原文:http://www.cnblogs.com/yangzhou1030/archive/2008/11/05/1326794.html
作者:Yang Zhou
感谢:Crystal
日期:2008年10月
介绍
对学习Flash CS3和Actionscript 3.0中的3D编程感兴趣?You come to the right place!在文章中,我将陆续的介绍在Flash中使用Actionsript进行3D编程一些理论和实例。这是一篇初级到中级难度的学习资料,如果你 具有一些基本的数学和几何知识,那对你来说不会太难。请注意:这并不是针对Flash CS4开发平台的文章,文章讲述的是你自己如何动手构架一个3D引擎所需要的基础数学和算法,试图让你明白开发一个3D引擎的历程,而并不是教你如何使用 所谓最新的科技和一些Flash 3D引擎。文章中的例子笔者在Flash Professional CS3 IDE, Actionscript 3.0编译环境里运行没有发现问题。
目录
Flash与3D编程探秘(一)- Flash与3D空间
Flash与3D编程探秘(二)- 静态长方体
Flash与3D编程探秘(三)- 摄像机(Camera)
Flash与3D编程探秘(四)- 摄像机旋转基础知识
Flash与3D编程探秘(五)- 摄像机旋转和移动
Flash与3D编程探秘(六)- 全方位旋转摄像机
作者很强劲,写的也比较详细,如果有用flash进行开发的朋友,有福了
互联网的冬天已经来了?上半年马云就在说着,互联网的冬天就要来了,我们一定要挺住。
总以为这些离我们很远,但是现在发现,离着我们是越来越近了。
股票的下跌就不提了,毕竟科技股也在股票当中,阿里巴巴的H股恐怕让人大跌眼镜,但淘宝却又始终坚挺。
全球裁员风已经波及到国内了。昨天六间房也宣布裁员2/3,诺基亚裁员600人。冬天真的来了。
六间房:《一个馒头引发的血案》让六间房网站被全国人民所熟知。
PS:刚刚发现网易已经在纪念了:http://tech.163.com/special/000931CN/Layoffs2008.html
2008-11-05 先留下当前的图:
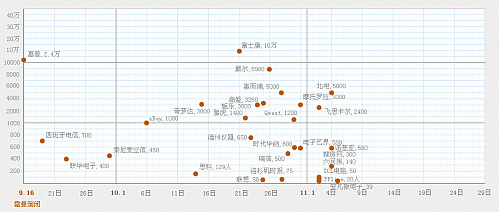
| 金融海啸下,全球IT业裁员日志(涉及企业 28 家 共/将裁员约 167023 人) |
|
|
|
一个功能超强的查找与替换工具。它可以对同一硬盘中的所有文件进行搜索与替换,也可以搜索 Zip 文件中的文件,并支持特殊字符条件表达式的搜索,以及以脚本文件(Script)进行搜索和替换,也可以以二进制的表示方式做搜索和替换。而对搜索到的文 件也可以针对内容、属性、及日期进行修改或者启动关联的应用程序。从所提供的功能来讲,该软件可以说是同类软件中最出色的。
这个软件曾经让我在一个项目中因为其他部门的人需要改字段让我在一天内完成了整个工作。按其他的方法来的话,可能需要大概一周时间,因为大约有几百个文件,可能每个文件中都有内容要改,而且是不同的内容。。。
在汉化新世纪上看到了这款软件的最新版,觉得应该与大家共享一下,于是贴出来,呵呵。
原文地址,有两个,我也不知道哪个汉化的更好:
http://www.hanzify.org/index.php?Go=Show::List&ID=12180
http://www.hanzify.org/index.php?Go=Show::List&ID=11396
版本更新(从5.0的开始):
更新记录
- Version 6.0
-
- * Unicode support in User Interface.
- * Asian text support greatly improved.
- * x64 version available
-
- Version 5.9
-
- * Additional support for Windows Vista
-
- Version 5.8
-
- * Debugging report support.
-
- Version 5.7
-
- * Switch to list a hit line only once even it contains multiple hits. See Options|Display.
-
- Version 5.6
-
- * Limit of 4 GB maximum file size for single file removed.
- * Added special 'Show Hits on one line' function. See F1 hlp - Index|Registry Switches
-
- Version 5.5
-
- * Additional handling added to script editor for 'Repeat Script' function. Previously this had to be entered manually.
