说实话,我真的想买车了。
上班,没车,天天挤公交又特别累。晚上回家吧,还是乘地铁。那叫一个累啊。。。
如果有了车,那上下班可以轻松很多了。所以,我就想买辆车,这样,平时或许也会方便很多
可是,相对的,问题也有一些啊:
你想想,去远的地方吧。没车真不方便 。
去近的地方吧。开车又不值得。
只是,没有车库,不方便停车。出门吧,又到处找不到一个好的停车位。
不过,想想,还是忍了。。。
这些都不是什么大问题啊。实在不行,咱还可以忍忍不开的嘛。
嗯,决定了,买,分期付款,没啥买不起的。不就是贷点款嘛。。。
各位,帮忙想个建议啥的,你说,我是买国产的永久、凤凰好还是买国外的GIANT之类的呢?这些车的优劣谁能给个评测?现在的车网、论坛啥的,这类评测都很少见啊。
关于“谷鸽鸟看”计划
2009年4月1日, 总部位于美国加州山寨城(Mountain Village)的谷歌公司正式推出“谷鸽鸟看”计划。 该计划旨在利用装备了 CADIE 芯片和软体, 并被赋予了超智能信息处理能力的“谷鸽”, 动态采集、整理和分享山寨信息,打造全球最大的山寨信息网。 简言之,“谷鸽鸟看”计划的使命是:
鸟看全球信息,使人人皆可山寨并从中受益!
什么是“谷鸽鸟看”技术?

谷歌为专门训练的 31415926 只谷鸽装备了以 CADIE 计算技术为支撑的四大高科技系统:
- 智能导航帽:在鸽子头脑清醒的时候提供 0.01 米精度全球定位导航信息, 并在鸽子头昏脑胀的时候使用绿色纳米微波为鸽子进行泰式头部按摩。
- 信息处理肚兜:纯棉工艺,不仅仅为了保暖, 同时也是 CADIE 谷鸽版芯片和软体的运行平台。
- 无线充电脚环:当谷鸽飞临专用太阳能充电站时, 脚环在五分钟内以无线方式为谷鸽充满 16 小时工作电力。
- 呼叫应答器:支持 2G/3G 网络协议,响应用户召唤, 真正实现“思想有多远,山寨就有多远”的山寨主义理想。
类似谷歌街景(Street View) 采集技术,谷歌倾心打造的超智能谷鸽被赋予外出采集山寨信息的重要使命。 这一方面可以大幅提高谷歌地球(Google Earth) 和谷歌地图(Google Maps)的图像分辨率, 另一方面也可以弥补网页搜索中山寨信息含量明显偏低的缺憾, 实现搜索山寨化,山寨信息化,信息无废话。
天涯何处不山寨,就看谁的动作快! 利用飞得高、看得远、耳朵灵、眼睛贼等特点, 谷鸽将重点采集以下山寨信息:
- 最具有震撼力的山寨新闻:例如,湖南某烟花厂最新研制成功无污染、无燃烧、无烟尘, 适于在所有完工或未完工高层建筑安全燃放的绿色版山寨烟花的新闻。
- 最有潜质的山寨明星:包括,上不了春晚一级的舞台,但有潜力成为网络人气偶像的型男、靓女; 不懂得炒作,但却充满娱乐气质的宅男、宅女;没有出众外表,但有满腹心事的痴男、怨女……
- 最适合山寨恋人约会的时间地点:例如,2月14日晚,多情谷下、断肠崖边的爱情烧饼屋。
- 最有创意的山寨发明、创造:例如, 能够从谷鸽音乐搜索中迅速找到可调解家庭矛盾、平息地区争端的“和平音乐编织机”。
- 最有魅力的山寨流行语:类似2008年出现的“叉腰肌”、“囧”、 “谷鸽”等充满山寨活力的流行网络新词。
由“谷鸽鸟看”技术采集的所有山寨信息将被 CADIE 集中处理并发布在谷鸽山寨搜索引擎上。 新一代山寨搜索引擎将能够覆盖全球每个角落、每一时刻、每一种类型的山寨信息。 网友可以使用谷歌地图提供的谷鸽飞行路线图功能查看谷鸽的飞行路线。

返回页首
如何召唤谷鸽?
除谷鸽自动外出寻找山寨信息外,用户也可以主动召唤谷鸽采集身边的山寨信息。召唤方法如下:
- 走到户外或楼顶超过20平方米的空地
- 用支持上网功能的手机打开谷歌移动版http://g.cn/
- 对着手机屏幕上出现的麦克风图标,使用鸽子的方法,“咕——咕——咕——”大叫三声
- 耐心等待……
不出意外的话,谷鸽会在三十分钟内出现在您的身边。 根据不完全统计,排除软件 Bug 和芯片抽风等影响因素, 谷鸽响应召唤者的平均时间间隔是 21.04 分钟,响应成功率为 99.5865%。
返回页首
如何保护隐私?
谷歌承诺,谷鸽只飞越公共区域,并只能像普通鸽子一样感知鸟类可感知的事物 (想像一下你自己被装上翅膀,在天上飞翔时所能看到和听到的一切)。如果你不想谷鸽打扰你, 可以从以下网址下载“谷鸽别烦我”的折纸挂件图样,自行制作后, 站在窗前,一旦看到谷鸽,就高高挥舞“谷鸽别烦我”的折纸。祝你好运!

