这是我试了很多的代码之后才。。。。
#select id,count(1) as cnt from feeds_datas group by link HAVING count(1) > 7 order by cnt DESC
#delete from feeds_datas where link = (select link from feeds_datas WHERE id in ()
#delete from feeds_datas where id in (6697,7127,6798,4557,4558,6086,6087,6088,6089)
#select id from feeds_datas group by link HAVING count(link) > 1
#delete from feeds_datas as a WHERE a.in in (select b.id from feeds_datas as b group by b.link HAVING count(b.link) > 1 )
#delete from feeds_datas t1,(select link from feeds_datas group by link HAVING count(1) > 1) t2 where t1.link = t2.link
#and id not in (select min(id) from feeds_datas group by link having count(link )>1)
delete feeds_datas as a from feeds_datas as a,
(
select *,min(id) from feeds_datas group by link having count(1) > 1
) as b
where a.link = b.link and a.id > b.id;
加#的都是失败的,其中最后一条SQL我很纳闷,如果把delete 后面的 feeds_datas as a去掉,那么sql就报错,说是不许right syntax之类的。加上就OK。
记录一下。。
网上有很多资料,可以参考:
1、http://yueliangdao0608.blog.51cto.com/397025/81390
2、http://zhidao.baidu.com/question/85817899

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
mysql子查询删除
Submitted by gouki on 2011, October 15, 6:06 PM
mysql:Lost connection to MySQL server at 'reading initial communication packet', system error: 0
Submitted by gouki on 2011, September 28, 1:29 PM
远程管理数据库的时候,以前都是用phpmyadmin,后来就再也不用这种了,一来是因来速度慢,二来扔在服务器上,人人都可以访问太危险了。。所以我现在在用navicat的ssh方式访问。其实我比较喜欢用SQLyog的,但是它没有mac的版本。
OK,现在我们开始用nvaicat来访问吧。
一台服务器正常了,二台正常了,结果,第三台不正常了。报错:
- Lost connection to MySQL server at 'reading initial communication packet', system error: 0
然后找资料了。
1、有人说,在mysqld启动的时候加入skip-name-resolve,于是我在my.cnf加上,也没用。。。
2、又有人说,需要在/etc/hosts.allow里加上mysqld:allow,好吧,我继续加上,仍然没用。参考:http://www.bramschoenmakers.nl/en/node/595
3、最后找不同点。突然发现,原来连接不上的那台服务器的my.cnf里居然有一个bind-address:xx.xxx.xxx.xxx,绑定了IP,所以ssh通道连接的时候,不能工作,改成127.0.0.1后一切正常
4、结果改完后发现,本地代码连接远程的时候,连接不上数据库了,代码里写死IP的所以无法改变。最终再找资料把bind-address改为0.0.0.0,然后一切都正常了(这个只适合在局域网测试上,其他情况下尽量不要改,出了问题可不要找我。。。。)
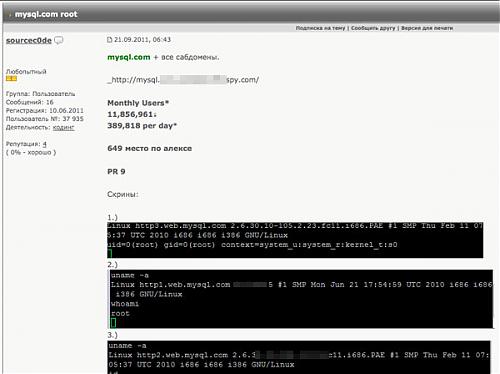
震精:[图]MySQL.com被黑 黑客挂牌出售其root权限
Submitted by gouki on 2011, September 27, 12:07 PM
在cnbeta上看到这个新闻的时候,震精了啊。
新闻不知道是真是假,所以我纯转贴,莫找我啊,原文来自:http://www.cnbeta.com/articles/156424.htm
Amorize的安全研究人员最近表示,已经确认黑客入侵mysql.com,并通过iframe的方法让用户感染了恶意代码,他们已经追踪到佛罗里达和瑞典两个恶意软件托管地,在当地时间周一下午依然在对mysql.com的访客实施攻击,用户凭据可能已经遭到了窃取,因此建议mysql.com注册过的用户修改自己与此相同的密码。
更糟的是研究发现,mysql.com的root权限似乎已经开始在俄罗斯的地下黑客论坛挂牌出售,价格3000美元,黑客们只要给钱就可以获得访问mysql.com的权限,可见问题的糟糕程度。
几个无限分类的设计
Submitted by gouki on 2011, August 18, 10:57 PM
之前在博客里贴过无限分类的介绍,那是官方的例子,但上次在给同事们做介绍的时候,却发现官方的网站已经打不开了。所幸,又找到了一篇,好象这个才是原文?