-
- Version 5.4
-
- * 'Repeat action' n-times added for search/replaces in scripts to let you repeat search/replaces any number of times. See F1 hlp. This field is available from the 'Comments' button in the Script Editor.
-
- Version 5.3
-
- * Enhanced instance handling. When in multiple instance mode the window title bars are distinguished :2, :3, etc. See Options|General.
- * The file name extension(s) for .xml files can be adjusted. See F1 hlp - 'Registry Switches'.
-
- Version 5.2
-
- *
-
- Switch to copy (or not) search header info the clipboard and output file. See Options|Display.
- * "Buffer Size" can now be specified in Options|Search.
- * Special switch to control number of buffers to process. See F1 Hlp - 'Registry Switches'.
-
- Version 5.1
-
- *
-
- "Filter" indicator in main window when a filter is established in Options | Filters.
- * "Privacy" switches to delete program history upon exit. See F1 Hlp - "Privacy Settings" for info.
- * "Process Binary Files" switch in Options|Search.
-
- Version 5.0
-
- *
-
- Enhanced File Operations dialog with drag n drop to Windows Explorer and context menu.
- * Additional keyboard shortcuts.
- * Special switch to cause program to not search 'binary' files.
- * Special switch to not output search parameters during Ctrl+C copy to clipboard in Search Results
- * 'Explorer From Here' to launch Windows Explorer
很少看到介绍SPL的文章,难得看到一篇,转摘,记录一下,原文地址:http://www.phpobject.net/blog/read.php/140.htm
PHP SPL笔记
目录
第一部分 简介
1. 什么是SPL?
2. 什么是Iterator?
第二部分 SPL Interfaces
3. Iterator界面
4. ArrayAccess界面
5. IteratorAggregate界面
6. RecursiveIterator界面
7. SeekableIterator界面
8. Countable界面
第三部分 SPL Classes
9. SPL的内置类
10. DirectoryIterator类
11. ArrayObject类
12. ArrayIterator类
13. RecursiveArrayIterator类和RecursiveIteratorIterator类
14. FilterIterator类
15. SimpleXMLIterator类
16. CachingIterator类
17. LimitIterator类
18. SplFileObject类
第一部 简介
1. 什么是SPL?
SPL是Standard PHP Library(PHP标准库)的缩写。
根据官方定义,它是“a collection of interfaces and classes that are meant to solve standard problems”。但是,目前在使用中,SPL更多地被看作是一种使object(物体)模仿array(数组)行为的interfaces和 classes。
2. 什么是Iterator?
SPL的核心概念就是Iterator。这指的是一种Design Pattern,根据《Design Patterns》一书的定义,Iterator的作用是“provide an object which traverses some aggregate structure, abstracting away assumptions about the implementation of that structure.”
wikipedia中说,"an iterator is an object which allows a programmer to traverse through all the elements of a collection, regardless of its specific implementation".……"the iterator pattern is a design pattern in which iterators are used to access the elements of an aggregate object sequentially without exposing its underlying representation".
通俗地说,Iterator能够使许多不同的数据结构,都能有统一的操作界面,比如一个数据库的结果集、同一个目录中的文件集、或者一个文本中每一行构成的集合。
如果按照普通情况,遍历一个MySQL的结果集,程序需要这样写:
PHP代码
-
- $result = mysql_query("SELECT * FROM users");
-
- while ( $row = mysql_fetch_array($result) ) {
-
- }
读出一个目录中的内容,需要这样写:
PHP代码
-
- $dh = opendir('/home/harryf/files');
-
- while ( $file = readdir($dh) ) {
-
- }
读出一个文本文件的内容,需要这样写:
PHP代码
-
- $fh = fopen("/home/hfuecks/files/results.txt", "r");
-
- while (!feof($fh)) {
- $line = fgets($fh);
-
- }
上面三段代码,虽然处理的是不同的resource(资源),但是功能都是遍历结果集(loop over contents),因此Iterator的基本思想,就是将这三种不同的操作统一起来,用同样的命令界面,处理不同的资源。
第二部分 SPL Interfaces
3. Iterator界面
SPL规定,所有部署了Iterator界面的class,都可以用在foreach Loop中。Iterator界面中包含5个必须部署的方法:
* current()
This method returns the current index’s value. You are solely
responsible for tracking what the current index is as the
interface does not do this for you.