返回页首
什么是“绿色谷鸽”计划?
谷歌计划在全国范围修建 271828 座由 CADIE 技术提供支持的太阳能充电站。 “谷鸽太阳能充电站”同时支持无线和有线两种充电模式, 不但可以为佩戴“无线充电脚环”的谷鸽提供可持续能源, 还可以为其他可充电电器设备提供服务。 未来,经过谷鸽计划的充分检验后,这批充电站将投入民用, 为手机、电动汽车、油电混合动力汽车、电动自行车等民用设备提供充电服务。
目前,谷歌正在与英国科学家积极合作,研发第二代能源供应设备——“鸽能发电”。 这将是一种完全依靠谷鸽翅膀振动获得电力,并完全自给自足的供电模式。
未来,绿色、清洁、无污染的“鸽能发电”技术, 及其推广版本如“狗能发电”、“马能发电”、 “麻雀能发电”等等,有望部分取代高污染、高能耗的火力发电技术, 成为全球绿色能源体系的重要组成部分。
Only a joke,愚人节,谷歌的玩笑还是挺有创意,详细请看:http://www.google.cn/intl/zh-CN/google_pigeon/index.html
自从阿朱的那本《三五个人七八条枪,如何走出软件作坊》热卖后,很多有类似经验的人也开始逐步把自己的项目管理经验放出来与大家共享了,或许风格各有不同,但事实上都是为了解决相同的问题。
阿朱因为是做了多年的项目管理,而且从文章看来,他在初期也是一个牛B的coder,然后一步一步的走到今天。
或许这也为那些coder们指明了一个小方向 ?
《项目那点事》是我在博客园上看到的一篇文章,内容还是算诙谐风趣,还没有仔细看完,但好象就是从某一个项目说起,个人以为,该文章可能出不了书。呵呵,随便猜测是不对的
有兴趣的朋友可以去:http://www.cnblogs.com/Pegasus_cc/ 查看一下
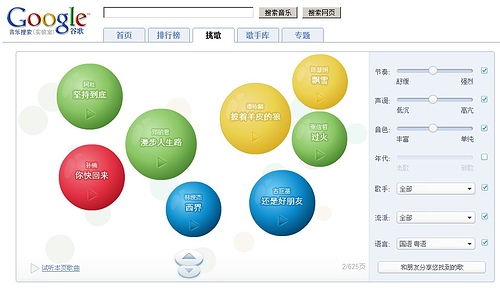
在google reader里闲逛的时候,看到了这个介绍,看界面,如果加上连线的话,就有点象微软那个“人立方”网站了。去了谷歌的网站,并尝试着根据上面的条件搜索了一下,发觉使用起来还是很方便的.
点击试听后会去一个top100.cn的网站,同样是采用了flash,估计是为了播放器可以兼容任何浏览器吧?还可以下载,只是不知道这些歌的版权如何处理(搞得象自己是FQ一样,装的很清高的样子,哈哈),下载的时候,提示来源是:file1.top100.cn,所以,黑黑。。。。
以下内容来自作者的介绍:http://www.awflasher.com/
我有幸在这个项目中扮演了主力ActionScript开发者和部分交互设计师的角色。
这个项目的交互创意、UI设计主要来自于Eicostudio(2004 年我大三的时候曾经膜拜过工作室创始人之一Rokey大牛的作品,他们都是国内最专业的UI设计师)和Google中国的UX团队。Google中国的 UX团队给予了我极大的帮助,在同Google UX团队的合作中,我能非常清楚地感受到他们每一个人对细节的执着追求和对中文搜索事业的敬业精神,每一个颜色,每一个字体样式,每一个UI组件的使用模 式和位置,都经过反复的斟酌才最终敲定。
同时,项目质量控制上面也要感谢J、M、B、T等谷歌Music团队的工程师的帮助。老实说,我从来没有在一个ActionScript项目中被内存回收折磨得不得不重写一个几千行的类 - 感谢诸位工程师的支持和建议。
具体如何使用我觉得就没必要具体介绍了吧,根据右侧的几个筛选条件进行选择,可以找到你想要的一种特定类型的音乐,十分方便,大家使用起来有什么意见和建议也欢迎在我的Blog留言。
本文来自:http://www.awflasher.com/blog/archives/1738
以下内容来自于淘宝QA的博客,看到的时候自己也很惊讶,感悟于以前的同事,在发现BUG的时候是多么的冷静自若(非并QA,而是某些开发人员),就差再对比一下淘宝的QA,发现差距是多大。
企业越大,就越是会遇到一些问题,当企业还在扩张和发展的时候,部分会员对一些BUG还能够容忍,但是当企业发展到一定规模的时候,会员对于自身所应该拥有的权利就会提到台面上来了。毕竟我花了钱,当然应该享受一些权利,而并不是一直在尽义务。如何能更好的为用户服务才是以后互联网公司要走的路啊。
当然下面的内容我也不知道是否是事实,但我还是很感动。
内容如下:
http://rdc.taobao.com/blog/qa/?p=1187
- 一次系统刚上线,一个卖家旺旺迅速反馈:部分宝贝图片显示不出来了,是不是系统升级的原因?
-
- 我们的开发和测试人员在忙碌的搜集问题,找问题,解决问题…
-
- 这位会员很着急说:310*310的不能显示….不对,是ps处理过的不能显示……
-
- 过了一会,又说道:我们一天更新几百张图片的,今天的工作计划泡汤了…
-
- 听到会员这么说,我感觉很难过,一个bug影响了一个卖家一天的工作…
-
-
-
- 我开始思索,平时自己工作过程中,如果电脑出了什么问题,自己也会急的像热锅的蚂蚁的.我想这位会员的感觉也是一样的.
-
- 当我们的系统越做越大,复杂度越来越高,对我们的要求也越来越高.我们应该跟会员一样,把系统看作我们赖以生存的工具,不能一次又一次把这种伤痛留给会员.
-
- 期待哪一天,我们系统升级后,会员只有快乐,没有阵痛……我们还需要继续做出很大的努力~~~