原文来自:http://www.vbmysql.com/articles/database-design/managing-hierarchical-data-in-mysql
为了这次保证所有的数据都能够记录下来而不是再被茫茫的互联网淹没,所以我做了备份。
mysql.7z
但同样的,我也再次复制一部分的内容下来,好象是说这种无限分类的效率,在被其他项目查询的时候是最高的,但CRUD的时候就有点纠结。
OK,上主菜:
The Nested Set Model
What I would like to focus on in this article is a different approach, commonly referred to as the Nested Set Model. In the Nested Set Model, we can look at our hierarchy in a new way, not as nodes and lines, but as nested containers. Try picturing our electronics categories this way:

Notice how our hierarchy is still maintained, as parent categories envelop their children.We represent this form of hierarchy in a table through the use of left and right values to represent the nesting of our nodes:
CREATE TABLE nested_category ( category_id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(20) NOT NULL, lft INT NOT NULL, rgt INT NOT NULL ); INSERT INTO nested_category VALUES(1,'ELECTRONICS',1,20),(2,'TELEVISIONS',2,9),(3,'TUBE',3,4), (4,'LCD',5,6),(5,'PLASMA',7,8),(6,'PORTABLE ELECTRONICS',10,19),(7,'MP3 PLAYERS',11,14),(8,'FLASH',12,13), (9,'CD PLAYERS',15,16),(10,'2 WAY RADIOS',17,18); SELECT * FROM nested_category ORDER BY category_id; +-------------+----------------------+-----+-----+ | category_id | name | lft | rgt | +-------------+----------------------+-----+-----+ | 1 | ELECTRONICS | 1 | 20 | | 2 | TELEVISIONS | 2 | 9 | | 3 | TUBE | 3 | 4 | | 4 | LCD | 5 | 6 | | 5 | PLASMA | 7 | 8 | | 6 | PORTABLE ELECTRONICS | 10 | 19 | | 7 | MP3 PLAYERS | 11 | 14 | | 8 | FLASH | 12 | 13 | | 9 | CD PLAYERS | 15 | 16 | | 10 | 2 WAY RADIOS | 17 | 18 | +-------------+----------------------+-----+-----+
We use lft and rgt because left and right are reserved words in MySQL, see http://dev.mysql.com/doc/mysql/en/reserved-words.html for the full list of reserved words.
So how do we determine left and right values? We start numbering at the leftmost side of the outer node and continue to the right:

This design can be applied to a typical tree as well:

When working with a tree, we work from left to right, one layer at a time, descending to each node’s children before assigning a right-hand number and moving on to the right. This approach is called the modified preorder tree traversal algorithm.