* key()
This method returns the value of the current index’s key. For
foreach loops this is extremely important so that the key
value can be populated.
* next()
This method moves the internal index forward one entry.
* rewind()
This method should reset the internal index to the first element.
* valid()
This method should return true or false if there is a current
element. It is called after rewind() or next().
下面就是一个部署了Iterator界面的class示例:
PHP代码
-
-
-
-
-
- class ArrayReloaded implements Iterator {
-
-
-
- private $array = array();
-
-
-
- private $valid = FALSE;
-
-
-
-
- function __construct($array) {
- $this->array = $array;
- }
-
-
-
-
- function rewind(){
- $this->valid = (FALSE !== reset($this->array));
- }
-
-
-
- function current(){
- return current($this->array);
- }
-
-
-
- function key(){
- return key($this->array);
- }
-
-
-
-
- function next(){
- $this->valid = (FALSE !== next($this->array));
- }
-
-
-
- function valid(){
- return $this->valid;
- }
- }
使用方法如下:
PHP代码
-
- $colors = new ArrayReloaded(array ('red','green','blue',));
-
- foreach ( $colors as $color ) {
- echo $color."\n";
- }
你也可以在foreach循环中使用key()方法:
PHP代码
-
- foreach ( $colors as $key => $color ) {
- echo "$key: $color";
- }
除了foreach循环外,也可以使用while循环,
PHP代码
-
- $colors->rewind();
-
- while ( $colors->valid() ) {
- echo $colors->key().": ".$colors->current()."
- ";
- $colors->next();
- }
根据测试,while循环要稍快于foreach循环,因为运行时少了一层中间调用。
4. ArrayAccess界面
部署ArrayAccess界面,可以使得object像array那样操作。ArrayAccess界面包含四个必须部署的方法:
* offsetExists($offset)
This method is used to tell php if there is a value
for the key specified by offset. It should return
true or false.
* offsetGet($offset)
This method is used to return the value specified
by the key offset.
* offsetSet($offset, $value)
This method is used to set a value within the object,
you can throw an exception from this function for a
read-only collection.
* offsetUnset($offset)
This method is used when a value is removed from
an array either through unset() or assigning the key
a value of null. In the case of numerical arrays, this
offset should not be deleted and the array should
not be reindexed unless that is specifically the
behavior you want.
下面就是一个部署ArrayAccess界面的实例:
PHP代码
-
-
-
- class Article implements ArrayAccess {
- public $title;
- public $author;
- public $category;
- function __construct($title,$author,$category) {
- $this->title = $title;
- $this->author = $author;
- $this->category = $category;
- }
-
-
-
-
-
-
-
- function offsetSet($key, $value) {
- if ( array_key_exists($key,get_object_vars($this)) ) {
- $this->{$key} = $value;
- }
- }
-
-
-
-
-
-
- function offsetGet($key) {
- if ( array_key_exists($key,get_object_vars($this)) ) {
- return $this->{$key};
- }
- }
-
-
-
-
-
-
- function offsetUnset($key) {
- if ( array_key_exists($key,get_object_vars($this)) ) {
- unset($this->{$key});
- }
- }
-
-
-
-
-
-
- function offsetExists($offset) {
- return array_key_exists($offset,get_object_vars($this));
- }
- }
使用方法如下:
PHP代码
-
- $A = new Article('SPL Rocks','Joe Bloggs', 'PHP');
-
- echo 'Initial State:';
- print_r($A);
- echo "\n";
-
- $A['title'] = 'SPL _really_ rocks';
-
- $A['not found'] = 1;
-
- unset($A['author']);
-
- echo 'Final State:';
- print_r($A);
- echo "\n";
运行结果如下:
Initial State:
Article Object
(
[title] => SPL Rocks
[author] => Joe Bloggs
[category] => PHP
)
Final State:
Article Object
(
[title] => SPL _really_ rocks
[category] => PHP
)
可以看到,$A虽然是一个object,但是完全可以像array那样操作。
你还可以在读取数据时,增加程序内部的逻辑:
PHP代码
- function offsetGet($key) {
- if ( array_key_exists($key,get_object_vars($this)) ) {
- return strtolower($this->{$key});
- }
- }
5. IteratorAggregate界面
但是,虽然$A可以像数组那样操作,却无法使用foreach遍历,除非部署了前面提到的Iterator界面。
另一个解决方法是,有时会需要将数据和遍历部分分开,这时就可以部署IteratorAggregate界面。它规定了一个getIterator()方法,返回一个使用Iterator界面的object。
还是以上一节的Article类为例:
PHP代码
- class Article implements ArrayAccess, IteratorAggregate {
-
-
-
-
-
- function getIterator() {
- return new ArrayIterator($this);
- }
使用方法如下:
PHP代码
- $A = new Article('SPL Rocks','Joe Bloggs', 'PHP');
-
- echo 'Looping with foreach:';
- foreach ( $A as $field => $value ) {
- echo "$field : $value";
- }
- echo '';
-
- echo "Object has ".sizeof($A->getIterator())." elements";
显示结果如下:
Looping with foreach:
title : SPL Rocks
author : Joe Bloggs
category : PHP
Object has 3 elements
6. RecursiveIterator界面
这个界面用于遍历多层数据,它继承了Iterator界面,因而也具有标准的current()、key()、next()、 rewind()和valid()方法。同时,它自己还规定了getChildren()和hasChildren()方法。The getChildren() method must return an object that implements RecursiveIterator.
