虽然在用LINUX,但其实对于它的安全,并不是很了解,所以,看到有这样的文章时,还是会记录一下。
原文:http://item.feedsky.com/~feedsky/phpv/~1232318/202448855/1235221/1/item.html
来自:PHP5研究室
俗称“脚本小鬼”的家伙是属于那种很糟糕的黑客,因为基本上他们中的许多和大多数人都是如此的没有技巧。可以这样说,如果你安装了所有正确的补丁,拥有经 过测试的防火墙,并且在多个级别都激活了先进的入侵检测系统,那么只有在一种情况下你才会被黑,那就是,你太懒了以至没去做该做的事情,例如,安装 BIND的最新补丁。
一不留神而被黑确实让人感到为难,更严重的是某些脚本小鬼还会下载一些众所周知的“root kits”或者流行的刺探工具,这些都占用了你的CPU,存储器,数据和带宽。这些坏人是从那里开始着手的呢?这就要从root kit开始说起。
一个root kit其实就是一个软件包,黑客利用它来提供给自己对你的机器具有root级别的访问权限。一旦这个黑客能够以root的身份访问你的机器,一切都完了。 唯一可以做就是用最快的效率备份你的数据,清理硬盘,然后重新安装操作系统。无论如何,一旦你的机器被某人接管了要想恢复并不是一件轻而易举的事情。
你能信任你的ps命令吗?
找出root kit的首个窍门是运行ps命令。有可能对你来说一切都看来很正常。图示是一个ps命令输出的例子。真正的问题是,“真的一切都正常吗?”黑客常用的一个 诡计就是把ps命令替换掉,而这个替换上的ps将不会显示那些正在你的机器上运行的非法程序。为了测试个,应该检查你的ps文件的大小,它通常位于 /bin/ps。在我们的Linux机器里它大概有60kB。我最近遇到一个被root kit替换的ps程序,这个东西只有大约12kB的大小。
另一个明显的骗局是把root的命令历史记录文件链接到/dev/null。这个命令历史记录文件是用来跟踪和记录一个用户在登录上一台Linux机器 后所用过的命令的。黑客们把你的历史纪录文件重定向到/dev/null的目的在于使你不能看到他们曾经输入过的命令。
你可以通过在 shell提示符下敲入history来访问你的历史记录文件。假如你发现自己正在使用history命令,而它并没有出现在之前使用过的命令列表里,你 要看一看你的~/.bash_history 文件。假如这个文件是空的,就执行一个ls -l ~/.bash_history命令。在你执行了上述的命令后你将看到类似以下的输出:
-rw------- 1 jd jd 13829 Oct 10 17:06 /home/jd/.bash_history
又或者,你可能会看到类似以下的输出:
lrwxrwxrwx 1 jd jd 9 Oct 10 19:40 /home/jd/.bash_history -> /dev/null
假如你看到的是第二种,就表明这个 .bash_history 文件已经被重定向到/dev/null。这是一个致命的信息,现在就立即把你的机器从Internet上断掉,尽可能备份你的数据,并且开始重新安装系统。
寻找未知的用户账号
在你打算对你的Linux机器做一次检测的时候,首先检查是否有未知的用户账号无疑是明智的。在下一次你登录到你的Linux机器时,敲入以下的命令:
grep :x:0: /etc/passwd
只有一行,我再强调一遍,在一个标准的Linux安装里,grep命令应该只返回一行,类似以下:
root:x:0:0:root:/root:/bin/bash
假如在敲入之前的grep命令后你的系统返回的结果不止一行,那可能就有问题了。应该只有一个用户的UID为0,而如果grep命令的返回结果超过一行,那就表示不止一个用户。
认真来说,虽然对于发现黑客行为,以上都是一些很好的基本方法。但这些技巧本身并不能构成足够的安全性,而且其深度和广度和在文章头提到的入侵检测系统比起来也差得远。

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
如何判断你的Linux系统是否被黑
Submitted by gouki on 2009, April 16, 11:18 AM
仍是架构:关于呼叫中心业务系统构架方面的设想
Submitted by gouki on 2009, April 14, 3:17 PM
我也来个前言,架构这东西,研究的人越多,我能够做参考的也就越多,哇哈哈哈。不多说,贴copy来的文章,原文见博客园:http://www.cnblogs.com/micronet-lukey/archive/2009/04/14/1435520.html。
当然这个架构和我们传统意义上的WEB架构不太一样,但我想说的是这些问题还是可以作为一定的参考。比如我们在开发的时候,是直接上SVN还是采用传统的目录共享式开发。现在SVN已经成为很多项目开发所必备工具了,但如果我们在部署的时候采用SVN进行分发代码呢?审核关如何过?
