Facebook 的照片分享很受欢迎,迄今,Facebook 用户已经上传了150亿张照片,加上缩略图,总容量超过1.5PB,而每周新增的照片为2亿2000万张,约25TB,高峰期,Facebook 每秒处理55万张照片,这些数字让如何管理这些数据成为一个巨大的挑战。本文由 Facebook 工程师撰写,讲述了他们是如何管理这些照片的。
旧的 NFS 照片架构
老的照片系统架构分以下几个层:
# 上传层接收用户上传的照片并保存在 NFS 存储层。
# 照片服务层接收 HTTP 请求并从 NFS 存储层输出照片。
# NFS存储层建立在商业存储系统之上。
因为每张照片都以文件形式单独存储,这样庞大的照片量导致非常庞大的元数据规模,超过了 NFS 存储层的缓存上限,导致每次招聘请求会上传都包含多次I/O操作。庞大的元数据成为整个照片架构的瓶颈。这就是为什么 Facebook 主要依赖 CDN 的原因。为了解决这些问题,他们做了两项优化:
# Cachr: 一个缓存服务器,缓存 Facebook 的小尺寸用户资料照片。
# NFS文件句柄缓存:部署在照片输出层,以降低 NFS 存储层的元数据开销。
新的 Haystack 照片架构
新的照片架构将输出层和存储层合并为一个物理层,建立在一个基于 HTTP 的照片服务器上,照片存储在一个叫做 haystack 的对象库,以消除照片读取操作中不必要的元数据开销。新架构中,I/O 操作只针对真正的照片数据(而不是文件系统元数据)。haystack 可以细分为以下几个功能层:
# HTTP 服务器
# 照片存储
# Haystack 对象存储
# 文件系统
# 存储空间
存储
Haystack 部署在商业存储刀片服务器上,典型配置为一个2U的服务器,包含:
# 两个4核CPU
# 16GB – 32GB 内存
# 硬件 RAID,含256-512M NVRAM 高速缓存
# 超过12个1TB SATA 硬盘
每个刀片服务器提供大约10TB的存储能力,使用了硬件 RAID-6, RAID 6在保持低成本的基础上实现了很好的性能和冗余。不佳的写性能可以通过高速缓存解决,硬盘缓存被禁用以防止断电损失。
文件系统
Haystack 对象库是建立在10TB容量的单一文件系统之上。文件系统中的每个文件都在一张区块表中对应具体的物理位置,目前使用的文件系统为 XFS。
Haystack 对象库
Haystack 是一个简单的日志结构,存储着其内部数据对象的指针。一个 Haystack 包括两个文件,包括指针和索引文件:
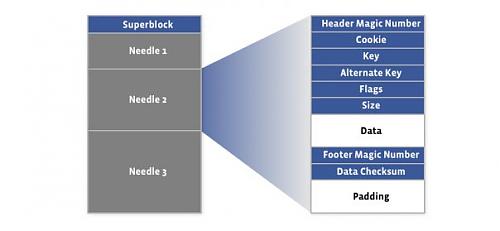
Haystack 对象存储结构


指针和索引文件结构
Haystack 写操作
Haystack 写操作同步将指针追加到 haystack 存储文件,当指针积累到一定程度,就会生成索引写到索引文件。为了降低硬件故障带来的损失,索引文件还会定期写道存储空间中。
Haystack 读操作
传到 haystack 读操作的参数包括指针的偏移量,key,代用Key,Cookie 以及数据尺寸。Haystack 于是根据数据尺寸从文件中读取整个指针。
Haystack 删除操作
删除比较简单,只是在 Haystack 存储的指针上设置一个已删除标志。已经删除的指针和索引的空间并不回收。
照片存储服务器
照片存储服务器负责接受 HTTP 请求,并转换成相应的 Haystack 操作。为了降低I/O操作,该服务器维护着全部 Haystack 中文件索引的缓存。服务器启动时,系统就会将这些索引读到缓存中。由于每个节点都有数百万张照片,必须保证索引的容量不会超过服务器的物理内存。
对于用户上传的图片,系统分配一个64位的独立ID,照片接着被缩放成4种不同尺寸,每种尺寸的图拥有相同的随机 Cookie 和 ID,图片尺寸描述(大,中,小,缩略图)被存在代用key 中。接着上传服务器通知照片存储服务器将这些资料联通图片存储到 haystack 中。
每张图片的索引缓存包含以下数据

Haystack 使用 Google 的开源 sparse hash data 结构以保证内存中的索引缓存尽可能小。
照片存储的写/修改操作
