Submitted by gouki on 2009, March 9, 4:40 PM
在使用swfupload上传文件的时候,老是绕不过登录验证。查了一下GOOGLe,没查到,问了百度,他告诉我答案:
swfuplaod在上传时,会新开一个进程,和原来的进程不一致,要解决这个问题,需要指定session_id,然后在登录页面判断,如果有post过来的session_id,那么就用函数session_id( $_POST['PHP_SESSIONID'])指定一下。
上传页的JS里面,可以获取当前的SESSION_ID的。
例如上传页的JS中:
post_params: {"PHPSESSID": "<?php echo session_id(); ?>"},
在验证的判断页中:
if (isset($_POST["PHPSESSID"])) {
session_id($_POST["PHPSESSID"]);
}
(这一段是网上的注释:在带有Session验证的网站后台中SWFUpload无法正常工作,这是因为SWFUpload在上传时相当于重新开辟了一个新的Session 进程,因此无法与原有程序的Session保持一致,这就需要在上传时传递原有程序的SessionID,根据它来“找回”其应有的Session。)
图片附件(缩略图):

Tags: swfupload
PHP | 评论:3
| 阅读:34176
Submitted by gouki on 2009, March 8, 9:16 AM
首页只放一张,详情页还有更多哦

» 阅读全文
Tags: 肖佑阳, 坐立
Scala & Ruby | 评论:0
| 阅读:27335
Submitted by gouki on 2009, March 7, 11:31 PM
wps是我喜爱的国产软件之一,听说升级到2009了,兴冲冲的到网站上去下载。
进入:http://www.wps.cn/product/index.htm,我想我应该没有理解错网站的意思,于是我先下载了升级包,结果失败,说我是最新版,我想2007大概不能升级到2009吧,然后就下载了直接的安装包。安装时提醒我说有旧软件要删除,兴奋呀。。
安装好后一运行 ,MD,还是2007.晕了我
看来是我RP太差了吧。
图片附件(缩略图):
Tags: wps
Software | 评论:1
| 阅读:22567
Submitted by gouki on 2009, March 7, 9:58 PM
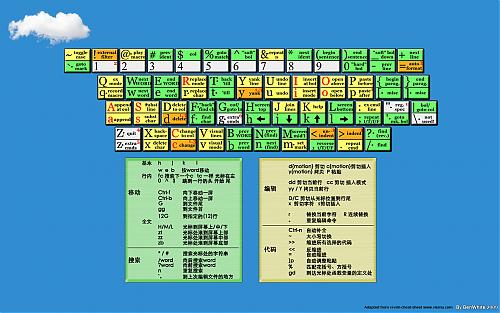
在很久前,我与大家分享过一张VI/VIM的操作键位图,那张相对较小一点,如今,发现两张大的,再放上来与君共享。(下载不在本地,如果是图片,那么点击小图,可以查看大图,已经本地版了,呵呵)
原文:http://www.cnitblog.com/benwhite/archive/2009/03/06/55167.html
内容:
近来心血来潮,想成为一个Vimer,于是开始发愤使用,但是新手的普遍问题就是常常在纷繁的命令中发懵,于是我想到了著名的vi-vim-cheat-sheet(ywpg推荐的),另外也找到了两张全黑的国人做的命令壁纸,但是两者均有失偏颇,不如干脆来个整合,做一个新版的壁纸。经过两个多小时,成果如下:(考虑到宽屏的童鞋,一并提供宽屏版)[由于都是很简单的命令,初学者下,高手请绕道:P]
打包下载 或 直接点击下面图片
1024x768
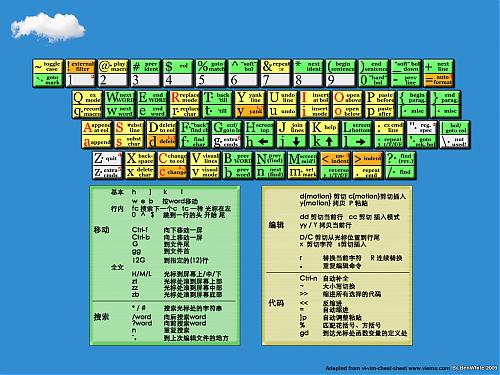
1680x1050

