Submitted by gouki on 2009, October 30, 11:46 AM
爱别摸终于咔嚓了。还好,不是电脑,是电源
先是前两天说电池需要召回,去了维修点,他说俺的电脑不属保修范围之内,郁闷,然后我告诉他,我通过软件检查下来是属于召回范围的呀。
他很潇洒说,我这块电池不是在国内经销的机器上的,所以不予保修和召回。我说我在淘宝上买的,他说,那你有保修卡没?一下子傻掉了。。。
看来,以后在淘宝买所谓的行货一定要备保修卡。否则,和买水货没区别啊
以上是一,第二呢,是我的电源线。
可怜的电源线,终于又坏了,为什么要说又呢?那是因为在今年3月份左右,电源线烧了一次,如今刚过半年又烧了。每半年一次啊。
可能是因为我电源线经常折叠弯曲导致的吧,但是,笔记本电源线总要是折叠弯曲的吧,如果这样都不行,那还叫个毛笔记本啊。
等候换线+电源
Tags: ibm
Misc | 评论:0
| 阅读:19950
Submitted by gouki on 2009, October 29, 10:43 AM
Nio在http://www.nioxiao.com/archives/949里说到,php的CURL库生成cookie文件时,应当及时清除,否则会发生意料不到的事情
对于php的curl,我想,在我的博客上有一篇介绍校内狗狗的文章,是yhustc写的。他就用到了这个cookie文件。主要是phpcurl在访问时,会把当前的cookie全部写到这个文件里。如果是个人使用,当然是没问题。如果要提供服务给别人,估计就会发现cookie文件不停的写,而且内容都不一样【估计这就是nio遇到的问题吧】
bopo则改进了yhustc的http类,他用的是tmpnam函数,生成一个唯一的,不同的文件。只要在进程内。文件都不会变啦。呵呵
我当初是判断用户登录,每个用户分配一个cookie文件,保证不会和其他人产生冲突。。。HOHO
但看看Nio说的最后一句话,又不太像,他说:
http://www.nioxiao.com/archives/949
- 特别需要注意的是,在完成抓取之后,需要把 cookie 文件删除,否则下次抓取时会自动使用原有的 cookie 数据,从而导致一些预想不到的错误(我们今天就被这个问题折腾了很久 :( )。
但,好象每次访问都会生成新的cookie内容的吧?除非确实需要清空?这个问题,我是没有遇到过,暂时先记录一下。。
PHP | 评论:1
| 阅读:27618
Submitted by gouki on 2009, October 28, 11:38 AM
有些东西是我们在做网页的时候需要注意的,虽然,不太常用到,但稍注意一下,可能会减轻服务器很多压力 ,以下就是一篇小技巧的文章,了解了这些知识,会给你的WEB网站减轻一些IO的消耗吧。
内容如下:
网页的缓存是由HTTP消息头中的“Cache-control”来控制的,常见的取值有private、no-cache、max-age、must-revalidate等,默认为private。其作用根据不同的重新浏览方式分为以下几种情况:
(1) 打开新窗口
如果指定cache-control的值为private、no-cache、must-revalidate,那么打开新窗口访问时都会重新访问服务器。而如果指定了max-age值,那么在此值内的时间里就不会重新访问服务器,例如:
Cache-control: max-age=5
表示当访问此网页后的5秒内再次访问不会去服务器
(2) 在地址栏回车
如果值为private或must-revalidate(和网上说的不一样),则只有第一次访问时会访问服务器,以后就不再访问。如果值为no-cache,那么每次都会访问。如果值为max-age,则在过期之前不会重复访问。
(3) 按后退按扭
如果值为private、must-revalidate、max-age,则不会重访问,而如果为no-cache,则每次都重复访问
(4) 按刷新按扭
无论为何值,都会重复访问
当指定Cache-control值为“no-cache”时,访问此页面不会在Internet临时文章夹留下页面备份。
另外,通过指定“Expires”值也会影响到缓存。例如,指定Expires值为一个早已过去的时间,那么访问此网时若重复在地址栏按回车,那么每次都会重复访问:
Expires: Fri, 31 Dec 1999 16:00:00 GMT
在ASP中,可以通过Response对象的Expires、ExpiresAbsolute属性控制Expires值;通过Response对象的CacheControl属性控制Cache-control的值,例如:
Response.ExpiresAbsolute = #2000-1-1# ' 指定绝对的过期时间,这个时间用的是服务器当地时间,会被自动转换为GMT时间
Response.Expires = 20 ' 指定相对的过期时间,以分钟为单位,表示从当前时间起过多少分钟过期。
Response.CacheControl = "no-cache"
