原文作者:yizhu2000
链接:http://www.phpv.net/html/1663.html
本人作为一位web工程师,着眼最多之处莫过于性能与架构,本次幸得参与sd2.0大会,得以与同行广泛交流,于此二方面,有些架构设计的心得,不敢独享,与众友分享,本文是这次参会与众同撩交流的心得.
架构设计的几个心得:
一,不要过设计:never over design
这是一个常常被提及的话题,但是只要想想你的架构里有多少功能是根本没有用到,或者最后废弃的,就能明白其重要性了,初涉架构设计,往往倾向于设计大而化 一的架构,希望设计出具有无比扩展性,能适应一切需求的增加架构,web开发领域是个非常动态的过程,我们很难预测下个星期的变化,而又需要对变化做出最 快最有效的响应。。
ebay的工程师说过,他们的架构设计从来都不能满足系统的增长,所以他们的系统永远都在推翻重做。请注意,不是ebay架构师的能力有问题,他们 设计的架构总是建立旧版本的瓶颈上,希望通过新的架构带来突破,然而新架构带来的突破总是在很短的时间内就被新增需求淹没,于是他们不得不又使用新的架构
web开发,是个非常敏捷的过程,变化随时都在产生,用户需求千变万化,许多方面偶然性非常高,较之软件开发,希望用一个架构规划以后的所有设计,是不现实的
二,web架构生命周期:web architecture‘s life cycle
既然要杜绝过设计,又要保证一定的前瞻性,那么怎么才能找到其中的平衡呢?希望下面的web架构生命周期能够帮到你

所设计的架构需要在1-10倍的增长下,通过简单的增加硬件容量就能够胜任,而在5-10倍的增长期间,请着手下一个版本的架构设计,使之能承受下一个10倍间的增长
google之所以能够称霸,不完全是因为搜索技术和排序技术有多先进,其实包括baidu和yahoo,所使用的技术现在也已经大同小异,然而,google能在一个月内通过增加上万台服务器来达到足够系统容量的能力确是很难被复制的
三,缓存:Cache
空间换取时间,缓存永远计算机设计的重中之重,从cpu到io,到处都可以看到缓存的身影,web架构设计重,缓存设计必不可少,关于怎样设计合理的缓 存,jbosscache的创始人,淘宝的创始人是这样说的:其实设计web缓存和企业级缓存是非常不同的,企业级缓存偏重于逻辑,而web缓存,简单快 速为好。。
缓存带来的问题是什么?是程序的复杂度上升,因为数据散布在多个进程,所以同步就是一个麻烦的问题,加上集群,复杂度会进一步提高,在实际运用中,采用怎样的同步策略常常需要和业务绑定
老钱为搜狐设计的帖子设计了链表缓存,这样既可以满足灵活插入的需要,又能够快速阅读,而其他一些大型社区也经常采用类此的结构来优化帖子列表,memcache也是一个常常用到的工具
链接:钱宏武谈架构设计视频 http://211.100.26.82/CSDN_Live/140/qhw.flv
Cache的常用的策略是:让数据在内存中,而不是在比较耗时的磁盘上。从这个角度讲,mysql提供的heap引擎(存储方式)也是一个值得思考的方法,这种存储方法可以把数据存储在内存中,并且保留sql强大的查询能力,是不是一举两得呢?
我们这里只说到了读缓存,其实还有一种写缓存,在以内容为主的社区里比较少用到,因为这样的社区最主要需要解决的问题是读问题,但是在处理能力低于 请求能力时,或者单个希望请求先被缓存形成块,然后批量处理时,写缓存就出现了,在交互性很强的社区设计里我们很容易找到这样的缓存
四,核心模块一定要自己开发:DIY your core module
这点我们是深有体会,钱宏武和云风也都有谈到,我们经常倾向于使用一些开源模块,如果不涉及核心模块,确实是可以的,如果涉及,那么就要小心了,因为当访 问量达到一定的程度,这些模块往往都有这样那样的问题,当然我们可以把问题归结为对开源的模块不熟悉,但是不管怎样,核心出现问题的时候,不能完全掌握其 代码是非常可怕的
五,合理选择数据存储方式:reasonable data storage
我们一定要使用数据库吗,不一定,雷鸣告诉我们搜索不一定需要数据库,云风告诉我们,游戏不一定需要数据库,那么什么时候我们才需要数据库呢,为什么不干脆用文件来代替他呢?