7. SeekableIterator界面
SeekableIterator界面也是Iterator界面的延伸,除了Iterator的5个方法以外,还规定了seek()方法,参数是元素的位置,返回该元素。如果该位置不存在,则抛出OutOfBoundsException。
下面是一个是实例:
PHP代码
- class PartyMemberIterator implements SeekableIterator
- {
- public function __construct(PartyMember $member)
- {
-
- }
- public function seek($index)
- {
- $this->rewind();
- $position = 0;
- while ($position < $index && $this->valid()) {
- $this->next();
- $position++;
- }
- if (!$this->valid()) {
- throw new OutOfBoundsException('Invalid position');
- }
- }
-
-
- }
8. Countable界面
这个界面规定了一个count()方法,返回结果集的数量。
第三部分 SPL Classes
9. SPL的内置类
SPL除了定义一系列Interfaces以外,还提供一系列的内置类,它们对应不同的任务,大大简化了编程。
查看所有的内置类,可以使用下面的代码:
PHP代码
-
- foreach(spl_classes() as $key=>$value)
- {
- echo $key.' -> '.$value.'';
- }
10. DirectoryIterator类
这个类用来查看一个目录中的所有文件和子目录:
PHP代码
- try{
-
- foreach ( new DirectoryIterator('./') as $Item )
- {
- echo $Item.'';
- }
- }
-
- catch(Exception $e){
- echo 'No files Found!';
- }
查看文件的详细信息:
PHP代码
- foreach(new DirectoryIterator('./' ) as $file )
- {
- if( $file->getFilename() == 'foo.txt' )
- {
- echo ' getFilename() '; var_dump($file->getFilename()); echo ' ';
- echo ' getBasename() '; var_dump($file->getBasename()); echo ' ';
- echo ' isDot() '; var_dump($file->isDot()); echo ' ';
- echo ' __toString() '; var_dump($file->__toString()); echo ' ';
- echo ' getPath() '; var_dump($file->getPath()); echo ' ';
- echo ' getPathname() '; var_dump($file->getPathname()); echo ' ';
- echo ' getPerms() '; var_dump($file->getPerms()); echo ' ';
- echo ' getInode() '; var_dump($file->getInode()); echo ' ';
- echo ' getSize() '; var_dump($file->getSize()); echo ' ';
- echo ' getOwner() '; var_dump($file->getOwner()); echo ' ';
- echo ' $file->getGroup() '; var_dump($file->getGroup()); echo ' ';
- echo ' getATime() '; var_dump($file->getATime()); echo ' ';
- echo ' getMTime() '; var_dump($file->getMTime()); echo ' ';
- echo ' getCTime() '; var_dump($file->getCTime()); echo ' ';
- echo ' getType() '; var_dump($file->getType()); echo ' ';
- echo ' isWritable() '; var_dump($file->isWritable()); echo ' ';
- echo ' isReadable() '; var_dump($file->isReadable()); echo ' ';
- echo ' isExecutable( '; var_dump($file->isExecutable()); echo ' ';
- echo ' isFile() '; var_dump($file->isFile()); echo ' ';
- echo ' isDir() '; var_dump($file->isDir()); echo ' ';
- echo ' isLink() '; var_dump($file->isLink()); echo ' ';
- echo ' getFileInfo() '; var_dump($file->getFileInfo()); echo ' ';
- echo ' getPathInfo() '; var_dump($file->getPathInfo()); echo ' ';
- echo ' openFile() '; var_dump($file->openFile()); echo ' ';
