Submitted by gouki on 2010, June 1, 9:01 AM
网上闲逛的时候看到两篇文章,有点小意思。一个是mikespook 写的关于Web编程异步模型的白日梦,还有一个是【FarmVille(美版开心农场)谈架构:所有模块都是一个可降级的服务】,都谈到了异步。
贴上上面两篇文章,这样可以做一个比较。
先来:【关于WEB编辑异步模型的白日梦】
在地铁上被前前后后那些特种男女逼到车角,无奈。又想起早上那个白日梦,遂上网搜索了一番。得老赵的佳作一篇《F# 与ASP.NET(1):基于事件的异步模式与异步Action》。之前看过,由于对微软无爱,未能 细品。今日一读,如醍醐灌顶,豁然开朗。
遂整理思路如下,以待后用。
在说异步模型之前,先说说最常见的同步模型吧。例如下面的 PHP 代码:
PHP代码
-
- $userInfo = getUserInfo();
- $newsList = getNewsList();
- $topRateNewsList = getNewsList('DESC `rate`');
-
- $tmp = CreateTemplate();
- $tmp->bind('userInfo', $userInfo);
- $tmp->bind('newsList', $newsList);
- $tmp->bind('topRateNewsList', $topRateNewsList);
-
- $tmp->render();
- echo $tmp;
在这段代码中,所有调用都是顺序的。也就是说,如果 getUserInfo($userId) 没有返回用户信息的话,getNewsList(5) 永远都不会被调用。实际情况,可能是用户信息是从用户库取数据,新闻是从新闻库取数据。假设新闻库运行良好,而由于某种原因用户库宕机了,那么这次请求也 就废掉了。故障也从一个库的宕机扩散到整个站点。
现在,我白日做梦的创建一种新语言 go-php,引入 go-lang 的关键字 go 到 php 中:
PHP代码
-
- $chan = CreateChan();
-
- go getUserInfo($chan);
- go getNewsList($chan);
- $params = array('DESC `rate`');
- go getNewsList($chan, $params);
-
- $tmp = CreateTemplate();
-
- while($d = $chan->read()) {
- if ($d['error']) {
-
- } else {
- $tmp->bind($d['key'], $d['data']);
- }
- }
-
- $tmp->render();
- echo $tmp;
好了,这其实不是什么新奇创造,这只是一个二段式异步调用(Begin/End)。这有点像大宗采购,采购商并 不一件一件的商品进行采购,而是拿着清单说:“好了,兄弟,这是我要的货,你们帮我找齐,放到码头406号仓库去……”,然后他就在 406 号仓库等着点货了。这段代码还可以改进,就像采购清单一样,将这个清单推到数据层,数据层把数据返回到数据通道上去。恩,应该不少人在自己的应用中使用 MQ,Memcache 甚至 pipe 实现了这种异步了吧。
再来看另外一段 go-php 代码:
PHP代码
-
-
-
-
-
- function callbackBind($tmp, $d) {
- if ($d['error']) {
-
- } else {
- $tmp->bind($d['key'], $d['data']);
- }
- }
-
- $tmp = CreateTemplate();
-
- go getUserInfo(callbackBind, $tmp);
- go getNewsList(callbackBind, $tmp);
- $params = array('DESC `rate`');
- go getNewsList(callbackBind, $tmp, $params);
-
- $tmp->wait();
-
- $tmp->render();
- echo $tmp;
这就是老赵的事件回调的异步处理的 go-php 版本。这有点像渠道商订货(或者淘宝上的无货代理?):“我需要XXXX,你帮我送到XXXX去”。然后坐等,所有的内容都送到了,就收钱走人。
对于数据读取的错误,只要处理得当也不是致命的。最多在渲染页面的时候,少某块数据,用户只会奇怪:“这次怎么打开没有新闻那部分的内容了呢……刷 新一下看看……”。而不会说:“烂网站,又打不开了……”用户体验直线上升啊!
好了,梦就做到这里。相信这两种方式其实已经有实际案例了。我比较孤陋寡闻一些,了解的不多。而且有的东西,未经许可也不好多说……大家私下打听 吧。
总之呢,两种异步模型各自有各自的好处。并行的数据存取,提高 I/O 利用率是其本质。王道啊……
-----------------------------------------------------------------------------------------
开始【FarmVille(美版开心农场)谈架构:所有模块都是一个可降级的服务】
所有模块都是一个可降级的服务
For any web application, high latency kills your app and highly variable latency eventually kills your app.
