以下内容来自于linux的101个hack,昨天看到了,顺手翻译了一下,毕竟看中文比看英文舒服。翻译的还是有点问题的,理解一下下啦。。。
Hack 74. Crontab
第74个hack:Crontab
Using cron you can execute a shell-script or Linux commands at a specific time and date. For example a sysadmin can schedule a backup job that can run every day.
使用cron功能你可以在任意的时间执行一条shell指令或者Linux的命令。例如系统管理员可以运行一个计划任务来进行每天的备份工作。
How to add a job to the cron?
那么,怎么样把一个任务加入到cron呢?
# crontab –e
0 5 * * * /root/bin/backup.sh
This will execute /root/bin/backup.sh at 5 a.m every day.
上面这条指令,让你在每天上午5点 运行 /root/bin/目录下的 backup.sh 指令
Description of Cron fields.
Cron命令的各个字段的注释。
Following is the format of the crontab file.
crontab文件的格式均以下格式
{minute} {hour} {day-of-month} {month} {day-of-week} {full-path-to-shell-script}
{分钟} {小时} {每月的第几天} {月份} {每周的第几天} {指令的全路径}
o minute: Allowed range 0 -59
o 分钟的取值范围是 0-59
o hour: Allowed range 0 -23
o 小时的取值范围是 0-23
o day-of-month: Allowed range 0 - 31
o 每月的第几天,取值范围为 0-31
o month: Allowed range 1 -12. 1 = January. 12 = December.
o 月份的取值范围为 1-12 ,1是1月,12是12月
o Day-of-week: Allowed range 0 -7. Sunday is either 0 or 7.
o 每周的第几天,取值范围为0-7,0或者7都代表星期天
Crontab examples
Crontab 的例子
1. Run at 12:01 a.m. 1 minute after midnight everyday. This is a good time to run backup when the system is not under load.
1. 每天午夜12点零1分 ,当系统不再被加载时就是进行备份的好时机(not under load翻译不来)
1 0 * * * /root/bin/backup.sh
2. Run backup every weekday (Mon – Fri) at 11:59 p.m.
每周1-5晚上11点59分执行备份操作
59 11 * * 1,2,3,4,5 /root/bin/backup.sh
Following will also do the same.
下面的例子则是另一种格式,功能完全一致
59 11 * * 1-5 /root/bin/backup.sh
3. Execute the command every 5 minutes.
每五分钟执行一条命令
*/5 * * * * /root/bin/check-status.sh
4. Execute at 1:10 p.m on 1st of every month
每月第一天的下午1点10分执行备份
10 13 1 * * /root/bin/full-backup.sh
5. Execute 11 p.m on weekdays.
每周工作日的下午11点执行备份
0 23 * * 1-5 /root/bin/incremental-backup.sh
Crontab Options
Crontab 的一些参数
Following are the available options with crontab:
以下是crontab所支持一些参数
o crontab –e : Edit the crontab file. This will create a crontab, if it doesn’t exist
o crontab -e : 编辑crontab文件,如果文件不存在,则创建一个crontab
o crontab –l : Display the crontab file.
o crontab -l : 显示crontab文件
o crontab -r : Remove the crontab file.
o crontab -r : 删除crontab文件
o crontab -ir : This will prompt user before deleting a crontab.
o crontag -ir : 删除crontab文件,但在删除前会让用户进行确认

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
翻译:crontab的介绍
Submitted by gouki on 2009, March 10, 9:20 AM
备忘:swfUpload注意事项
Submitted by gouki on 2009, March 9, 4:40 PM
在使用swfupload上传文件的时候,老是绕不过登录验证。查了一下GOOGLe,没查到,问了百度,他告诉我答案:
swfuplaod在上传时,会新开一个进程,和原来的进程不一致,要解决这个问题,需要指定session_id,然后在登录页面判断,如果有post过来的session_id,那么就用函数session_id( $_POST['PHP_SESSIONID'])指定一下。
上传页的JS里面,可以获取当前的SESSION_ID的。
例如上传页的JS中:
post_params: {"PHPSESSID": "<?php echo session_id(); ?>"},
在验证的判断页中:
if (isset($_POST["PHPSESSID"])) {
session_id($_POST["PHPSESSID"]);
}
(这一段是网上的注释:在带有Session验证的网站后台中SWFUpload无法正常工作,这是因为SWFUpload在上传时相当于重新开辟了一个新的Session 进程,因此无法与原有程序的Session保持一致,这就需要在上传时传递原有程序的SessionID,根据它来“找回”其应有的Session。)
图片附件(缩略图):
在家里穿的少可以坐了(8个月+17天)
Submitted by gouki on 2009, March 8, 9:16 AM