程序员->发送到SVN服务器->SVN分发到测试组->测试组分发到正式机
这是一种解决方法,其实也有点象下文的图片。但实际操作中,当然不太会这样操作。不过也差不多是类似的方法。
让我注意的其实是文章的最后一句话。。。
前言:
目前,公司的呼叫中心程序已经在中国的很多城市运行着。由于受到技术和网络环境的限制,这些呼叫中心程序安装实施完毕后,我们都是采取客户先反映问题,然后我们再安排人员时间进行维护。这种被动的维护机制带了很多问题。
目前存在的问题:
一:客户在描述问题的时候,并不能深入到系统的内部,往往只是描述了一个系统报错的现象。由于公司里已经没有当时的运行环境,在公司内很难做到故障重现,也就很难定位到故障的原因。系统维护和bug修补难度很大。
二:呼叫中心的程序日志都是分散存放的。哪台计算机中的程序报错,就到那台电脑中找出错日志。这个过程必须人工干预。有时候,有些报错内容非常致命,但由于公司不能及时获取到这些信息,导致很多问题就像一颗定时炸弹一样无法及时排除。
三:当公司更新了一个版本后,如果不能到现场维护,只能通过远程或者让客户代劳替换新程序。这种更新机制一旦遇到网络中断,或者客户不配合,将给维护工作带来很大障碍。如果由于需求变更较多,需要经常更新版本, 那么面临的问题将很难解决。
解决的措施:
就第一和第二个问题,可以通过改进目前的日志记录方式来解决。通讯服务器接收客户端程序的错误日志。并且把这些日志内容打包成E_Mail邮件,定时发送到公司指定的邮箱中。
就第三个问题,可以通过自动更新服务来解决。维护人员把最新的软件更新包上传到客户端的通讯服务器中。客户端程序监测到有最新的软件更新包,可以自动更新。
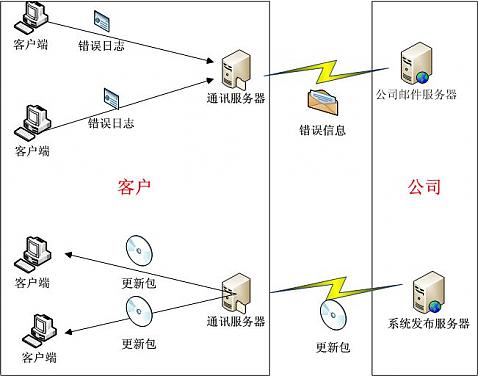
解决问题的核心就是在客户那安装一台通讯服务器。这台通讯服务器既要能能够连接到Internet,同时还要和内部的服务器向连接。这台通讯服务器有两个作用:
1:发送各个程序的错误日志到公司的邮件。
2:接收公司上传的程序更新包,并自动通知各个客户端程序更新。
所有的工作都由服务器自动完成。
总结:
任 何一个系统,在现场部署完成,用户正式开始使用后,对于我们开发组来说,那只是万里长征走完了第一步,后期不断地查错,改进,更新,替换也会占用到大量的 人力物力,如果是外省的客户,跑一趟现场还会占用大量的财力。按照现在的技术能力和网络环境,我们完全可以通过技术手段,更高效地对各个系统进行维护。
维护的最高境界是:客户还没有发现问题,我们已经捕捉到bug并在后台悄悄地把程序更新了。
keepalived?来自Sanotes的PDF
Submitted by gouki on 2009, April 14, 9:09 AM
其实关于这方面我并不了解,昨天在“PHP研讨会议群”里,一直有人在问,但,我确实不了解,于是乎,我没有参与
今天一大早翻开google reader,发现Sanotes就给了我一个惊囍,真是说曹操曹操就到啊。头条就是:keepalived权威指南,吓死我了。
我想,我并没有求过签咋的呀。哈哈
本地做了一个备份:keepalived.pdf
还是架构:再谈 eBay 的扩展性最佳实践
Submitted by gouki on 2009, April 14, 9:02 AM
最近,好象谈架构比较多了,所以,我也就跟着copy,paste了一把。。原文来自DBA notes,网址为:http://www.dbanotes.net/arch/best_practices_for_scaling_websites_lessons_from_ebay.html,作者:feng。
内容如下:
很多人都觉得 eBay 在 QCon (北京) 上的技术讲座不错,但对我来说,其实冲击力没那么大了。eBay 一两年前就是这个 PPT 。不过还是比 Amazon 的 Jeff Barr 强了很多,以后要是开个什么会,你把 Jeff Barr 请来还讲那个销售文档,估计自己都不好意思。
不过,eBay 这次的PPT 总算还是有点更新的。
1)数据分片(Partition Everything)
说是分区(Partition),这里不能简单等同于 Oracle 的分区,理解成分片(Sharding)就好啦。可以参考一下我以前写的科普小文:开源数据库 Sharding 技术 (Share Nothing)。这里要强调一下的是,分片是在数据量的确有规模的时候才适合进行,如果单节点足以应付,那么还是不要冒进。
