Submitted by gouki on 2010, April 19, 9:28 AM
这篇文章有点意思,不过我更多的想的不是他所说的这种分类,一般来说,在电子商务里面这方面,这方面其实是最难界定的。产品A既可能属于B分类,也可能是属于C分类。但是在促销的时候,B分类产品不打折,C分类可以打折,这时你把A产品怎么处理?打折还是不打折?
QQ好友列表:
+太原(9/39)
+运城老乡(9/49)
+西安(9)
+学校(19)
问题:
QQ好友上新建了一个女孩组和一个西安组,上面的整理方式,发现经常 弄错,比如“XX“同学,是我女友介绍认识的,我将她顺便放在太原组里面,后来知道她不在太原,山西运城人士,当我和她聊天时候,连我自己都很吃惊经常 问,太原的一些情况,很是影响人家心情,搞的自己也很尴尬。
很长一段时间,渐渐习惯这种分类,突然间觉得这样的分类很不科 学,很明显,这涉及SNS的经典问题,以及信息架构的经典问题:如何做一个有效分类?
我的需求:
1. 新添加一个朋友的时候固定存放
2. 常联系的人立马可以找到
3. 和我趣味相投的统统放在一起,玩到一起的,闲来没事可以出去一起 疯狂的
4. 能够表达出我的职业规划,定位明确,可以清楚的阐述我的社会活动 能力与人际关系
详细说明:
要做到:
1. 清楚地表现好友信息:一看这个分类,就知道这一类型的人是干什么 的,和他们应该在那些方面可以顺利沟通清楚问题。
2. 层次结构清晰:一看这个分类,就知道什么人在这个分类下面,分类 下面涉及到什么朋友
不应该是:
1. 这个分类给人一种距离感,陌生
2. 我想找的是分类A, 但你却出现在分类B中?NND
3. 这个分类做出来不能让我自己都犯晕!
问题的表象是如何找到一个合理的好友分类方式,深入问题的本 质,其实是不满足我的需求,而QQ体现的核心是我的二字,因此人际关系、社会活动能力、我的职业规 划就是该信息架构问题的关键!这样就有了看似简单但能立刻解决问题的分类方式:
QQ好友列表:
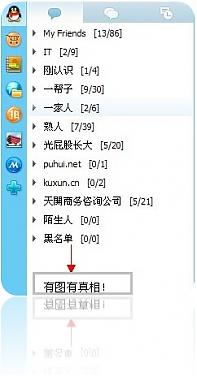
+熟人(9/19)
+一家人(9/19)
+一帮子(9/14)
+光屁股长大(9/100)
+刚认识(2/10)
+xxx公司
+xxx公司
一切就这么简单,采用这个分类以后,立 即心旷神怡!
--EOF--
原文来自:http://www.cnblogs.com/u_xiaomo/archive/2010/04/18/1714953.html
不过话说回来,抛开电子商务的因素,wordpress的分类设计的就是挺不错的。一篇文章在你迷惘的时候,可以放到多个分类里,分类又只是相当于一个标签。这样的设计让使用者也很爽。只是开发的时候累一点,SQL的性能差一点点而己。
Tags: wordpress, qq, 架构, 数据库
Baby | 评论:2
| 阅读:29068
Submitted by gouki on 2010, April 14, 11:20 AM
这是来自iOrange.cc的文章,主要就讲了两个可能会被常用的时间函数。内容如下:
按时间搜索数据在mysql里应该是用的比较频繁的了。
iOrange系统里的时间都是按:xxxx-xx-xx xx:xx:xx这种格式存放的,大多数时候这个都没问题,但是,当你想使用其他格式来显示数据时就悲剧了,例如你想显示成 10/04/01 21:20 这种就很悲剧-__-,所以强烈建议保存时间戳的时候尽量存储一个UNIX时间戳,这样以后就方便很多了^_^
回归正题,第一个时间函数是:UNIX_TIMESTAMP,这个函数可以将xxxx-xx-xx xx:xx:xx这种格式的时间转换成一个unix时间戳格式的数字。例如下面那条语句:
update bookposts set lastpost = UNIX_TIMESTAMP(createdate) 这样就能将createdate字段上的时间更新到lastpost上去了。
第二个函数则跟第一个刚好相反:FROM_UNIXTIME,这个函数可以将一个UNIX时间戳转换成xxxx-xx-xx xx:xx:xx这种格式。用法大致如下:
SELECT COUNT(*) AS `newmembers` FROM `cdb_members` WHERE FROM_UNIXTIME(regdate, ‘%Y-%m-%d’) = ‘2010-04-01′”
--EOF--
不过,个人认为还是采用:xxxx-xx-xx xx:xx:xx比较好,这是因为,时间戳和这种日期格式在数据库里存储所占的字节都是一样的,而日期格式却没有1970~2038年这个限制。在计算时间区间的时候,用Between和and时,对于日期格式会更加方便,而时间戳则需要多计算一次。