因为我已经在压缩包里做了备份,所以我图片就引用外站的了。
转:geohash-用字符串实现附近地点搜索
Submitted by gouki on 2011, July 13, 10:30 PM
依稀记得MYSQL5开始支持经纬度了,但在项目中没用过,所以现在也记不清是否有此功能了,不过今天看到这篇文章的时候,感觉这样的处理方法也不错。
原文来自:http://tech.idv2.com/2011/07/05/geohash-intro/
上回说到了用经纬度范围实现附近地点搜索。 一些小型应用中这样做没问题,但在大型应用中它有个显著的缺点:速度慢。慢的原因有两个, 第一是范围比较的索引利用率并不高,第二是SQL语句极其不稳定(不同的当前位置会产生完全不同的SQL查询),很难缓存。
可以考虑使用geohash算法。
geohash是一种地址编码,它能把二维的经纬度编码成一维的字符串。比如,北海公园的编码是wx4g0ec1。
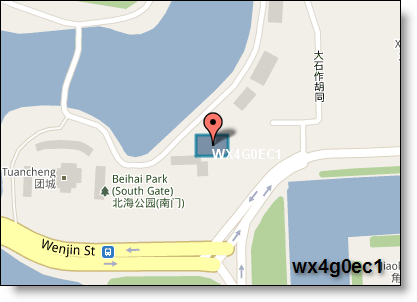
geohash有以下几个特点:
首先,geohash用一个字符串表示经度和纬度两个坐标。某些情况下无法在两列上同时应用索引 (例如MySQL 4之前的版本,Google App Engine的数据层等),利用geohash,只需在一列上应用索引即可。
其次,geohash表示的并不是一个点,而是一个矩形区域。比如编码wx4g0ec19,它表示的是一个矩形区域。 使用者可以发布地址编码,既能表明自己位于北海公园附近,又不至于暴露自己的精确坐标,有助于隐私保护。
第三,编码的前缀可以表示更大的区域。例如wx4g0ec1,它的前缀wx4g0e表示包含编码wx4g0ec1在内的更大范围。 这个特性可以用于附近地点搜索。首先根据用户当前坐标计算geohash(例如wx4g0ec1)然后取其前缀进行查询 (SELECT * FROM place WHERE geohash LIKE 'wx4g0e%'),即可查询附近的所有地点。
geohash的算法
下面以(39.92324, 116.3906)为例,介绍一下geohash的编码算法。首先将纬度范围(-90, 90)平分成两个区间(-90, 0)、(0, 90), 如果目标纬度位于前一个区间,则编码为0,否则编码为1。由于39.92324属于(0, 90),所以取编码为1。然后再将(0, 90)分成 (0, 45), (45, 90)两个区间,而39.92324位于(0, 45),所以编码为0。以此类推,直到精度符合要求为止,得到纬度编码为1011 1000 1100 0111 1001。
| 纬度范围 | 划分区间0 | 划分区间1 | 39.92324所属区间 |
| (-90, 90) | (-90, 0.0) | (0.0, 90) | 1 |
| (0.0, 90) | (0.0, 45.0) | (45.0, 90) | 0 |
| (0.0, 45.0) | (0.0, 22.5) | (22.5, 45.0) | 1 |
| (22.5, 45.0) | (22.5, 33.75) | (33.75, 45.0) | 1 |
| (33.75, 45.0) | (33.75, 39.375) | (39.375, 45.0) | 1 |
| (39.375, 45.0) | (39.375, 42.1875) | (42.1875, 45.0) | 0 |
| (39.375, 42.1875) | (39.375, 40.7812) | (40.7812, 42.1875) | 0 |
| (39.375, 40.7812) | (39.375, 40.0781) | (40.0781, 40.7812) | 0 |
| (39.375, 40.0781) | (39.375, 39.7265) | (39.7265, 40.0781) | 1 |
| (39.7265, 40.0781) | (39.7265, 39.9023) | (39.9023, 40.0781) | 1 |
| (39.9023, 40.0781) | (39.9023, 39.9902) | (39.9902, 40.0781) | 0 |
| (39.9023, 39.9902) | (39.9023, 39.9462) | (39.9462, 39.9902) | 0 |
| (39.9023, 39.9462) | (39.9023, 39.9243) | (39.9243, 39.9462) | 0 |
| (39.9023, 39.9243) | (39.9023, 39.9133) | (39.9133, 39.9243) | 1 |
| (39.9133, 39.9243) | (39.9133, 39.9188) | (39.9188, 39.9243) | 1 |
| (39.9188, 39.9243) | (39.9188, 39.9215) | (39.9215, 39.9243) | 1 |
经度也用同样的算法,对(-180, 180)依次细分,得到116.3906的编码为1101 0010 1100 0100 0100。
| 经度范围 | 划分区间0 | 划分区间1 | 116.3906所属区间 |
| (-180, 180) | (-180, 0.0) | (0.0, 180) | 1 |
| (0.0, 180) | (0.0, 90.0) | (90.0, 180) | 1 |
| (90.0, 180) | (90.0, 135.0) | (135.0, 180) | 0 |
| (90.0, 135.0) | (90.0, 112.5) | (112.5, 135.0) | 1 |
| (112.5, 135.0) | (112.5, 123.75) | (123.75, 135.0) | 0 |
| (112.5, 123.75) | (112.5, 118.125) | (118.125, 123.75) | 0 |
