Onenote是我在WIN下用的最多的一个程序之一,嗯,Office里面就这一个软件我最喜欢了。为了它,我买了个所谓的正版的Office。然而,在MAC下是无法使用的,这个,你懂的。
看到36氪上的这个新闻的时候,很是欣慰,原来微软哥没有忘记我们,没有抛弃我们,虽然这仅仅只是一个简单的版本,而且是基于skydrive的,但总算有了一个开头了。
先看新闻:
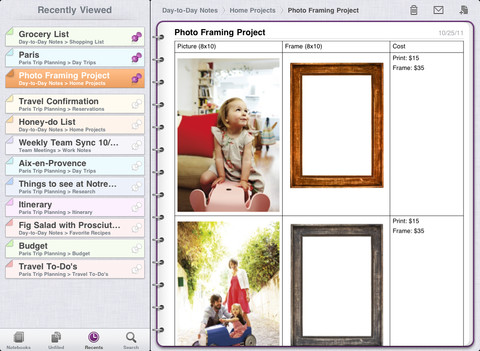
微软刚刚升级了iOS上的OneNote应用到1.3版本,新版将支持任何运行iOS 4.3或以上系统的设备,包括iPad和iPad 2。
除了开始支持新的设备,iPad版本的OneNote还充分利用了平板电脑的大屏幕优势,在使用地图、侧边栏菜单以及其他iPad专有功能时更加适合。
OneNote在2003年第一次随微软Office套件一起发布,今年1月份时候移植到了iPhone上,作为Office套件的一部分,它是唯一一个可以在iOS设备上使用的Office应用,OneNote使用微软的SkyDrive云服务自动跨设备同步笔记。
尽管OneNote应用本身免费,但是用户的笔记数被限制在500以内,超过500后则需要付费,iPhone和iPod Touch用户需要支付4.99美元,iPad用户需要支付14.99美元。如果你在SkyDrive上有超过500条笔记,你仍然可以在你的iOS设备上查看它们,不过微软说,你不能够编辑这些笔记或新建笔记。
不知道微软扩展OneNote支持iPad是意味着要将更多Office应用带到iOS设备上?我们拭目以待。
原文来自:http://www.36kr.com/p/68055.html
----------
静候mac版本,那样我就真的可以完全脱离windows了(除了玩游戏。NND,arclive没法玩,CS没法玩,真纠结)

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
转:微软升级iPhone应用OneNote,开始支持iPad
Submitted by gouki on 2011, December 13, 9:39 PM. Flutter
本站采用创作共享版权协议, 要求署名、非商业和保持一致. 本站欢迎任何非商业应用的转载, 但须注明出自"易栈网-膘叔", 保留原始链接, 此外还必须标注原文标题和链接.
只显示10条记录相关文章
如何在微信里关闭窗口 (浏览: 34137, 评论: 0)
子域和根域同名cookie的处理 (浏览: 32018, 评论: 1)
Ipad 新装两个软件:goodreader 和 pdf reader (浏览: 29233, 评论: 0)
写在NetBeans IDE 6.9.1 发布时 (浏览: 27273, 评论: 0)
ipad 越狱第一步:备份数据 (浏览: 25678, 评论: 6)
webmatrix,微软你想干嘛 ? (浏览: 25529, 评论: 0)
好文推荐:五款常用mysql slow log分析工具的比较 (浏览: 25307, 评论: 2)
Nginx针对IP和目录限速 (浏览: 25104, 评论: 0)
GreaseMonkey with jQuery (浏览: 23529, 评论: 0)
Mysql: 'reading initial communication packet' (浏览: 23151, 评论: 0)
子域和根域同名cookie的处理 (浏览: 32018, 评论: 1)
Ipad 新装两个软件:goodreader 和 pdf reader (浏览: 29233, 评论: 0)
写在NetBeans IDE 6.9.1 发布时 (浏览: 27273, 评论: 0)
ipad 越狱第一步:备份数据 (浏览: 25678, 评论: 6)
webmatrix,微软你想干嘛 ? (浏览: 25529, 评论: 0)
好文推荐:五款常用mysql slow log分析工具的比较 (浏览: 25307, 评论: 2)
Nginx针对IP和目录限速 (浏览: 25104, 评论: 0)
GreaseMonkey with jQuery (浏览: 23529, 评论: 0)
Mysql: 'reading initial communication packet' (浏览: 23151, 评论: 0)
1条记录访客评论
膘叔的专业是不容置疑的
Post by 通化在线 on 2011, December 11, 12:29 AM  #1
#1
发表评论
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [668]
- python [0]
- Go [9]
- Flutter [227]
- lua [0]
- Scala & Ruby [92]
- Javascript [307]
- PHP Framework [65]
- Linux [5]
- 苹果相关 [286]
- DataBase [0]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [981]
- Baby [161]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- 前几年 lnmp.org 被收购,搞了一波投毒之后,我对这种一键...
06-03 - imlonghao - 这是默认主题啊,怎么分享
10-18 - gouki - 请问这个主题可以分享一下么 谢谢
10-14 - NN - 大佬你好,在用dcat 遇到 怎么做无感刷新的问题,请问你有做过...
02-01 - uc5bbl8s - 好用!!
07-14 - 口水
博客信息
- 分类数量: 17
- 文章数量: 3152
- 评论数量: 1906
- 标签数量: 2284
- 附件数量: 941
- 注册用户: 56
- 今日访问: 21888
- 总访问量: 75176952
- 程序版本: 1.6