参考:
1.Mysql时间函数 http://neatstudio.com/show-443-1.shtml
2.用TIMESTAMP类型取代INT和DATETIME[转] http://neatstudio.com/show-150-1.shtml
3.精通MYSQL数据库——连载八 http://neatstudio.com/show-263-1.shtml
Tags: from_unixtime, unix_timestamp
Baby | 评论:0
| 阅读:25644
Submitted by gouki on 2010, April 13, 8:51 AM
公交换乘一直以来是很让人头疼的问题。一般来说一次换乘还能相对比较简单,如果需要多次换乘那就复杂了。
在google map或者任意一个MAP上,你都可以选择从A点到B点的换乘方案,并且显示在地图上,抛开完整的数据库和大量的数据外,剩下的就是数据库设计了。
博客园有位作者写了几篇文章,可以为想入这行,或者想写类似程序的朋友做一点参考的。【我最初参考的一个什么叫龙腾还是啥来着的公交换乘软件的,它用的是access数据库,破解后直接看的数据库结构并进行反推的。那也是几年前的事情了】
这几篇文章中,有一篇讲的是步行的介入,可惜是纯代码,解释不多,但也能一看吧。
原文很长,我这里正好把几篇文章列出来,如此而己。。。。
以下文章将逐步深入地介绍公交车路线查询系统后台数据库的设计:
1.查询算法—— 实现站点到站点的换乘路线查询
2.关联地名和站点——实现通过地名或站点的路线查询
3.引入步行路线——在乘车路线中插入步行路线
4.换乘算法的 改进与优化——改进原查询算法,提高其查询效率
Tags: 公交, 线路查询
Baby | 评论:1
| 阅读:22164
Submitted by gouki on 2010, April 7, 2:38 PM
想把自己所有的数据打个包,结果才发现,原来我的目录居然有30多G,把曾给卖给别人的空间中的19G数据清除后,发现还有12G的软件数据,惊讶的要死,去看了一下,用的是懒宝宝的告诉我的命令:du -sh /xxxxx/
发现mysql/data下的数据居然有12G,想着怎么也不可能会有这么大的数据啊?仔细一看,原来这12G全是log文件。找了一些资料,才把这个log清除掉。。
方法如下:
第一种技巧:
XML/HTML代码
- 1 查询musql-bin,mysql操作日志
- mysql> show master logs;
-
- 2 删除,保留最新
- mysql>purge master logs to ‘mysql-bin.00001′;
-
- 3 my.cnf中去掉log-bin就可不让生成这些日志文件了。
第二种技巧:
XML/HTML代码
- 清理mysql的日志文件
- 发现var/db/mysql目录下有这么多
- mysql-bin.000001
- …
- mysql-bin.000023
- mysql-bin.index
- 而且比较大
-
- 数据库的操作日志
- mysql> reset master;
- 可以清理这些文件。
这两种情况都可以,比较偏 向于第一种,但我是因为要备份就直接用的第二种了。反正数据也没有出错过,资料来自于:http://www.tech-q.cn/thread-3198-1-1.html
Tags: mysql, mysql-bin, 日志
Baby | 评论:0
| 阅读:23536
Submitted by gouki on 2010, April 7, 1:17 PM
今天一大早,把我的数据都tar了一遍,结果。。。mysql数据库就出现了“Got error 28 from storage engine”错误,去google搜索了一下,发现问题这样解决;
1、
XML/HTML代码
- 磁盘临时空间不够导致。
- 解决办法:
- 清空/tmp目录,或者修改my.cnf中的tmpdir参数,指向具有足够空间目录
2、
XML/HTML代码
- mysql报以下错的解决方法
- ERROR 1030 (HY000): Got error 28 from storage engine
-
- 出现此问题的原因:临时空间不够,无法执行此SQL语句
- 解决方法:将tmpdir指向一个硬盘空间很大的目录即可
当然两个说法都是一样。所以基本肯定是空间没有了。去其他磁盘看了一下,果然。。
郁闷了一下,把备份文件先删除了就正常了。
两个技巧来自:http://www.aslibra.com/blog/read.php/794.htm,感谢这个google搜索的头条帮我解决了这个问题
Baby | 评论:1
| 阅读:71107