写操作将照片数据写到 Haystack 存储并更新内存中的索引。如果索引中已经包含相同的 Key,说明是修改操作。
照片存储的读操作
传递到 Haystack 的参数包括 Haystack ID,照片的 Key, 尺寸以及 Cookie,服务器从缓存中查找并到 Haystack 中读取真正的数据。
照片存储的删除操作
通知 Haystack 执行删除操作之后,内存中的索引缓存会被更新,将便宜量设置为0,表示照片已被删除。
重新捆扎
重新捆扎会复制并建立新的 Haystack,期间,略过那些已经删除的照片的数据,并重新建立内存中的索引缓存。
HTTP 服务器
Http 框架使用的是简单的 evhttp 服务器。使用多线程,每个线程都可以单独处理一个 HTTP 请求。
结束语
Haystack 是一个基于 HTTP 的对象存储,包含指向实体数据的指针,该架构消除了文件系统元数据的开销,并实现将全部索引直接存储到缓存,以最小的 I/O 操作实现对照片的存储和读取。
本文国际来源:http://www.facebook.com/FacebookEngineering#/note.php?note_id=76191543919&ref=mf
中文翻译来源:COMSHARP CMS 官方网站
我的来源:http://zys.8800.org/index.php/archives/334
Tags: facebook, 架构
苹果相关 | 评论:0
| 阅读:30352
Submitted by gouki on 2010, June 26, 9:53 AM
快期末考试了,书籍都在笔记本里,如果拿着笔记本看书一来是太重,二来时间也不长,三来时间长了发热很厉害。
自从有了ipad,自己也在折腾它,网上找了一下哪些软件能够看word,excel之类的。搜到的就是goodreader,于是欣欣然装了上去。
文件的上传很有意思,它是自己开了一个web页面,可以在里面简单的创建目录和上传文件。确实比较方便。打开word后,效果基本没有什么变化(我没有测试docx这种07以上的格式,不知道结果如何)
至于pdf reader嘛。那肯定是必装软件了。要知道我很多电子书都是pdf的。买epub文件太贵 ,但是PDF我可是保存了不少。ipad最大的功能就是用来看书,我不需要背上很多很多书就能看了。
刚才在论坛里看到有人说为什么选择ipad而不是上网本之类的,我觉得有一点说的很好,那就是【大意,我不记得原文了】:1、ipad的屏幕比普通上网本要好很多2、ipad的启动非常快,不象上网本等启动和关闭都要不少时间。3、当看PDF之类的文章时,上网本不能竖起来看全屏,而要不停的拖动页面。4、这是3的扩充,上网本你不得不带一个鼠标备着(假设你对触摸板不怎么感冒)。5、看到一些重要内容需要放大时,没有ipad方便。【当然,你说要做笔记什么的,可能在输入上并不一定比上网本好,但你在看书的时候,有多少时间会做笔记?偶尔输入一两个字也还是可以忍受的】
OK,不折腾了。开始看书了。。。
Tags: ipad, goodreader, pdfreader
Misc | 评论:0
| 阅读:29299
Submitted by gouki on 2010, June 25, 8:37 PM
PHP处理COOKIE是一件很方便的事情。print_r($_COOKIE)就可以打印所有的cookie变量。而且cookie也能够存为数组。确实操作和应用都非常方便 。
以前,对于子域和根域下的cookie并没有研究太深。因为都直接设在根域的。以前注意cookie是路径(path),这个的影响也是有的。不过现在大多数程序的cookie都是设在根路径(“/”)下,所以也回避了不少问题。
以下是老王提出的问题和解决方法(子域和根域同名cookie的处理),引伸开的话,你也可以测试一下,根路径与子路径下同名cookie的情况。【果然,老王文章结尾就是这样的提问,呵呵】
我们都知道,在子域下请求时,浏览器会把子域和根域下的Cookie一起发送到服务器,那如果子域和根域下有一个同名Cookie,当我们在PHP里使 用$_COOKIE访问时,到底生效的是哪个呢?下面做试验测试一下,测试使用Firefox,用到了以下插件:SwitchHosts+WebDeveloper+Firebug。