| (112.5, 118.125) | (112.5, 115.312) | (115.312, 118.125) | 1 |
| (115.312, 118.125) | (115.312, 116.718) | (116.718, 118.125) | 0 |
| (115.312, 116.718) | (115.312, 116.015) | (116.015, 116.718) | 1 |
| (116.015, 116.718) | (116.015, 116.367) | (116.367, 116.718) | 1 |
| (116.367, 116.718) | (116.367, 116.542) | (116.542, 116.718) | 0 |
| (116.367, 116.542) | (116.367, 116.455) | (116.455, 116.542) | 0 |
| (116.367, 116.455) | (116.367, 116.411) | (116.411, 116.455) | 0 |
| (116.367, 116.411) | (116.367, 116.389) | (116.389, 116.411) | 1 |
| (116.389, 116.411) | (116.389, 116.400) | (116.400, 116.411) | 0 |
| (116.389, 116.400) | (116.389, 116.394) | (116.394, 116.400) | 0 |
接下来将经度和纬度的编码合并,奇数位是纬度,偶数位是经度,得到编码 11100 11101 00100 01111 00000 01101 01011 00001。
最后,用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码,得到(39.92324, 116.3906)的编码为wx4g0ec1。
| 十进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| base32 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | b | c | d | e | f | g |
| 十进制 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 |
| base32 | h | j | k | m | n | p | q | r | s | t | u | v | w | x | y | z |
解码算法与编码算法相反,先进行base32解码,然后分离出经纬度,最后根据二进制编码对经纬度范围进行细分即可,这里不再赘述。 不过由于geohash表示的是区间,编码越长越精确,但不可能解码出完全一致的地址。
geohash的应用:附近地址搜索
geohash的最大用途就是附近地址搜索了。不过,从geohash的编码算法中可以看出它的一个缺点:位于格子边界两侧的两点, 虽然十分接近,但编码会完全不同。实际应用中,可以同时搜索当前格子周围的8个格子,即可解决这个问题。
以geohash的python库为例,相关的geohash操作如下:
>>> import geohash >>> geohash.encode(39.92324, 116.3906, 5) # 编码,5表示编码长度 'wx4g0' >>> geohash.expand('wx4g0') # 求wx4g0格子及周围8个格子的编码 ['wx4ep', 'wx4g1', 'wx4er', 'wx4g2', 'wx4g3', 'wx4dz', 'wx4fb', 'wx4fc', 'wx4g0']
最后,我们来看看本文开头提出的两个问题:速度慢,缓存命中率低。使用geohash查询附近地点,用的是字符串前缀匹配:
SELECT * FROM place WHERE geohash LIKE 'wx4g0%';
而前缀匹配可以利用geohash列上的索引,因此查询速度不会太慢。另外,即使用户坐标发生微小的变化, 也能编码成相同的geohash,这就保证了每次执行相同的SQL语句,使得缓存命中率大大提高。
相关资源
- python-geohash: http://code.google.com/p/python-geohash/
- geohash演示: http://openlocation.org/geohash/geohash-js/
| « 2026年06月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
日志分类
- PHP [666]
- python [9]
- Go [38]
- Flutter [14]
- lua [2]
- Scala & Ruby [12]
- Javascript [307]
- PHP Framework [65]
- Linux [289]
- 苹果相关 [229]
- DataBase [161]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [981]
- Baby [92]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- 前几年 lnmp.org 被收购,搞了一波投毒之后,我对这种一键...
06-03 - imlonghao - 这是默认主题啊,怎么分享
10-18 - gouki - 请问这个主题可以分享一下么 谢谢
10-14 - NN - 大佬你好,在用dcat 遇到 怎么做无感刷新的问题,请问你有做过...
02-01 - uc5bbl8s - 好用!!
07-14 - 口水
博客信息
- 分类数量: 17
- 文章数量: 3152
- 评论数量: 1906
- 标签数量: 2283
- 附件数量: 941
- 注册用户: 56
- 今日访问: 32468
- 总访问量: 74845555
- 程序版本: 1.6