- echo ' setFileClass() '; var_dump($file->setFileClass()); echo ' ';
- echo ' setInfoClass() '; var_dump($file->setInfoClass()); echo ' ';
- }
- }
除了foreach循环外,还可以使用while循环:
PHP代码
-
- $it = new DirectoryIterator('./');
-
- while($it->valid())
- {
- echo $it->key().' -- '.$it->current().' ';
-
- $it->next();
- }
如果要过滤所有子目录,可以在valid()方法中过滤:
PHP代码
-
- $it = new DirectoryIterator('./');
-
- while($it->valid())
- {
-
- if($it->isDir())
- {
-
- echo $it->key().' -- '.$it->current().'';
- }
-
- $it->next();
- }
11. ArrayObject类
这个类可以将Array转化为object。
PHP代码
-
- $array = array('koala', 'kangaroo', 'wombat', 'wallaby', 'emu', 'kiwi', 'kookaburra', 'platypus');
-
- $arrayObj = new ArrayObject($array);
-
- for($iterator = $arrayObj->getIterator();
-
- $iterator->valid();
-
- $iterator->next())
- {
-
- echo $iterator->key() . ' => ' . $iterator->current() . '';
- }
增加一个元素:
$arrayObj->append('dingo');
对元素排序:
$arrayObj->natcasesort();
显示元素的数量:
echo $arrayObj->count();
删除一个元素:
$arrayObj->offsetUnset(5);
某一个元素是否存在:
if ($arrayObj->offsetExists(3))
{
echo 'Offset Exists';
}
更改某个位置的元素值:
$arrayObj->offsetSet(5, "galah");
显示某个位置的元素值:
echo $arrayObj->offsetGet(4);
12. ArrayIterator类
这个类实际上是对ArrayObject类的补充,为后者提供遍历功能。
示例如下:
PHP代码
-
- $array = array('koala', 'kangaroo', 'wombat', 'wallaby', 'emu', 'kiwi', 'kookaburra', 'platypus');
- try {
- $object = new ArrayIterator($array);
- foreach($object as $key=>$value)
- {
- echo $key.' => '.$value.'';
- }
- }
- catch (Exception $e)
- {
- echo $e->getMessage();
- }
-
- rayIterator类也支持offset类方法和count()方法:
-
-
- $array = array('koala', 'kangaroo', 'wombat', 'wallaby', 'emu', 'kiwi', 'kookaburra', 'platypus');
- try {
- $object = new ArrayIterator($array);
-
- if($object->offSetExists(2))
- {
-
- $object->offSetSet(2, 'Goanna');
- }
-
- foreach($object as $key=>$value)
- {
-
- if($object->offSetGet($key) === 'kiwi')
- {
-
- $object->offSetUnset($key);
- }
- echo ''.$key.' - '.$value.''."\n";
- }
- }
- catch (Exception $e)
- {
- echo $e->getMessage();
- }
?>
13. RecursiveArrayIterator类和RecursiveIteratorIterator类
ArrayIterator类和ArrayObject类,只支持遍历一维数组。如果要遍历多维数组,必须先用 RecursiveIteratorIterator生成一个Iterator,然后再对这个Iterator使用 RecursiveIteratorIterator。
PHP代码
- $array = array(
- array('name'=>'butch', 'sex'=>'m', 'breed'=>'boxer'),
- array('name'=>'fido', 'sex'=>'m', 'breed'=>'doberman'),
- array('name'=>'girly','sex'=>'f', 'breed'=>'poodle')
- );
- foreach(new RecursiveIteratorIterator(new RecursiveArrayIterator($array)) as $key=>$value)
- {
- echo $key.' -- '.$value.'';
- }