首先我们需要先承认,数据库也是对文件进行操作。我们需要数据库,主要是使用下面这几个功能,一个是数据存储,一个是数据检索,在关系数据库中,我们其实非常在乎数据库的复杂搜索的能力,看看一个统计用的tsql就知道了(不用仔细读,扫一眼就可以了)
select c.Class_name,d.Class_name_2,a.Creativity_Title,b.User_name,(select count(Id) from review where Reviewid=a.Id) as countNum from Creativity as a,User_info as b,class as c,class2 as d where a.user_id=b.id and a.Creativity_Class=c.Id and a.Creativity_Class_2=d.Id
select a.Id,max(c.Class_name),(max(d.Class_name_2),max(a.Creativity_Title),max(b.User_name),count(e.Id) as countNum from Creativity as a,User_info as b,class as c,class2 as d,review as e where a.user_id=b.id and a.Creativity_Class=c.Id and a.Creativity_Class_2=d.Id and a.Id=e.Reviewid group by a.Id ..............................................
我们可以看出需要数据库关联,排序的能力,这个能力在某些情况下非常重要,但是如果你的网站的常规操作,全是这样复杂的逻辑,那效率一定是非常低 的,所以我们常常在数据库里加入许多冗余字段,来减小简单查询时关联等操作带来的压力,我们看看下面这张图,可以看到数据库的设计重心,和网站(指内容型 社区)需要面对的问题实际是有一些偏差的
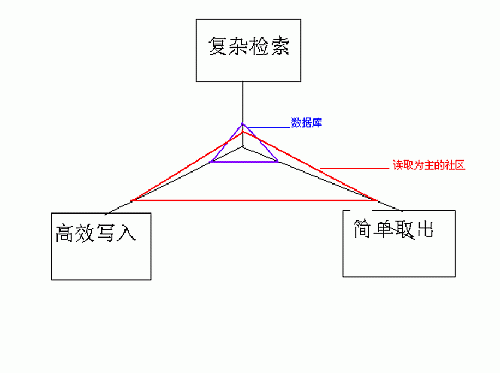
同样其他一些软件产品也遇到同样的问题所以具我了解,有许多特殊的运用都有自己设计的特殊数据存储结构与方法,比如有的大型服务程序采取树形数据存储结构,lucene使用文件来存储索引和文件
从另外一个角度上看,使用数据库,意味着数据和表现是完全分离的(这当然是经典的设计思路),也就是说当需要展示数据时,不得不需要一个转换的过 程,也可以说是绑定的过程,当网站具备一定规模的时候,数据库往往成为效率的瓶颈,所以许多网站也采用直接书写静态文件的方法来避免读取操作时的绑定
这并不是说我们从今天起就可以把我们亲爱的数据库打入冷宫,而是我们在设计数据的持久化时,需要根据实际情况来选择存储方式,而数据库不过是其中一个选项
六,搞清楚谁是最重要的人:who's the most important guy
在用例需求分析的时候常常讲到涉众,就是和你的设计息息相关的人,在web中我们一定以为最重要的涉众莫过于用户了。,在一个传统的互动社 区开发中,最重要的东西是内容,用户产生内容,所以用户就是上帝,至于内容挑选工具,不就是给坐我后面三排的妹妹们用的吗?凑或行了,实在有问题我就在数 据里手动帮你加得了。。这大概是眼下许多小型甚至中型网站技术人员的普遍想法。钱宏武在他的讲座里谈到了这个问题:实际上网站每天产生的内容非常的多,普 通人是不可能看完的,而编辑负责把精华的内容推荐到首页上,所以很多用户读到的内容其实都依赖于编辑的推荐,所以设计让编辑工作方便的工具也是非常重要, 有时甚至是最重要的。
七,不要执着于文档:don't be crazy about document
web开发的文档重要吗?什么文档最重要?我的看法是web开发中交流>文档,
现在大的软件公司比较流行的做法是:
注重产品设计文档,在这种方法里,产品文档非常详尽,并且没有歧义,开发人员基于设计文档开发,测试人员基于设计文档制定测试方案,任何新人都可以通过阅读产品设计文档来了解项目的概况