Expires值是可以通过在Internet临时文件夹中查看临时文件的属性看到的,如:
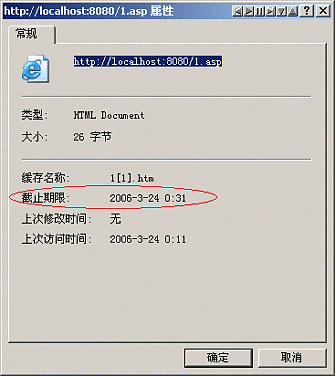
- 出处:http://kaima.cnblogs.com
- 作者:kai.ma
Javascript | 评论:0
| 阅读:21544
Submitted by gouki on 2009, October 28, 12:30 AM
韩寒一直很风骚,从最初的特招到出书,然后成为赛车手,再然后,继小徐之后成为新浪知名博客之一。独领风骚一阵子。。
他还挺会复制,他说,这是陈毅写的诗,题目是《七古·手莫伸》,内容为:
七古·手莫伸
- 手莫伸,伸手必被捉。党和人民在监督,万目睽睽难逃脱。汝言惧捉手不伸,他道不伸能自觉,其实想伸不敢伸,人民咫尺手自缩。岂不爱权位,权位高高耸山岳。岂不爱粉黛,爱河饮尽犹饥渴。岂不爱推戴,颂歌盈耳神仙乐。第一想到不忘本,来自人民莫作恶。第二想到党培养,无党岂能有所作?第三想到衣食住,若无人民岂能活?第四想到虽有功,岂无过失应惭怍。吁嗟乎,九牛一毫莫自夸,骄傲自满必翻车。历览古今多少事,成由谦逊败由奢。
他又说,严禁公务员在一张桌子上吃饭
这是什么?还是看:http://blog.sina.com.cn/s/blog_4701280b0100fk2m.html
对了,听说孙中界同学已经在新浪进驻了。估计又是一知名博客的候选分子。。。刚发表的感谢信,已经阅读将近10万了。啥感谢信,那得看:http://blog.sina.com.cn/s/blog_62bbbcbd0100fmgq.html?tj=1
Tags: 韩寒, 倒钩
Misc | 评论:0
| 阅读:19231
Submitted by gouki on 2009, October 27, 8:24 PM
这是一篇05年的文章,当然更不可能是我写的。我没有这么深的内涵,但,偶尔我也可以发发牢骚,在转贴完后,我也会写上一点自己的理解。
原文:
偶尔去 Linuxforum 看了看,一片荒凉。想想前几年,Linuxforum 可以说是一些 Linux 爱好者相当喜欢的站点阿。可是几年过去了,不进则退。作为早期的论坛+门户齐全的技术站,在Linux刚在中国引起人注意的时候,的确引起很多人的注意。 但是眼看着别的技术站点都在做着“丰富门户,加强论坛功能”这样的动作的时候,Linuxforum 居然无动于衷。看看那个论坛,还是几年前的那个样子,功能和亲和力与现在的一些成熟的论坛软件(比如phpbb,VBB等)相去甚远,用户界面也不够友 好,甚至对用户不够友好--注册之后居然不可以立刻发帖。这无疑给那些急于提问题的 Linux 爱好者一个闭门羹。
首页的最重要的地方居然放了几则公告,经常一放就是几个月。自从2002年之后,Linuxforum 似乎很少有什么改进,不知道老邓怎么想的呀。这样的站点怎么打造成“最具亲和力的,最具活力的Linux爱好者社区”?我看很难。
另一个例子是 CNOUG,自从http://www.cnoug.org 和 http://www.oracle.com.cn 合并之后,并没有想象中的“一跃成为国内最大的 Oracle 爱好者技术站点”,然后人气逐渐下滑,门前冷落,是不争的事实。
从我个人的角度上看, CNOUG 的弊端可能有以下几点:
- 论坛界面不具有亲和力,过于花哨。甚至在界面中大量的使用 comic sans ms 这样不适合Web界面的字体,敗笔!
- 对搜索引擎不够友好。有的技术站点,比如 ChinaUnix,比如 ITPub,都已经完成了从动态=>静态页面的转换。从而吸引了更多的潜在访问用户。
- 没有内容门户。门户对于一个提供技术的站点来说作用还是很大的,可以及时方便的展示给用户最有价值的信息。不用则是一种浪费。
- "专而精"到"博而杂"的转换失败。
一个站点成功的因素可能有很多,但是一个很重要的因素就是对用户的友好程度。用户来到你的站点可能只想得到他(她)想要的相关信息而已。
文章链接:http://www.dbanotes.net/review/post_6.html,作者为Fenng,看文章的地址链接,就知道这篇文章对于该博客来说是多么早了。
对于站点有没有吸引力,其实我也想说说,很早以前,自己也做过一些论坛、资讯之类的网站,但很快【一年或两年】自己的目标就转移到新的方向去了,原来的东西就几乎全部被放弃,论坛也不太维护了,资讯也不更新了。慢慢的人也就越来越少了。是啊,你站长都不专心,别人怎么会在意呢?论坛也就这样的被关掉,资讯嘛。。看http://phpoo.com就知道了。。。再往 下,估计phpoo.com就成了我收集资料的网站了,呵呵
突然想起老毛说的一句话:做一件好事并不难,难的是一辈子做好事。做网站也一样啊,做一个好网站其实并不难,难的是,你把它坚持下去。。。
还好,我的博客还活着,我总不会放弃它的。。52cd.net的关闭只是因为备案的关系,会开通的。我有很多东西等着发布呢。。
Tags: 人气
Misc | 评论:4
| 阅读:15161