14. FilterIterator类
FilterIterator类可以对元素进行过滤,只要在accept()方法中设置过滤条件就可以了。
示例如下:
PHP代码
-
- $animals = array('koala', 'kangaroo', 'wombat', 'wallaby', 'emu', 'NZ'=>'kiwi', 'kookaburra', 'platypus');
- class CullingIterator extends FilterIterator{
-
- public function __construct( Iterator $it ){
- parent::__construct( $it );
- }
-
- function accept(){
- return is_numeric($this->key());
- }
- }
- $cull = new CullingIterator(new ArrayIterator($animals));
- foreach($cull as $key=>$value)
- {
- echo $key.' == '.$value.'';
- }
- ?>
-
-
- class PrimeFilter extends FilterIterator{
-
- public function __construct(Iterator $it){
- parent::__construct($it);
- }
-
- function accept(){
- if($this->current() % 2 != 1)
- {
- return false;
- }
- $d = 3;
- $x = sqrt($this->current());
- while ($this->current() % $d != 0 && $d < $x)
- {
- $d += 2;
- }
- return (($this->current() % $d == 0 && $this->current() != $d) * 1) == 0 ? true : false;
- }
- }
-
- $numbers = range(212345,212456);
-
- $primes = new primeFilter(new ArrayIterator($numbers));
- foreach($primes as $value)
- {
- echo $value.' is prime.';
- }
15. SimpleXMLIterator类
这个类用来遍历xml文件。
示例如下:
原文的XML在就是变型的,或者说在解释的时候已经坏掉了,所以。我删除了,直接看方法吧:by 膘叔
PHP代码
-
- try {
-
- $it = new SimpleXMLIterator($xmlstring);
-
- foreach(new RecursiveIteratorIterator($it,1) as $name => $data)
- {
- echo $name.' -- '.$data.'';
- }
- }
- catch(Exception $e)
- {
- echo $e->getMessage();
- }
new RecursiveIteratorIterator($it,1)表示显示所有包括父元素在内的子元素。
显示某一个特定的元素值,可以这样写:
PHP代码
- try {
-
- $sxi = new SimpleXMLIterator($xmlstring);
- foreach ( $sxi as $node )
- {
- foreach($node as $k=>$v)
- {
- echo $v->species.'';
- }
- }
- }
- catch(Exception $e)
- {
- echo $e->getMessage();
- }
相对应的while循环写法为:
PHP代码
- try {
- $sxe = simplexml_load_string($xmlstring, 'SimpleXMLIterator');
- for ($sxe->rewind(); $sxe->valid(); $sxe->next())
- {
- if($sxe->hasChildren())
- {
- foreach($sxe->getChildren() as $element=>$value)
- {
- echo $value->species.'';
- }
- }
- }
- }
- catch(Exception $e)
- {
- echo $e->getMessage();
- }
最方便的写法,还是使用xpath:
PHP代码
- try {
-
- $sxi = new SimpleXMLIterator($xmlstring);
-
- $foo = $sxi->xpath('animal/category/species');
-
- foreach ($foo as $k=>$v)
- {
- echo $v.'';
- }
- }
- ch(Exception $e)
- {
- echo $e->getMessage();
- }
下面的例子,显示有namespace的情况:
PHP代码
-
- try {
-
- $sxi = new SimpleXMLIterator($xmlstring);
- $sxi-> registerXPathNamespace('spec', 'http://www.exampe.org/species-title');
-
- $result = $sxi->xpath('//spec:name');
-
- foreach($sxi->getDocNamespaces('animal') as $ns)
- {
- echo $ns.'';
- }
-