版权说明:本版本主要是从www.viemu.com 的cheat sheet改编,我想原作者会同意的,毕竟这是推广一个vi/vim的举动,顺便也替他做了广告:)
Tags: vim, linux
Software | 评论:2
| 阅读:38485
Submitted by gouki on 2009, March 6, 9:00 AM
原文:http://www.javauu.com/thread-4678-1-1.html
如果您正在运行使用MySQL的Web应用程序,那么它把密码或者其他敏感信息保存在应用程序里的机会就很大。保护这些数据免受黑客或者窥探者的获取是一个令人关注的重要问题,因为您既不能让未经授权的人员使用或者破坏应用程序,同时还要保证您的竞争优势。幸运的是,MySQL带有很多设计用来提供这种类型安全的加密函数。本文概述了其中的一些函数,并说明了如何使用它们,以及它们能够提供的不同级别的安全。
双向加密
就让我们从最简单的加密开始:双向加密。在这里,一段数据通过一个密钥被加密,只能够由知道这个密钥的人来解密。MySQL有两个函数来支持这种类型的加密,分别叫做ENCODE()和DECODE()。下面是一个简单的实例:
mysql> INSERT INTO users (username, password) VALUES ('joe', ENCODE('guessme', 'abracadabra'));
Query OK, 1 row affected (0.14 sec)
其中,Joe的密码是guessme,它通过密钥abracadabra被加密。要注意的是,加密完的结果是一个二进制字符串,如下所示:
mysql> SELECT * FROM users WHERE username='joe';
+----------+----------+
| username | password |
+----------+----------+
| joe | ¡?i??!? |
+----------+----------+
1 row in set (0.02 sec)
abracadabra这个密钥对于恢复到原始的字符串至关重要。这个密钥必须被传递给DECODE()函数,以获得原始的、未加密的密码。下面就是它的使用方法:
mysql> SELECT DECODE(password, 'abracadabra') FROM users WHERE username='joe';
+---------------------------------+
| DECODE(password, 'abracadabra') |
+---------------------------------+
| guessme |
+---------------------------------+
1 row in set (0.00 sec)
应该很容易就看到它在Web应用程序里是如何运行的――在验证用户登录的时候,DECODE()会用网站专用的密钥解开保存在数据库里的密码,并和用户输入的内容进行对比。假设您把PHP用作自己的脚本语言,那么可以像下面这样进行查询:
$query = "SELECT COUNT(*) FROM users WHERE username='$inputUser' AND DECODE(password, 'abracadabra') = '$inputPass'";?>
提示:虽然ENCODE()和DECODE()这两个函数能够满足大多数的要求,但是有的时候您希望使用强度更高的加密手段。在这种情况下,您可以使用AES_ENCRYPT()和AES_DECRYPT()函数,它们的工作方式是相同的,但是加密强度更高。
单向加密
单向加密与双向加密不同,一旦数据被加密就没有办法颠倒这一过程。因此密码的验证包括对用户输入内容的重新加密,并将它与保存的密文进行比对,看是否匹配。一种简单的单向加密方式是MD5校验码。MySQL的MD5()函数会为您的数据创建一个“指纹”并将它保存起来,供验证测试使用。下面就是如何使用它的一个简单例子:
mysql> INSERT INTO users (username, password) VALUES ('joe', MD5('guessme'));
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM users WHERE username='joe';
+----------+----------------------------------+
| username | password |
+----------+----------------------------------+
| joe | 81a58e89df1f34c5487568e17327a219 |
+----------+----------------------------------+
1 row in set (0.02 sec)
现在您可以测试用户输入的内容是否与已经保存的密码匹配,方法是取得用户输入密码的MD5校验码,并将它与已经保存的密码进行比对,就像下面这样:
mysql> SELECT COUNT(*) FROM users WHERE username='joe' AND password=MD5('guessme');
+----------+
| COUNT(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
或者,您考虑一下使用ENCRYPT()函数,它使用系统底层的crypt()系统调用来完成加密。这个函数有两个参数:一个是要被加密的字符串,另一个是双(或者多)字符的“salt”。它然后会用salt加密字符串;这个salt然后可以被用来再次加密用户输入的内容,并将它与先前加密的字符串进行比对。下面一个例子说明了如何使用它:
mysql> INSERT INTO users (username, password) VALUES ('joe', ENCRYPT('guessme', 'ab'));
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM users WHERE username='joe';
+----------+---------------+
| username | password |
+----------+---------------+
| joe | ab/G8gtZdMwak |
+----------+---------------+
1 row in set (0.00 sec)
结果是
mysql> SELECT COUNT(*) FROM users WHERE username='joe' AND password=ENCRYPT('guessme', 'ab');
+----------+
| COUNT(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
提示:ENCRYPT()只能用在*NIX系统上,因为它需要用到底层的crypt()库。
幸运的是,上面的例子说明了能够如何利用MySQL对您的数据进行单向和双向的加密,并告诉了您一些关于如何保护数据库和其他敏感数据库信息安全的理念。
Tags: mysql, 加密函数
Baby | 评论:0
| 阅读:23549