而web项目从概念到实现的时间是非常短的,而且越短越好,并且由于变化迅速,要想写出完整的产品和需求文档是几乎不可能的,大多数情况是等你写出 完备的文档,项目早就是另外一个样子,但是没有文档的问题是,如果团队发生变化,添加新成员怎样才能了解软件的结构和概念呢,一种是每个人都了解软件的整 个结构,除非你的团队整体消失,否则任何一个人都能够担当培养新人的责任,这种face2face交流比文档有效率很多。
于是就有了前office开发者,现任yahoo中国某产品开发负责人的刘振飞所感觉到的落差,他说,我们的项目是吵出来的,我听完会心一笑
八,团队:team
不要专家团队,而要外科手术式的团队,你的团队里一定要有清道夫,需要有弓箭手,让他们和项目一起成长,才是项目负责人的最大成就
总结:
架构是一种权衡

web开发的特点是是:没有太复杂的技术难点,一切在于迅速的把握需求,其实这正式敏捷开发的要旨所在,一切都可以非常快速的建立,非常快速的重构,我们的开发工具,底层库和框架,包括搜索引擎和web文档提供的帮助,都提我们供给了敏捷的能力。
此外,相应的,最有效率的交流方式必须留给web开发,那就是face2face(面对面),不要太担心你的设计不能被完备的文档所保留下来,他们会以交流,代码和小卡片的方式保存下来
人的因素会更加重要,无论是对用户的需求,还是开发人员的素质。
1.SQL需求,统计当天的数据量。
SQL> SELECT count(*) FROM test_union WHERE win_type=1 AND gmt_create >= trunc(sysdate,'dd') and gmt_create <= trunc(sysdate,'dd')+1;
COUNT(*)
----------
20063
1 row selected.
2.查看其索引,以gmt_create开头。
sql>create index idx_union on test_union (gmt_create,win_type) tablespace tbs_index compute statistics;
3.查看awr报表的性能,逻辑读很高,达到9700个。
Buffer Gets Executions Gets per Exec %Total Time Time (s) Hash Value
--------------- ---------- -------------- ------ -------- --------- ------
205,157,987 21,236 9,660.9 34.5 6733.21 7568.58 1532799124
Module: java@app12345 (TNS V1-V3)
SELECT count(*) FROM test_union WHERE win_type=1 AND gmt_create >= trunc(sysdate,'dd') and gmt_create <= trunc(sysdate,'dd')+1
因为是只通过索引扫描,当看到返回结果集在2万左右,我们很容易估算出这个sql需要的逻辑读,(gmt_date字段7个字节+win_type字段1个字节+rowid+…)*2万,小于100个,现在很明显是偏高的。
4.调整前我们先去看数据分布。
SQL> select win_type,count(*) from test_union group by win_type; --按win_type分组
win_type count(*)
---------- ----------
0 8583162
1 2725424
2 765237
3 2080156
4 2090871
5 3568682
SQL> select count(*) from test_union where gmt_create >= trunc(sysdate,'dd') and gmt_create <= trunc(sysdate,'dd')+1; --按gmt_create统计,一天数据量在22万左右
COUNT(*)
----------
229857
1 row selected.