- foreach ($result as $k=>$v)
- {
- echo $v.'';
- }
- }
- catch(Exception $e)
- {
- echo $e->getMessage();
- }
增加一个节点:
PHP代码
- try {
-
- $sxi = new SimpleXMLIterator($xmlstring);
-
- $sxi->addChild('animal', 'Tiger');
-
- $new = new SimpleXmlIterator($sxi->saveXML());
-
- foreach($new as $val)
- {
- echo $val.'';
- }
- }
- catch(Exception $e)
- {
- echo $e->getMessage();
- }
增加属性:
PHP代码
- try {
-
- $sxi = new SimpleXMLIterator($xmlstring);
-
- $sxi->addAttribute('id:att1', 'good things', 'urn::test-foo');
-
- $sxi->addAttribute('att2', 'no-ns');
- echo htmlentities($sxi->saveXML());
- }
- catch(Exception $e)
- {
- echo $e->getMessage();
- }
16. CachingIterator类
这个类有一个hasNext()方法,用来判断是否还有下一个元素。
示例如下:
PHP代码
-
- $array = array('koala', 'kangaroo', 'wombat', 'wallaby', 'emu', 'kiwi', 'kookaburra', 'platypus');
- try {
-
- $object = new CachingIterator(new ArrayIterator($array));
- foreach($object as $value)
- {
- echo $value;
- if($object->hasNext())
- {
- echo ',';
- }
- }
- }
- catch (Exception $e)
- {
- echo $e->getMessage();
- }
17. LimitIterator类
这个类用来限定返回结果集的数量和位置,必须提供offset和limit两个参数,与SQL命令中limit语句类似。
示例如下:
PHP代码
-
- $offset = 3;
-
- $limit = 2;
- $array = array('koala', 'kangaroo', 'wombat', 'wallaby', 'emu', 'kiwi', 'kookaburra', 'platypus');
- $it = new LimitIterator(new ArrayIterator($array), $offset, $limit);
- foreach($it as $k=>$v)
- {
- echo $it->getPosition().'';
- }
另一个例子是:
PHP代码
-
- $array = array('koala', 'kangaroo', 'wombat', 'wallaby', 'emu', 'kiwi', 'kookaburra', 'platypus');
- $it = new LimitIterator(new ArrayIterator($array));
- try
- {
- $it->seek(5);
- echo $it->current();
- }
- catch(OutOfBoundsException $e)
- {
- echo $e->getMessage() . "";
- }
18. SplFileObject类
这个类用来对文本文件进行遍历。
示例如下:
PHP代码
- try{
-
- foreach( new SplFileObject("/usr/local/apache/logs/access_log") as $line)
-
- echo $line.'';
- }
- catch (Exception $e)
- {
- echo $e->getMessage();
- }
返回文本文件的第三行,可以这样写:
PHP代码
- try{
- $file = new SplFileObject("/usr/local/apache/logs/access_log");
- $file->seek(3);
- echo $file->current();
- }
- catch (Exception $e)
- {
- echo $e->getMessage();
- }
[参考文献]
1. Introduction to Standard PHP Library (SPL), By Kevin Waterson
2. Introducing PHP 5's Standard Library, By Harry Fuecks
3. The Standard PHP Library (SPL), By Ben Ramsey
4. SPL - Standard PHP Library Documentation
说起C&C,只要年龄不是太小的,基本上应该都听过的吧,几乎是如今这类游戏的开山鼻祖了,为了这款游戏,PS上玩过,PC上玩过,当然,再往后的时候玩的大多是红警了。
由于一系列的原因,红警在国内是不能销售的。软件的到来就可想而知了,不过这并不影响我们在网吧的通宵娱乐。RA2也曾经让我们很沉迷,但RA系列一直就是有一个垢病:机器越好,速度越快。。。
本来想不到提这些,这段时间每个QQ群里几乎都在谈论RA3,而PHPRPC群里的legend更是从淘宝上购买了RA3的港版,并在自己的博客进行了炫耀:RA3入手,打开cnbeta,又发现有人在贴红警历史,复制上来和大家一起分享.