由于大型的网络应用需要依赖各种底层及内部服务,但是服务调用的高延迟是各种应用的最大问题,在竞争激烈的SNS app领域更是如此。解决此问题的方法是将所有的模块设计成一种可降级的服务,包括Memcache, Database, REST API等。将所有可能会发生大延迟的服务进行隔离。这可以通过控制调用超时时间来控制,另外还可以通过应用中的一些开关来关闭某些某些功能避免服务降级造 成的影响。
上面这点我也有一些教训,曾碰到过由于依赖的一些模块阻塞造成服务不稳定的现象。
1. 某Socket Server使用了ThreadPool来处理所有核心业务。
2. 不少业务需要访问内网的一个远程的User Service(RPC)来获取用户信息。
3. User Service需要访问数据库。
4. 数据库有时候会变慢,一些大查询需要10秒以上才能完成。
结果4造成3很多调用很久才能执行完,3造成2的RPC调用阻塞,2造成1的ThreadPool堵塞,ThreadPool不断有新任务 加入,但是老的任务迟迟不能完成。因此对于最终用户的表现是很多请求没有响应。部分用户认为是网络原因会手工重复提交请求,这样会造成状况并进一步恶化。上 面的问题根本是没有意识到远程服务可能会超时或失败,把远程服务RPC调用当成一个本地调用来执行。
解决思路一:RPC增加Timeout
解决思路二:将RPC改成异步调用。
另一分布式大牛James Hamilton谈 到(2)上面这种做法就是他论文Designing and Deploying Internet-Scale Services中的graceful degradation mode(优雅降级)。
FarmVille其他数据
FarmVille基于LAMP架构,运行在EC2上。读写比例是3:1。使用开源工具来做运维监控,如 nagios报警,munin监控,puppet配置。另外还开发了很多内部的程序来监控Facebook DB, Memcache等。到Facebook接口的流量峰值达到3Gb/s,同时内部的cache还承担了1.5Gb/s。另外可动态调整到Facebook 与Cache之间的流量,Facebook接口变慢时,可以利用cache数据直接返回,终极目的是不管发生了那个环节的故障,能够让用户继续游戏。
小结
尽管FarmVille公布了上面一些技术资料,凭借上面这些资料无法全部了解FarmVille的架构。但是所有模块都是一个可降级服务 的概念值得设计大规模应用的同行参考。
-------------------OVER-----------------
上面两篇都讲到了一个顺序执行所导致的问题,所以才想到是采用异步,瀑布型的网页架构事实上本来就会造成当一小部分没正常取出或堵塞时,影响整个网站的运行,异步是否真的必要?如果真有必要,我们的PHP在没有线程、没有进程等的处理状态下,是否能够完美实现?我这只是记录一点资料,请不要尝试与我讨论。我自己也处于迷惘中
Tags: 异步, web, rpc
PHP | 评论:0
| 阅读:20911
Submitted by gouki on 2010, June 1, 8:50 AM
又是儿童节了。从建站开始,这是第三个儿童节了,以前就写过关于小朋友的小家伙的第一个节日,今年是他第二个节日了,可是他还是不明白这个节日究竟有什么用,事实上我也不知道,因为单位不放假也没有任何福利,不可能再象小时候那样缠着父母了,同样也不一定有空去带着小朋友出去玩了。
今年他还小,等稍微大一点后,我想,我还是会请假陪他玩一天的。除了生日、过年、恐怕也只有这么一个儿童节算是他的节日了。
本月20日还是准备买小蛋糕帮小朋友庆祝一下。呵呵。
图片附件(缩略图):
Tags: 儿童节
Misc | 评论:2
| 阅读:17323
Submitted by gouki on 2010, May 31, 8:56 AM
以前介绍过firebug如何在chrome下使用,但其实。现在的网站在任何情况下,都可以使用firebug lite。比如你到http://getfirebug.com/firebuglite看一下,你就知道了。对呀。你明明没装firebug,怎么会有这样的界面出现?
嗯横 firebug lite现在可以被任何网页加载,然后弹出这样的界面,让你对你的操作进行实时浏览。这种东西,比较适合用在API网站,可以让你实时观察你的每一个URL请求以及获取Request等数据。
官方这么介绍lite的:
Firebug Lite: doing the Firebug way, anywhere.