5.调整索引,改为以win_type开头,为什么要以win_type开头呢?
create index idx_union123 on test_union (win_type,gmt_create) tablespace tbs_index compute statistics; --新索引
6.查看其执行计划,逻辑读变成了89。
sql>set auto traceonly
sql> select count(*) from test_union
where win_type=1 and gmt_create >= trunc(sysdate,'dd') and gmt_create <= trunc(sysdate,'dd')+1;
Elapsed: 00:00:07.17
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=3 Card=1 Bytes=9)
1 0 SORT (AGGREGATE)
2 1 FILTER
3 2 INDEX (RANGE SCAN) OF 'idx_union123' (NO
N-UNIQUE) (Cost=7 Card=1 Bytes=9)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
89 consistent gets
0 physical reads
0 redo size
493 bytes sent via SQL*Net to client
655 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
都在说建索引一定要看数据分布,从数据分布来看,一天的的数据(gmt_create)量在22万左右,而win_type的数据量非常 大,win_type为1有300万左右,为什么还要把win_type放在索引的前面呢?抛块砖,希望大家能对联合索引有更深入的理解,希望一起讨论。
--EOF--
帖子下的几个评论也很有意思:
XML/HTML代码
- 1. 1棉花糖ONE
-
- hehe,所以我在itpub上经常建议人家如果是建复合索引的话,把范围查询的谓词尽量放在后面,这样能增加木匠说的有效索引选择度,对oracle执行计划的判断有意义,当然更主要的是这样创建索引确实是减少了索引扫描的范围,不知道楼主的环境还在不在,根据数据来看,这2个字段是相关的,而且楼主恰好查询的是 count(*),可以不扫描表,走复合索引就比较正常,如果是select * from … ,这样很可能就不会选择走索引,就11g以前除了动态采样,加hint,统计信息上应该是搞不对,我测试了11g的扩展列的统计信息,感觉这玩意效果没有想象中的理想
- Comment on Jan 10th, 2009 at 9:58 am
- 2. 2木匠
-
- 如果没有搞清楚SQL optimizer engine and Run time engine怎么工作,怎么使用composite index,
- 你的观测结果只是表面现象,永远也不知道为什么.
-
- 查看数据分布是对的,
- 但是这种情况是需要寻根问底的. my CA$0.02 + tax, 我的一点建议.
-
- 木匠不辞劳苦,再重复一遍SQL optimizer and runtime engine 是怎么工作的:
-
- as soon as we have a range scan on a column used somewhere in the
- middle of an index definition or fail to supply a test on such a column, the predicates on later columns do not restrict the selection of index leaf blocks that we have to examine.
-
- In this case, the effective index selectivity has to be calculated from the predicate on just the “gmt_create” column. Because the test on “gmt_create” is range-based, the predicates on “win_type” do not restrict the number of index leaf blocks we have to walk.
-
- 关键字: effective index selectivity.
- Comment on Jan 10th, 2009 at 1:49 am
- 3. 3丁原
-
- 这个案例已经很久了。
- 实际上是没有打算写的,这个例子一直有人在问为什么,问的多了,我干脆就邮件中的内容整理出来,大家 讨论加深印象。
- 我尝试把线上的数据拉下来做测试,发觉太大了根本拉不下来,只能是拼拼凑凑,gmt_create的索引已经drop掉了,部分测试数据可能不那么准确,但是数据还是在范围之内,不会偏差很大。
-
- 逻辑读怎么算?
- select (7+1+rowid+..)*20000/8192,差不多就是我们要的逻辑读。
-
- to木匠:cost不一定准确的,我更多的是查看数据分布,结果集,以逻辑读来判断。
- to棉花糖:回复有审核的,防止很多垃圾广告。
- Comment on Jan 9th, 2009 at 5:11 pm
- 4. 4carcase
-
- win_type,gmt_create 扫描的索引块少多了,确定了win_type=1的范围后,再确定了是当天的数据
- (索引是win_type,gmt_create 排序的,范围扫描马上能定位到当天的数据)也就扫描了2万多就够了 ,速度得到了提升。
- 和
- gmt_create,win_type 扫描的索引块多了很多,相当于扫描了 gmt_create当天所有的数据了,22万多数据都要扫描一遍,过滤出win_type=1 的数据
- Comment on Jan 9th, 2009 at 11:05 am
- 5. 5棉花糖ONE
-
- Your comment is awaiting moderation.
