鸡肋者,食之无味,弃之可惜。
这是杨修被杀前说的话。
PDF查看插件是最新WPS里提供的,使用后,打开PDF,可以很完整的看到书签,然而,内容却全部变成了乱码。
在使用福昕打开后,一切正常。并没有乱码出现。
由此可见,这个PDF查看的插件,还不如没有。
但是,WPS导出PDF的功能还是不错的。至少我挺喜欢。首先不用担心别人再修改我的文档了:其次,如果按照规范做的文档,还能够按层次自动生成书签。
可惜了这个PDF查看插件。
怎么,不相信?有图为证
WPS截图:
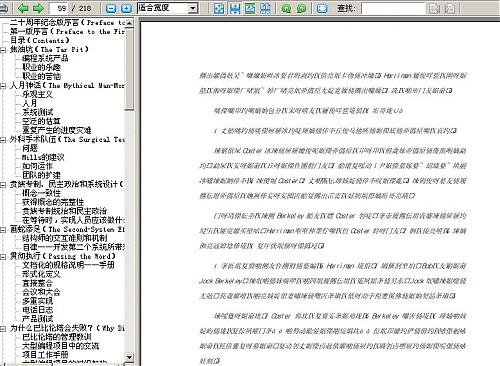
福昕截图:
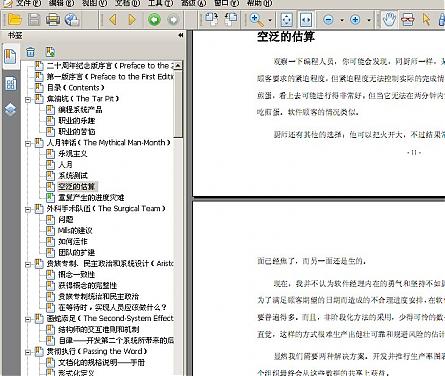

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
Submitted by gouki on 2009, September 22, 4:52 PM. Software
鸡肋者,食之无味,弃之可惜。
这是杨修被杀前说的话。
PDF查看插件是最新WPS里提供的,使用后,打开PDF,可以很完整的看到书签,然而,内容却全部变成了乱码。
在使用福昕打开后,一切正常。并没有乱码出现。
由此可见,这个PDF查看的插件,还不如没有。
但是,WPS导出PDF的功能还是不错的。至少我挺喜欢。首先不用担心别人再修改我的文档了:其次,如果按照规范做的文档,还能够按层次自动生成书签。
可惜了这个PDF查看插件。
怎么,不相信?有图为证
WPS截图:
福昕截图:
dede和我那个用的是同一个算法其实。只不过我加了个临时队列,把大于等于一个的连续的未成词的字作为一个词输出,这个在人名识别上有点用。这种算法用不用词频没啥用,因为是最长匹配,用词频来个倒排只能是可能会尽快的匹配上,在分词准确度上没什么提高。我见过的最好的分词程序是中科院计算所做的,而且有简化了一点的版本开源(能学习不能用于商业用途)下载,强力推荐C#版的。
Post by yhustc on 2009, September 21, 8:52 PM  #1
#1
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
[668] [0] [9] [227] [0] [92] [307] [65] [5] [286] [0] [236] [9] [27] [14] [982] [161]