从分片的模式上,eBay 主要根据功能切分(Functional Segmentation)和水平分割(负载均衡考虑),作为推论,所有会话都是无状态性的。
2)异步处理(Asynchrony Everywhere)
其实对于任何网站来说,过度追求"同步"化设计还是比较糟糕的做法。以用户能观察到的数据为视角进行设计,中间可以最大限度用异步来完成。
eBay 的举例的模式有两个,一个是事件队列(Event Queue),另一个是信息分发(Message Multicast)。前者基本上是个生产者--消费者的模型。后者主要用在搜索的架构上。
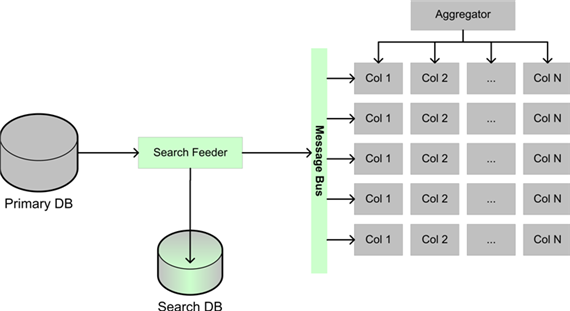
(膘叔:不知道怎么回事,我下载总是只显示一半看来是我的RP不好?)
注意到图中的消息总线,这才是 eBay 整个架构中的动脉,估计轻易不会批露技术细节
3)自动化(Automate Everything)
这里的自动化举了两个例子,一个是针对运维方面的,另外举了关于机器学习的东西,这是演讲者 Randy Shoup 的强项所在。
eBay 的自动化,在一年前的另一篇文章里可以窥测一点东西。只是这篇文章当初没有被更多人重视,参见:eclipse at eBay。可以看到 eBay 能在自动化方面做得这么好(起码敢出来讲)不是一朝一夕之功。
4)故障检测与回溯(Remember Everything Fails)
更好的失败检测机制: 监控每天超过 2TB 的日志,根据日志中的相关事件得出判断或者预警。这个看起来简单,但实现起来还是需要一点技巧和策略的,重要的是,需要不断根据结果的反馈去改进。
完美回滚: 任何服务都通过服务配置中的标记来识别,无痛回滚。(个人感觉这个非常有难度,尤其是升级的时候)
优雅降级(Graceful Degradation):能够相对容易的对应用标记"Marks down(下线)"
5)拥抱不一致性(Embrace Inconsistency)
举了 CAP 原则,程立将其形象描述为帽子戏法,非常准确。说起一致性,自从 Amazon CTO Werner Vogels的 Eventually Consistent 一出,基本上不需要我废话了,这就是事务处理的九阴真经,大家回家慢慢参详好了。
eBay 也有自己的绝对准则: 绝对没有分布式事务(两阶段提交), 通过状态机与操作顺序最小化不一致性,通过异步事件(消息总线?)达到最终一致性。
--EOF--
另外小道消息:Amazon CTO Werner Vogels 可能会参加六月份在杭州举办的侠客行大会。
以前的老帖子:eBay 的Scalability最佳实践
对了,如果想直接看讲了什么内容,请看
InfoQ中文站相关内容:
FriendFeed实现基于MySQL的无模式存储
Submitted by gouki on 2009, April 12, 8:13 AM
架构这个东西,不能一味的盲目抄袭,因为每种新架构的出现往往都有其特定的历史背景,要么是数据访问量太大、要么(想写的一些内容因为存储关系丢失了,一下子又没有想起来,下面是重写的,但内容已经和原来想的不太一样了)
高春辉就在他的勃客里认为,主从数据库不行了,未来的数据存储走向应该不会再是主从,他这么说:
- 这里可以先提前说一下吧,记得之前的迁移网站时的帖子里我说过,让 MYSQL 主从架构去死,很多人不太信。
- 而现在这个 DAL 的架子越来越清楚,我相信是可以达到99%的可能性,可以使主从架构从最大的用途是读写分离,变成了数据备份。其实我到现在也不知道 MySQL 当时推主从架构是为了读写分离还是数据备份。:D
- 我认为不管是主从还是主主结构都有一个最大的问题,主库和从库的数据的延迟更新问题,主主方式会好一些,但是配置起来太麻烦了。尤其是要求越高,就会越感觉到严重性。
- 而从程序员的角度,对于数据库的操作,最大的问题就是要把缓存的逻辑和数据逻辑混写,导致代码很难写也很难读,也很难调试清楚。
- 那么 DAL 如果能够帮助程序不用再关心缓存逻辑,只关心业务逻辑的话,不知道您是否认同 DAL 的重大作用呢?而代码量在我认为,起码可以减少个20%-30%吧?因为起码去掉了三个逻辑:读取缓存、判断有效和设置缓存。
- 我也觉得其实这个 DAL 的最核心功能就是如何自动缓存和清理缓存了。因为不让程序员缓存和清理,就的是程序自己来管理缓存和清理缓存,总得清理嘛。不过这个还是保密一下吧。起码不是某些人想的只能缓存单条数据,也不是某些人想的清理是按照单条方式的清理。当然另外的一个核心功能就是分库分表的自动和透明化,这个功能有很多软件都实现了,就不多说了。