记一次失败的下载:for wps
Submitted by gouki on 2009, March 7, 11:31 PM
wps是我喜爱的国产软件之一,听说升级到2009了,兴冲冲的到网站上去下载。
进入:http://www.wps.cn/product/index.htm,我想我应该没有理解错网站的意思,于是我先下载了升级包,结果失败,说我是最新版,我想2007大概不能升级到2009吧,然后就下载了直接的安装包。安装时提醒我说有旧软件要删除,兴奋呀。。
安装好后一运行 ,MD,还是2007.晕了我
看来是我RP太差了吧。
图片附件(缩略图):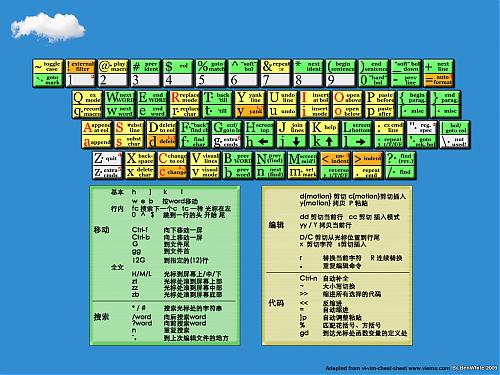
[分享]VIM操作指令的壁纸
Submitted by gouki on 2009, March 7, 9:58 PM
在很久前,我与大家分享过一张VI/VIM的操作键位图,那张相对较小一点,如今,发现两张大的,再放上来与君共享。(下载不在本地,如果是图片,那么点击小图,可以查看大图,已经本地版了,呵呵)
原文:http://www.cnitblog.com/benwhite/archive/2009/03/06/55167.html
内容:
近来心血来潮,想成为一个Vimer,于是开始发愤使用,但是新手的普遍问题就是常常在纷繁的命令中发懵,于是我想到了著名的vi-vim-cheat-sheet(ywpg推荐的),另外也找到了两张全黑的国人做的命令壁纸,但是两者均有失偏颇,不如干脆来个整合,做一个新版的壁纸。经过两个多小时,成果如下:(考虑到宽屏的童鞋,一并提供宽屏版)[由于都是很简单的命令,初学者下,高手请绕道:P]
打包下载 或 直接点击下面图片
1024x768

1680x1050
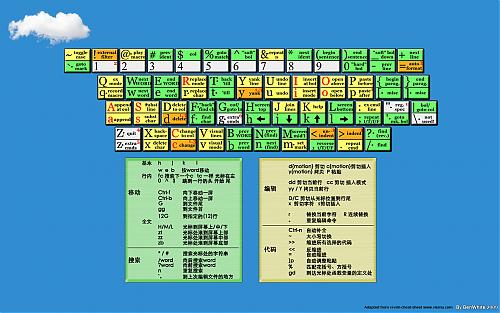
版权说明:本版本主要是从www.viemu.com 的cheat sheet改编,我想原作者会同意的,毕竟这是推广一个vi/vim的举动,顺便也替他做了广告:)
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [669]
- python [0]
- Go [9]
- Flutter [227]
- lua [0]
- Scala & Ruby [92]
- Javascript [307]
- PHP Framework [65]
- Linux [5]
- 苹果相关 [286]
- DataBase [0]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [982]
- Baby [161]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- It's going to be ending of...
07-05 - url - 好老的博客系统,当年用过。竟然还有人在用。
06-28 - im2828 - 你好,这个现在不能下载了,请重新提供一下吧
06-18 - 海东青 - 你这博客皮肤都20年了吧,该换了
05-27 - 月票的进哥 - 不用感觉,就是死了,停服公告都发出来了
05-27 - imlonghao
博客信息
- 分类数量: 17
- 文章数量: 3154
- 评论数量: 1911
- 标签数量: 2284
- 附件数量: 940
- 注册用户: 56
- 今日访问: 48924
- 总访问量: 75919647
- 程序版本: 1.6
