之所以再写一次,是因为看到了IBM上的一篇文章,时间也比较早,我在以前也写过一篇简单的文章来进行介绍,不过这篇IBM的写的比较全,而且我以前的写的也仅仅是评论,并没有就COMET的技术进行详细的介绍。
IBM上是这样说的,这只是简单的摘录一段,详细的还是到该页面去看吧,因为IBM的页面说明了有版权限制,而如果要申请复制文章的话,又比较复杂和繁琐,因此,只能这样了:
http://www.ibm.com/developerworks/cn/web/wa-lo-comet/
- 传统模式的 Web 系统以客户端发出请求、服务器端响应的方式工作。这种方式并不能满足很多现实应用的需求,譬如:
-
- * 监控系统:后台硬件热插拔、LED、温度、电压发生变化;
- * 即时通信系统:其它用户登录、发送信息;
- * 即时报价系统:后台数据库内容发生变化;
-
- 这些应用都需要服务器能实时地将更新的信息传送到客户端,而无须客户端发出请求。“服务器推”技术在现实应用中有一些解决方案,本文将这些解决方案分为两类:一类需要在浏览器端安装插件,基于套接口传送信息,或是使用 RMI、CORBA 进行远程调用;而另一类则无须浏览器安装任何插件、基于 HTTP 长连接。
-
- 将“服务器推”应用在 Web 程序中,首先考虑的是如何在功能有限的浏览器端接收、处理信息:
-
- 1. 客户端如何接收、处理信息,是否需要使用套接口或是使用远程调用。客户端呈现给用户的是 HTML 页面还是 Java applet 或 Flash 窗口。如果使用套接口和远程调用,怎么和 JavaScript 结合修改 HTML 的显示。
- 2. 客户与服务器端通信的信息格式,采取怎样的出错处理机制。
- 3. 客户端是否需要支持不同类型的浏览器如 IE、Firefox,是否需要同时支持 Windows 和 Linux 平台。
jquery 1.3刚刚出来没几天,shawphy的中文API就基本出炉了,有时候真的挺佩服他们,当我们在娱乐的时候,他们还在努力的为我们这些人造福。我没有什么其他能力,只能做到代为传播了。同时也是希望有更多的人参与,可以让我们这些使用者也能够更加方便。
网址:http://shawphy.com/2009/01/release-jquery-doc-cn-1-3.html
原文如下:
jQuery 1.3自从2008年1月14日发布后,后引来了各界的关注。我们也随即投入到翻译文档的工作中来。经过4天的努力,终于完工了。这个版本更新了不少东西
changelog:
2009-01-18 16:06:52 +0800
* triggerHandler 进一步说明
* trigger 进一步说明
2009-01-17 22:37:11 +0800
* live() - 与bind()不同的是,live()一次只能绑定一个事件。
* [attribute!=value] jQuery 1.3中意义改变
* load 的data参数在jQuery 1.3中也可以接受String
+ ajax的error回调的第二个参数可能值”timeout”, “error”, “notmodified” 和 “parsererror”
+ ajax参数xhr
* animate 的duration为0的问题
* show, hide, toggle, slideDown, slideUp, slideToggle 在jQuery 1.3中,padding和margin也会有动画,效果更流畅。
* jQuery(html,[ownerDocument])等效于$(document.createElement(”span”)
* is支持复杂表达式
2009-01-17 18:31:10 +0800
+ jQuery.support.scriptEval
+ 原 Dimension 插件功能(1.2.6版加入jQuery核心)
2009-01-16 19:11:10 +0800
+ jQuery.fx.off
+ toggleClass( class, switch )
+ toggle( switch )
+ toggle(speed,[callback])
* 修改queue和dequeue方法的参数和说明
2009-01-15 22:31:02 +0800
* jQuery(html,[ownerDocument])
+ jQuery.selector
+ jQuery.context
* 效果下的queue和dequeue搬到核心下
+ live()
+ die()
+ closest()
* stop( [clearQueue], [gotoEnd]) 增加两个参数
+ jQuery.support
+ jQuery.isArray( obj )
感谢Cloudream的热情帮忙。还要感谢一揪制作chm版。这个版本还加入了检查更新的功能。如果有需要的同学可轻松查看是否有更新的中文文档(chm版中的检查更新也将同步升级)。
在线查看 下载离线版 bug提交
Something from jQuery's Blog :
Happy Birthday to jQuery! jQuery is three years old today, after being released way back on January 14th, 2006 at the first BarCampNYC by John Resig.
We have four announcements for you today, we hope you’ll enjoy them!