文末,他推荐了一篇InfoQ上的文章,在这里我也进行转载一下,是关于FriendFeed实现基于MySQL的无模式存储,不过他这种架构也不是能拿来就要用的,也需要根据目前的实际情况,只能进行参考。这是一篇翻译文章:
作者 Dave West译者 王丽娟 发布于 2009年4月4日 下午8时7分
对于迅速增长的网站所遇到的问题——“用灵活的模式存储数据、即时创建新的索引”,FriendFeed的Bret Taylor介绍了一种“无模式的解决方案” 。问题本身源自一些需求:需要不断增加新功能,不断更新底层的数据库结构和数据库中存储的数百万条已有记录,还要同时支持新旧功能。FriendFeed的办法是基于MySQL建立一个无模式的解决方案,而不是迁移到别的技术基础上去。Bret描述了基本问题:
尤其是有一两千万行数据的时候,每次修改模式、往数据库中添加索引都会数小时完全锁定数据库。删除旧索引也需要同样长的时间,但不删除又会影响性能,因为 数据库在每次执行INSERT操作时都会继续读写这些不用的块,而重要的块却没有足够的内存。经过一些复杂的操作过程可以克服以上困难(比如在从机上创建 新索引,然后调换从机和主机),但这些操作过程都很容易出错,也都是重量级的,因此会使我们因为害怕改变模式/索引而不敢增加新功能。由于我们的数据库都 是严重分片的,像JOIN这些MySQL的关系型功能对我们毫无用处,所以我们决定看看RDBMS之外的领域。
研究了几个可行的解决方案后,他们决定基于MySQL的自定义一种“无模式”持久化方案,而不是彻底改换门庭。
他们的解决方案是把主要数据和这些数据的索引分离开来。“我们的数据存储储存了无模式的属性包……我们在单独的MySQL表中存储索引,从而在这些实体中索引数据。”这是以容量来换效率。
结果我们比以前多了很多的表,但添加和删除索引却很容易。我们大力优化了填充新索引的进程(我们称之为“Cleaner”),以便该进程能快速填充新索引,而不会让站点中断。
分离数据和索引引起了一致性和原子性问题。他们没有建立严格的事务规则,而是把数据库表推到最简,索引只用来引用,发生实际的数据库读操作的时候才 施加数据过滤。他们改进了持续更新表的自动化进程,让这个“Cleaner”进程不停地对优先级高的被更新实体进行更新和索引修正。尽管可能出现不一致, 但消除不一致的时间平均不到两秒钟。
Bret用平均页面延迟这一指标描述了以下走向。
- 整体来说——尽管有增加的趋势,但还是有显著的减少。
- 过去二十四小时——即使在高峰时段也保持稳定。
- 前一周——明显减少。
Bret的帖子有很多回复。有一种观点认为“对于模式演变,现代的RDBMS不像MySQL局限那么大”,这种观点忽略了选择背后的成本问题。其它读者则回复了更多种不同的解决办法。
有意思的是,并没有人指出FriendFeed的解决方案与古老的ISAM技术(Indexed Sequential Access Method,索引顺序存取法)之间的相似性。ISAM用的是同样的基本架构——分离数据和索引,同时在数据发生变化时自动更新索引。
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [666]
- python [9]
- Go [38]
- Flutter [14]
- lua [2]
- Scala & Ruby [12]
- Javascript [307]
- PHP Framework [65]
- Linux [289]
- 苹果相关 [229]
- DataBase [161]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [981]
- Baby [92]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- 前几年 lnmp.org 被收购,搞了一波投毒之后,我对这种一键...
06-03 - imlonghao - 这是默认主题啊,怎么分享
10-18 - gouki - 请问这个主题可以分享一下么 谢谢
10-14 - NN - 大佬你好,在用dcat 遇到 怎么做无感刷新的问题,请问你有做过...
02-01 - uc5bbl8s - 好用!!
07-14 - 口水
博客信息
- 分类数量: 17
- 文章数量: 3152
- 评论数量: 1906
- 标签数量: 2284
- 附件数量: 941
- 注册用户: 56
- 今日访问: 55248
- 总访问量: 75145026
- 程序版本: 1.6
