浏览模式: 标准 | 列表分类:Javascript
Submitted by gouki on 2009, October 28, 11:38 AM
有些东西是我们在做网页的时候需要注意的,虽然,不太常用到,但稍注意一下,可能会减轻服务器很多压力 ,以下就是一篇小技巧的文章,了解了这些知识,会给你的WEB网站减轻一些IO的消耗吧。
内容如下:
网页的缓存是由HTTP消息头中的“Cache-control”来控制的,常见的取值有private、no-cache、max-age、must-revalidate等,默认为private。其作用根据不同的重新浏览方式分为以下几种情况:
(1) 打开新窗口
如果指定cache-control的值为private、no-cache、must-revalidate,那么打开新窗口访问时都会重新访问服务器。而如果指定了max-age值,那么在此值内的时间里就不会重新访问服务器,例如:
Cache-control: max-age=5
表示当访问此网页后的5秒内再次访问不会去服务器
(2) 在地址栏回车
如果值为private或must-revalidate(和网上说的不一样),则只有第一次访问时会访问服务器,以后就不再访问。如果值为no-cache,那么每次都会访问。如果值为max-age,则在过期之前不会重复访问。
(3) 按后退按扭
如果值为private、must-revalidate、max-age,则不会重访问,而如果为no-cache,则每次都重复访问
(4) 按刷新按扭
无论为何值,都会重复访问
当指定Cache-control值为“no-cache”时,访问此页面不会在Internet临时文章夹留下页面备份。
另外,通过指定“Expires”值也会影响到缓存。例如,指定Expires值为一个早已过去的时间,那么访问此网时若重复在地址栏按回车,那么每次都会重复访问:
Expires: Fri, 31 Dec 1999 16:00:00 GMT
在ASP中,可以通过Response对象的Expires、ExpiresAbsolute属性控制Expires值;通过Response对象的CacheControl属性控制Cache-control的值,例如:
Response.ExpiresAbsolute = #2000-1-1# ' 指定绝对的过期时间,这个时间用的是服务器当地时间,会被自动转换为GMT时间
Response.Expires = 20 ' 指定相对的过期时间,以分钟为单位,表示从当前时间起过多少分钟过期。
Response.CacheControl = "no-cache"
Expires值是可以通过在Internet临时文件夹中查看临时文件的属性看到的,如:
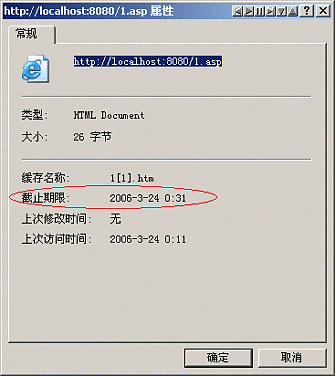
- 出处:http://kaima.cnblogs.com
- 作者:kai.ma
Javascript | 评论:0
| 阅读:21595
Submitted by gouki on 2009, October 15, 9:51 AM
在美拓的BLOG【http://meito.22web.net/?p=51】上面看到这篇文章,先说说我的理解吧。
jQuery的代码中,this是代表了当前对象。例如:$("#test").click(function(){ alert(this.value )});,在这个方法里,如果用了this,那就是相当于直接使用了 test 元素这个对象,有点象document.getElementById("#test")一样【说的我自己都迷糊了。。。】在这个方法中的this,就是ID为test的元素本身
而$(this),则是把这个元素对象重新进行了 jQuery的包装。。。
说的太乱了。。。。直接看美拓的原文吧。
-------原文开始-------------
起初以为this和$(this)就是一模子刻出来。但是我在阅读时,和coding时发现,总不是一回事。
What is “this”?
In many object-oriented programming languages, this (or self) is a keyword which can be used in instance methods to refer to the object on which the currently executing method has been invoked.
JavaScript代码
- $("#textbox").hover(
- function() {
- this.title = "Test";
- },
- fucntion() {
- this.title = "OK”;
- }
- );
这里的this其实是一个Html 元素(textbox),textbox有text属性,所以这样写是完全没有什么问题的。
但是如果将this换成$(this)就不是那回事了,Error–报了。
Error Code:
JavaScript代码
- $("#textbox").hover(
- function() {
- $(this).title = "Test";
- },
- function() {
- $(this).title = "OK";
- }
- );
这里的$(this)是一个JQuery对象,而jQuery对象沒有title 属性,因此这样写是错误的。
JQuery拥有attr()方法可以get/set DOM对象的属性,所以正确的写法应该是这样:
正确的代码:
JavaScript代码
- $("#textbox").hover(
- function() {
- $(this).attr(’title’, ‘Test’);
- },
- function() {
- $(this).attr(’title’, ‘OK’);
- }
- );
使用JQuery的好处是它包裝了各种浏览器版本对DOM对象的操作,因此统一使用$(this)而不再用this应该是比较不错的选择。
---EOF---
看来还是不行啊我。。语言组织能力太差
Tags: jquery
Javascript | 评论:2
| 阅读:24136
Submitted by gouki on 2009, October 12, 12:49 PM
来自司徒正美,比较方便的关键符号替换。
司徒正美认为:
不用多言,这种技术被广泛应用于表单验证,语法高亮和危险字符过滤中。一段话如果很长,如果不想像下面那样替换,我们得想些办法了。
他先给了个简单的例子:
JavaScript代码
- var hash = {
- '<' : '<' ,
'>' : '>',
'…' : '…',
'“' : '“' ,
'”' : '”' ,
'‘' : '‘' ,
'’' : '’' ,
'—' : '—',
'–' : '–'
- };
-
- str = str.