注意:试验结果可能因为浏览器的不同而存在差异。
首先通过SwitchHosts设定虚拟域名:www.foo.com,并且配置好Web服务器,当然,你手动设置Hosts文件也可以,我本意是为了多介绍几个工具。
然后编写设置Cookie的PHP脚本,先设置子域,再设置根域:
PHP代码
- <?php
- setcookie("bar", "www", time() + 10, "/", "www.foo.com");
- setcookie("bar", "foo", time() + 10, "/", ".foo.com");
- ?>
再编写浏览Cookie的脚本:
PHP代码
- <?php
- var_dump($_COOKIE);
- ?>
BTW:最初写脚本的时候我竟然在setcookie前使用了var_dump,也就是在发送请求头之前有了输出,犯了这样的初学者错误实在是罪过,可更令人惊讶的是脚本没有报错,查了半天原来是因为php.ini里缺省output_buffering = 4096。
先设置再浏览,就能看到结果了,结果显示有效的是子域下的Cookie。
重开一个浏览器窗口,并使用WebDeveloper删除Cookie,或手动删除,避免对结果造成影响。
然后调换两次调用setcookie的顺序,也就是先设置根域,再设置子域:
PHP代码
- <?php
- setcookie("bar", "foo", time() + 10, "/", ".foo.com");
- setcookie("bar", "www", time() + 10, "/", "www.foo.com");
- ?>
先设置再浏览,就能看到结果了,结果显示有效的是根域下的Cookie。
重复两次测试过程,并用Firebug记录下请求头的差异:
第一次先设置子域,再设置根域:请求头
Cookie的值是bar=www;bar=foo,结果有效的是bar=www
第二次先设置根域,再设置子域:请求头
Cookie的值是bar=foo;bar=www,结果有效的是bar=foo
也就说,同名Cookie对于服务端PHP来说,在请求头Cookie中,哪个在前哪个生效,后面的会被忽略。
如果使用的不是Firefox,那就用不了Firebug,此时可以用PHP代码来检测Cookie头:
PHP代码
- if (isset($_SERVER['HTTP_COOKIE'])) var_dump($_SERVER['HTTP_COOKIE']);
以上的实验结论是基于Firefox而言的,由于不同的浏览器发送Cookie的策略可能有差异,所以在其他浏览器上结果可能会有所不同,比如在 Safari下就始终是子域有效,其他浏览器如Opera,Chrome等未仔细测试。鉴于这个混乱的结论,所以还是不要在子域和根域下使用同名 Cookie为好!
题外话:类似的情况,如子目录和根目录下的同名Cookie是什么情况,读者可以自行测试。
--EOF--
原文来自:http://hi.baidu.com/thinkinginlamp/blog/item/899551dacd807ad6b6fd48cd.html
Tags: cookie, 老王, 子域, 根域
PHP | 评论:1
| 阅读:32092
Submitted by gouki on 2010, June 25, 2:14 PM
本以为越狱是一件非常难很有技巧的事情,怎么着也得在身上刻上地图,然后潜入。最后再杀掉两三个人再出去?
后来,在网上找了一下,非常方便。只要两个工具就OK了。
一个是shsh备份工具,一个是spirit。在电脑下运行一下就OK了
额,看这三篇文章吧:
1、iPad 越狱前的准备工作——备份
2、Spirit越狱成功 详细步骤放出
3、iPad越狱失败后怎么办?
4、iPad越狱失败不用怕 iPad白苹果恢复教程
本想放到一篇博客里,但为了记录下来。所以准备每篇文章开一贴,以保存这些数据。
Tags: apple, ipad, spirit
Misc | 评论:0
| 阅读:22103