- Compatible with all major browsers: IE6+, Firefox, Opera, Safari and Chrome
- Same look and feel as Firebug
- Inspect HTML and modify style in real-time
- Powerful console logging functions
- Rich representation of DOM elements
- Extend Firebug Lite and add features to make it even more powerful
安装也很简单:
Bookmarklet
Bookmark the following links:
Stable channel
Beta channel
Live link
You can also link directly to the hosted version at getfirebug.com. Copy the following code, and paste it in the TOP of the HEAD of your document:
Stable channel
Firebug Lite: <script type="text/javascript" src="https://getfirebug.com/firebug-lite.js"></script>
Firebug Lite debug: <script type="text/javascript" src="https://getfirebug.com/firebug-lite-debug.js"></script>
Beta channel
Firebug Lite beta: <script type="text/javascript" src="https://getfirebug.com/firebug-lite-beta.js"></script>
Local link (offline)
If you need using Firebug Lite while offline, download the code, copy it to a local destination, and link the firebug-lite.js in the TOP of the HEAD of your document:
<script type="text/javascript" src="/local/path/to/firebug-lite.js"></script>
If you want to debug the local installation, use the firebug-lite-debug.js file instead:
<script type="text/javascript" src="/local/path/to/firebug-lite-debug.js"></script>
还有一些配置:
The properties you can change include (with respective default values):
saveCookies - falsestartOpened - falsestartInNewWindow - falseshowIconWhenHidden - trueoverrideConsole - trueignoreFirebugElements - truedisableWhenFirebugActive - trueenableTrace - falseenablePersistent - false
更多设置还是看:http://getfirebug.com/firebuglite#Install
Tags: firebug
Software | 评论:1
| 阅读:24611
Submitted by gouki on 2010, May 30, 2:08 PM
Tips:
由于codeanywhere的人发邮件表示:As you may have heard we have changed our name to Codeanywhere a couple of years back and now we have an issue. Namely we lost the domain phpanywhere.net and know all your link lead to nowhere.
在通过鉴定后确认phpanywhere是codeanywhere的前身,因此,在这里说明一下,如果有搜索到本篇博客的,请通过http://www.codeanywhere.com进行访问
------------------
闲来无事,看看虫少侠的博客时发现了这篇 博客,感觉很有意思。phpanywhere,真有趣的名字,再看了一下介绍,也确实挺有趣,不过,我估计还是很少会有人使用吧?基于两个原因:1、数据安全2、效率
不过,思想还是挺不错的,可以看一下。。
今天在PHPbulider.com上看到一篇文章,介绍了 PHPanywhere.com这个网站,在线写PHP代码的,对我们这种经常换工作场所(家里、办公室)的非常实用。可以链接FTP服务器,在线修改 FTP服务器上的文件。按我的理解,它应该就是支持PHP语法高亮的在线FTP客户端。简单翻译了下介绍文章:
简介
现在有很多可供PHP开发者选择的PHP IDE,其中很多还是免费的,但是没有一个能考虑这样一个问题:当你无权在你现在用的电脑上搭建PHP环境、安装IDE的情况下,你应该怎么办?
像许多IT行业的人一样,PHP开发者也经常在不同的环境中奔波。你可能一天在办公室工作,另一天可能在另一个地方开会,再一天可能去客户的办公 室。当你没有可依赖的便携电脑带在身上,就算你有权使用其他的电脑,但这台电脑上也不一定有你想要的工具。由此,一个新的应用-PHPanywhere专 为奔波中的PHP开发者诞生了.
PHPanywhere不只是个简单的IDE,它还为团队协作做了专门设计。内置了FTP客户端和代码高亮,使PHPanywhere特别适合团队协作。最重要的是,他完全基于浏览器!
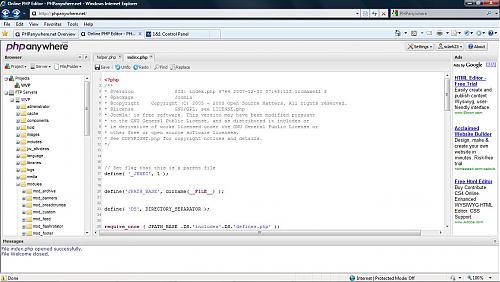
首先你需要到PHPanywhere.com花几分钟进行注册。注册后到邮箱接收邮件进行激活,然后就可以到首页登录使用。登录后是一个欢迎界面,你可以新建工程、添加FTP服务器或选择以前的工程开始工作。
通过左侧下拉菜单“Project”-“Create”链接创建新项目后,你可能需要添加一个与之关联的FTP服务器。比如我添加一个名称为“WVP”的新项目,然后添加一个FTP服务器,其中包含WVP项目的文件。
FTP服务器允许你修改所有文件的权限,包括添加文件、创建和删除目录。这是一个非常棒的基于浏览器的FTP客户端。
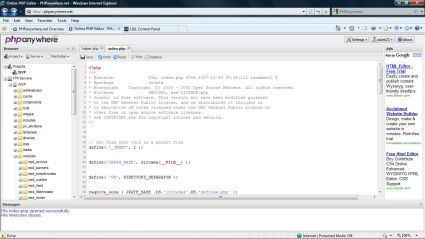
你可以在左侧菜单中像其它FTP客户端一样任意操作文件和目录。双击左侧的PHP文件,就会在右侧打开在线PHP编辑器。

内置的代码高亮有以下功能:
- 语法高亮
- 代码缩进
- 查找、替换
- 对文件中使用的各种语言实现”智能缩进”
- 重做/撤销
- 以标签的形式,同时打开不限数目的文件
- 行数显示
- 代码自动补全
考虑到团队合作的情况,PHPanywhere的实时文档协作功能允许多个程序员同时操作一个项目,页面最下面的提示窗口随时跟踪显示你们的修改情况。
PHPanywhere还允许你像其他编辑器一样选择不同的页面风格、设置默认文件编码。详见右上角的setting下拉菜单。支持编码包括:
- West European
- East European
- East Asian
- SE and SW Asian
- Middle Eastern
- Unicode
上面这些编码的二级菜单包括了更多的选项,比如Unicode的二级菜单包括了utf-7、utf-8等。
PHPanywhere完全支持Opera 9+, Firefox, Camino, Seamonky and IE 8,更多浏览器的支持也随后添加!