- replace( /&(?!#?\w+;)/g , '&' ).
- replace( /"([^"]*)"/g , '“$1”' ).
- replace( /[<>…“”‘’—–]/g , function ( $0 ) {
- return hash[ $0 ];
- });
并表示:缺陷也很明显,如哈希的键必须是简单的普通字符串,不能是复杂正则,这就是我们不得不分开的原因。replace在老一点的浏览器是不支持function的。为此,我们只好放弃上面最后那个replace方式,替换方统一为普通字符串。
于是,他扩展的String的基类,添加了一个方法:
JavaScript代码
- String.prototype.multiReplace = function ( hash ) {
- var str = this, key;
- for ( key in hash ) {
- if ( Object.prototype.hasOwnProperty.call( hash, key ) ) {
- str = str.replace( new RegExp( key, 'g' ), hash[ key ] );
- }
- }
- return str;
- };
并给出了实现代码:
JavaScript代码
- str = str.multiReplace({
- '&(?!#?\\w+;)' :'&',
'"([^"]*)" : '“$1”',
'<' : '<' ,
'>' : '>',
'…' : '…',
'“' : '“' ,
'”' : '”' ,
'‘' : '‘' ,
'’' : '’' ,
'—' : '—',
'–' : '–'
- });
Look,多简单啊。如果觉得我这里的表示更简单的话,请看原文http://www.cnblogs.com/rubylouvre/archive/2009/10/12/1581094.html
Javascript | 评论:0
| 阅读:19368
Submitted by gouki on 2009, October 11, 10:04 PM
关于这个话题,是因为我一直在用FF,而且也经常在返回页面后,原来的数据还在。。。
平时感觉不出什么,也觉得会挺方便。但是,在作测试的时候,问题就来了。实在不不方便。。。。
所以,
Question
在Firefox等浏览器中,如果你打开一个页面并进行若干操作,例如在文本框进行输入,甚至点击按钮进行Ajax操作更新页面局部,这些操作的结 果都会被缓存下来。在你点击链接离开这个页面后,如果你通过后退按钮回到这个页面,你会发现它仍出于你离开时的状态,而非页面刚刚加载好后的初始状态。在 一些情况下,这样的缓存方式是符合我们预期的;但在另外一些情况下,我们更希望页面恢复到初始状态,或者说让页面从零开始重新加载一边。我们如何才能让浏 览器尊重我们的选择呢?
Answer
如果你只是希望页面不缓存加载后的变更,后退就恢复到最初加载的状态,你只需要一个空白的unload事件就可以了:
window.onunload = function(){};
其中的原理是,Firefox等浏览器会尝试通过“挂起(suspend)”的方式来缓存页面,使得后退能够恢复到页面之前被挂起那一刻的状态。然 而如果unload事件有处理函数,浏览器就认为你可能已经对页面进行了析构处理,这时候页面已经不可能回到正常的交互状态,也就不能以挂起的方式来缓存 页面。
如果我们希望允许浏览器挂起页面,同时又需要知道何时被挂起何时被恢复,那该怎么办呢?我们可以用window对象上的pageshow和 pagehide事件。当页面被挂起并隐藏时,pagehide事件会被触发;当页面被恢复到挂起前状态并显示出来时,pageshow事件会被触发。Firefox从1.5开始就支持这两个事件,Safari最新的nightly build也支持这两个事件。
来源:http://www.cnblogs.com/cathsfz/archive/2009/10/09/1579666.html
Javascript | 评论:1
| 阅读:19164
Submitted by gouki on 2009, October 9, 3:50 PM
不得不说如今的技术发展已经到了一个坎了。
剩下的就是如何把技术转化为经济了
用javascript编写游戏已经不是什么新鲜事,这里要推荐的是用纯javascript编写的windows xp系统中自带的蜘蛛纸牌游戏,兼容IE6-8,firefox,safari,chrome,opera浏览器。
除了分数提交之外,其它的基本与系统中的蜘蛛纸牌一样。大家可以玩玩。 游戏地址:http://carnot.cn/jsspider
这是从:http://www.cnbeta.com/articles/95099.htm来的消息。图片就不截了。反正XP的电脑里应该都有蜘蛛纸牌。。。
Javascript | 评论:0
| 阅读:20008