Url:http://blog.jquery.com/2009/01/14/jquery-13-and-the-jquery-foundation/
中文翻译:http://shawphy.com/2009/01/release-jquery-1-3.html
jQuery 1.3终于发布了。
min版(gzip后18kb)
源码(114kb)
另外可以用google的代码托管:
http://ajax.googleapis.com/ajax/libs/jquery/1.3/jquery.min.js
下面这个是我自己用Packer压缩的pack版
http://shawphy.com/down/jquery-1.3.pack.js(37kb)
简要来说:
更新了Sizzle选择器引擎,这个之前也提到过。可以查看他的性能:
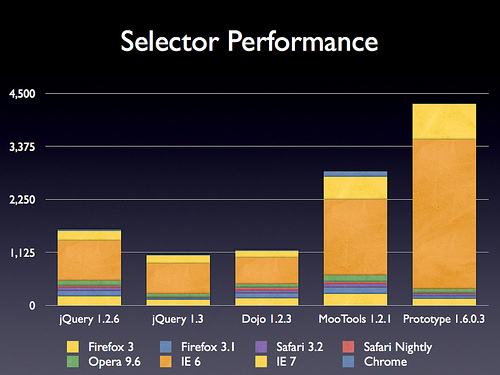
此外据声称,把代码给了dojo基金会。这回Sizzle的野心在于能够让其他各种JS库都能用,包括Prototype, Dojo, Yahoo UI, MochiKit, 和 TinyMCE等等其他库。
live 事件
这也是jQuery 1.3这次更新的第二个重大更新。(注:这里有一个iframe,我没有复制过来,请到原站观赏和测试)
性能比较:
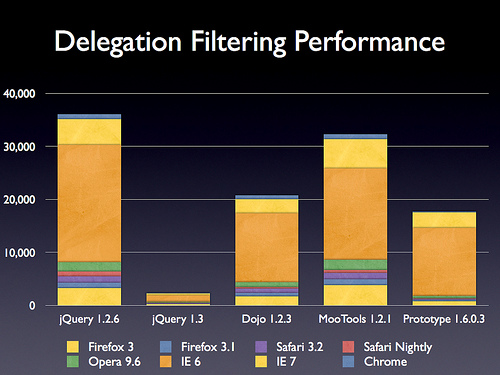
这样,我以前写的关于重复绑定的文章就差不多可以抛弃了
Event 对象
新增了一个jQuery.Event对象,他根据w3c文档,做了一个完整的,兼容所有浏览器的一个对象。具体还得看文档。
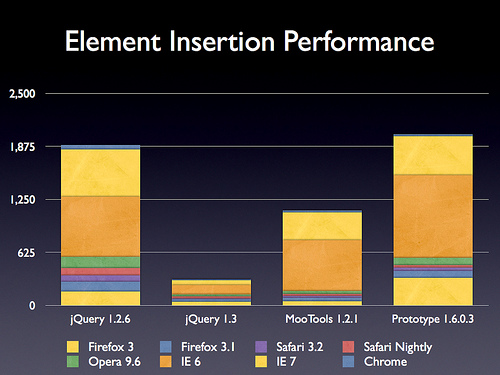
append, prepend, before, 和 after 方法重写
据声称,这些方法的效率提升了6倍
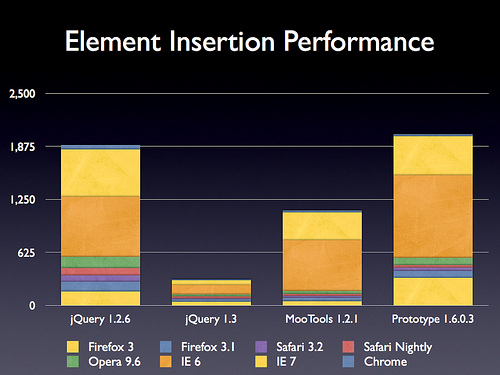
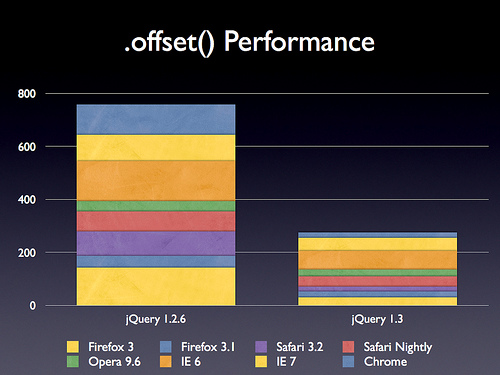
重写了offset方法
这回更快了
取消了浏览器侦测,全面改用jQuery.support
具体还得看文档了。
变化:
其中与开发者比较密切的是
[@attr] 中的@在1.3里不能用了
用trigger触发的事件现在能冒泡了
ready方法中,再也不等css加载完了再执行其中代码了。直接要求把css放在脚本之前就行
简化了.isFunction方法,那些偏门的就被无视了
用选择器a, b, c选择东西,在支持querySelectorAll (Safari, Firefox 3.1+, Opera 10+, IE 8+)中会按照这些元素在文档中顺序来确定这些数组在获得的对象列表中的位置。而不支持这个方法的浏览器则按照选择器顺序排好
新增了jQuery.Event
要求网页都在标准模式下,不要在怪异模式下使用,否则会报错。
以下3个方法属性已被不推荐使用。
* jQuery.browser
* jQuery.browser.version
* jQuery.boxModel
具体内容:
内核部分:
更好的queue, dequeue
新增selector, context这两个属性,分别指向获取这个元素的原始选择器和被查找的内容(可选)
选择器部分:
Sizzle的使用
复杂的css例如not(a, b)
属性部分:
toggleClass( “className”, state ) - 增加了一个布朗值的参数。
筛选文档:
.closest( selector ) - 找到离这个元素最近的一个父元素。这跟parents不一样。
is() 也支持更复杂的选择器了。
操作文档:
HTML Injection重写了
$(”<script/>”) 就自动转化为 $(document.createElement(”script”))
css:
offset()重写了
事件:
Live 事件
jQuery.Event
trigger()会冒泡了
效果:
hide() .show()之类的加快速度
内置动画效果考虑到了margin和 padding
.toggle( boolean ) 多提供了一个参数
jQuery.fx.off 关闭所有动画
AJAX:
.load()支持了文本格式的数据
工具:
新增jQuery.isArray
内部:
jQuery.support
另外这回改用YUI的工具压脚本了
========================================
最后预告一下,jQuery文档官网已经针对1.3版做了修改,中文文档也在紧张制作中。
根据官方的博客,说是1月14日前发布release前最后一个版本了。不知道什么时候有的下载和测试,不过仍然是不建议用在项目中,还是等稳定版吧。
那个常见的@终于要消失了。新的引擎效率应该快上很多吧。
关注官方:www.jquery.com