http://www.cnbeta.com/articles/68631.htm
- 无意间看到有同学问命令与征服和红色警戒有啥关系,特意从网络搜集到一些资料,大家看看。命令与征服,英文名Commandand&Conquer,简称C&C或者CNC,是美国西木头工作室(WestwoodStudios)为个人电脑发行的一系列即时战略游戏(RTS,Real-Time Strategy)。美国艺电(ElectronicArts)收购西木头之后,将本系列扩张成数个系列的共同商标。本系列游戏是史上最畅销的即时战略游戏,发行量已超过3500万套。
-
-
- 时代的开创者总是会受人尊敬,让即时战略游戏声名鹊起,一下子成为了最流行的游戏类型之一,命令与征服功不可没,西木头在沙丘魔堡2(Dune2)开创了 即时战略,然后在之后的命令与征服,为后世所有即时战略游戏树立了即时战略游戏的样板,C&C率先创造的“资源采集+生产建设+兵团作战”的架 构,大地图迷雾和单位迷雾的区分,一次性迷雾[Dune2]和可恢复迷雾[CNC1]以及永久性迷雾[Rad1],创造并且定义了“战争迷雾”;不论是 3S还是战争迷雾,一直沿用到现在几乎所有即时战略游戏中.并且它开创了真人电影的先河,所有的作品除了《将军》外,都有由真人饰演的电影,这一点是即时 战略游戏界极为少有的。
-
- 游戏简介:
- 命令与征服,英文名Commandand&Conquer,简称C&C或者CNC,是美国西木头工作室(WestwoodStudios)为个人电脑发行的一系列即时战略游戏(RTS,Real-Time Strategy)。美国艺电(ElectronicArts)收购西木头之后,将本系列扩张成数个系列的共同商标。本系列游戏是史上最畅销的即时战略游戏,发行量已超过3500万套。时代的开创者总是会受人尊敬,让即时战略游戏声名鹊起,一下子成为了最流行的游戏类型之一,命令与征服功不可没,西木头在沙丘魔堡2(Dune2)开创了即时战略,然后在之后的命令与征服,为后世所有即时战略游戏树立了即时战略游戏的样板,C&C率先创造的“资源采集+生产建设+兵团作战”的架构,大地图迷雾和单位迷雾的区分,一次性迷雾[Dune2]和可恢复迷雾[CNC1]以及永久性迷雾[Rad1],创造并且定义了“战争迷雾”;不论是3S还是战争迷雾,一直沿用到现在几乎所有即时战略游戏中.并且它开创了真人电影的先河,所有的作品除了《将军》外,都有由真人饰演的电影,这一点是即时战略游戏界极为少有的。
-
- 内容简介:
- 命令与征服一共出现过3个系列包括本传系列(即泰伯利亚系列,包括叛逆者,有些人以为叛逆者是独自一个系列,但是叛逆者用的是C&C1的剧情)、红警系列(红色警戒是本传的前传,红色警戒2是在一个新的时空中发生的,与红警1和泰伯利亚系列无关)、将军系列。联系剧情讲,本传系列与红警系列处于的宇宙是爱因斯坦为避免第二次世界大战发生,进行时空旅行消灭了希特勒而造就的不同于将军系列的时空,因此在红警系列的剧情里,没有发生我们历史上纳粹发动的第二次世界大战,而发生的是苏联发动的超级世界大战(这也就是为什么我们封杀红警系列的原因);而将军的剧情则是按照我们现在的历史,或者说发生在我们现在的宇宙,中、美、恐怖组织之间的剧情。红警系列与本传系列的联系在于,红警1中,盟军胜利后,斯大林的助手凯恩没有被处死(实际上,在苏军胜利,占领伦敦之后,斯大林在振臂高呼的同时,却被凯恩秘密地毒死,女助手发表演讲被凯恩从背后杀死,之后发表了一小段演说,同样可以作为本专系列的前传),逃逸后成立了NOD兄弟会(关于凯恩的年龄,本传中也介绍了凯恩不老不死,这也就解释了凯恩可以跨两个系列近一个世纪存在),而红警系列中的盟军可以就是全球防御组织(GDI)的前身。
-
- 系列游戏:
- Command & Conquer (命令与征服1,1995年8月)
- Command & Conquer:TheCovertOperations(隐秘行动,1996年4月)
- Command & Conquer:RedAlert (红色警戒,1996年10月)
- Command & Conquer:RedAlertTheAftermath (红色警戒之突发事件,1997年9月)
- Command & Conquer:RedAlertCounterstrike (红色警戒之危机任务,1997年3月)
- Command & Conquer:TiberianSun (泰伯利亚之日,1999年8月)
- Command & Conquer:TiberianSunFirestorm (泰伯利亚之日之火线风暴,2000年2月)
- Command & Conquer:RedAlert2 (红色警戒2,2000年10月)
- Command & Conquer:RedAlert2Yuri's Revenge (红色警戒2:尤里的复仇,2001年10月)
- Command & Conquer:Renegade (变节者,2002年2月)
- Command & Conquer:Generals (将军,2003年2月)
- Command & Conquer:GeneralsZeroHour (将军之绝命时刻,2003年9月)
- Command & Conquer:TiberianTwilight (泰伯利亚之黄昏,因Westwood被解散而并未发行)
- Command & Conquer3:Tiberium Wars (命令与征服3:泰伯利亚之战,2007年3月)
- Command & Conquer3:Kane's Wrath (命令与征服3:凯恩之怒,2008年3月)
- Command & Conquer3:Tiberium (泰伯利亚,2008年底)
- Command & Conquer:RedAlert3 (命令与征服:红色警戒3,2008年10月)