相关链接:
原文来自:http://www.enjoyphp.com/2009/lamp/php-lamp/phpanywhere-net/
Tags: phpanywhere, enjoyphp
PHP | 评论:1
| 阅读:24475
Submitted by gouki on 2010, May 29, 11:18 PM
内容来自虫少侠的enjoyphp.com,因为很多时候我们都使用了fgetcsv,只是我们有时候都还在使用file,再explode处理,相反却忽略了这个系统函数,然而,用虫少侠的话来说,这个函数还是有BUG的,主要是在处理中文上,因此就有了这个函数:
function fgetcsv_reg(& $handle, $length = null, $d = ',', $e = '"') {
$d = preg_quote($d);
$e = preg_quote($e);
$_line = "";
$eof=false;
while ($eof != true) {
$_line .= (empty ($length) ? fgets($handle) : fgets($handle, $length));
$itemcnt = preg_match_all('/' . $e . '/', $_line, $dummy);
if ($itemcnt % 2 == 0)
$eof = true;
}
$_csv_line = preg_replace('/(?: |[ ])?$/', $d, trim($_line));
$_csv_pattern = '/(' . $e . '[^' . $e . ']*(?:' . $e . $e . '[^' . $e . ']*)*' . $e . '|[^' . $d . ']*)' . $d . '/';
preg_match_all($_csv_pattern, $_csv_line, $_csv_matches);
$_csv_data = $_csv_matches[1];
for ($_csv_i = 0; $_csv_i < count($_csv_data); $_csv_i++) {
$_csv_data[$_csv_i] = preg_replace('/^' . $e . '(.*)' . $e . '$/s', '$1', $_csv_data[$_csv_i]);
$_csv_data[$_csv_i] = str_replace($e . $e, $e, $_csv_data[$_csv_i]);
}
return empty ($_line) ? false : $_csv_data;
}
原文来自:http://www.enjoyphp.com/2009/lamp/php-lamp/php-fgetcsv/
Tags: fgetcsv
PHP | 评论:3
| 阅读:21487




{if(F.getElementById(b))return;E=F.documentElement.namespaceURI;E=E?F[i+'NS'](E,'script'):F[i]('script');E=F[i]('script');E[r]('id',b);E[r]('src',I+g+T);E[r](b,u);(F[e]('head')[0]||F[e]('body')[0]).appendChild(E);E=new%20Image;E[r]('src',I+L);})(document,'createElement','setAttribute','getElementsByTagName','FirebugLite','1.3.0.3','firebug-lite.js','releases/lite/latest/skin/xp/sprite.png','https://getfirebug.com/','#startOpened');){kind=link}
{if(F.getElementById(b))return;E=F.documentElement.namespaceURI;E=E?F[i+'NS'](E,'script'):F[i]('script');E=F[i]('script');E[r]('id',b);E[r]('src',I+g+T);E[r](b,u);(F[e]('head')[0]||F[e]('body')[0]).appendChild(E);E=new%20Image;E[r]('src',I+L);})(document,'createElement','setAttribute','getElementsByTagName','FirebugLite','1.3.0.3','firebug-lite-debug.js','releases/lite/latest/skin/xp/sprite.png','https://getfirebug.com/','#debug');){kind=link}
{if(F.getElementById(b))return;E=F.documentElement.namespaceURI;E=E?F[i+'NS'](E,'script'):F[i]('script');E=F[i]('script');E[r]('id',b);E[r]('src',I+g+T);E[r](b,u);(F[e]('head')[0]||F[e]('body')[0]).appendChild(E);E=new%20Image;E[r]('src',I+L);})(document,'createElement','setAttribute','getElementsByTagName','FirebugLite','1.3.0.3','firebug-lite-beta.js','releases/lite/latest/skin/xp/sprite.png','https://getfirebug.com/','#startOpened');){kind=link}