- 到底咋回事啊
- Comment on Jan 9th, 2009 at 10:45 am
- 6. 6棉花糖ONE
-
- 逻辑读89是不是搞错了
- Comment on Jan 9th, 2009 at 10:45 am
- 7. 7jlttt
-
- 我们很容易估算出这个sql需要的逻辑读,(gmt_date字段7个字节+win_type字段1个字节+rowid+…)*2万,小于100个
- (7+1+10+…)×2W 所读的块怎么算出小于100的?
- Comment on Jan 9th, 2009 at 9:46 am
- 8. 8棉花糖ONE
-
- to 木匠:
- cardinality=1可能和9i有关,sysdate包含函数计算的时候,没有直方图的情况下,范围查询的选择度是按5%算的,2个5%*5%
- Comment on Jan 9th, 2009 at 9:42 am
- 9. 9棉花糖ONE
-
- 如果把范围的放前面,索引的第二个字段只是起到filter的作用,并没有减少索引扫描的块,从索引的成本计算也能看出这一点
- Comment on Jan 9th, 2009 at 9:36 am
- 10. 10木匠
-
- 对不起,再唠叨一句.
-
- 除了比较cost,还要比较Cardinality, 第二个SQL,index scan这一步的Card=1.
- 但是我觉得index scan这一步的Cardinality应该大于一, 不知道哪里出了问题.
-
- 每一个Oracle版本的Cost and Card会有不同的结果.9.2.0.6 and 10.1.0.4或更高版本会提供更有用的信息.
-
- (木匠真够粗心大意的, 请包涵)
- Comment on Jan 9th, 2009 at 2:26 am
- 11. 11木匠
-
- In this case, the effective index selectivity has to be calculated from the predicate on just the “gmt_create” column. Because the test on “gmt_create” is range-based, the predicates on “win_type” do not restrict the number of index leaf blocks we have to walk.
-
- 照搬老刘(Lewis)的原话, 改一下列名就行了. :)
-
- 上一个评论中的cost 指的是整个SQL(with index scan)的cost.
-
- 另外, 你忘了记录走第一个索引的SQL执行计划,可以比较一下 INDEX (RANGE SCAN) 的 cost.
-
- INDEX (RANGE SCAN) OF ‘idx_union123′ (NON-UNIQUE) (Cost=7 Card=1 Bytes=9), 我们看到走第二个索引的(index range scan) cost=7.
- Comment on Jan 9th, 2009 at 2:03 am
- 12. 12木匠
-
- Q: 为什么还要把win_type放在索引的前面呢?
- A: leaf_blocks * effective index selectivity
-
- 第一个索引, range scan on gmt_create, first column on index.
- Because as soon as we have a range scan on a column used somewhere in the
- middle of an index definition or fail to supply a test on such a column, the predicates on later columns do not restrict the selection of index leaf blocks that we have to examine.
-
- 参考:
- cost =
- blevel +
- ceiling(leaf_blocks * effective index selectivity) +
- ceiling(clustering_factor * effective table selectivity)
-
- a well-known guideline for arranging the columns in a multicolumn
- index. Columns that usually appear with range-based tests should generally appear later in the index than columns that usually appear with equality tests. Unfortunately, changing the column ordering in an index can have other contrary effects, which we will examine in Chapter 5.
-
- Now you got test case. very well ! ^_^
-
- Reference: page 74,62,67 of book Cost-Based Oracle Fundamentals
- Comment on Jan 9th, 2009 at 1:52 am

