正如标题所说:奇怪的题目,妖异的答案,出题者,你在哪里?
题目的下面还写着一年级数学,尼妹啊,一年级数学是这样的?
题目大家应该都见过:
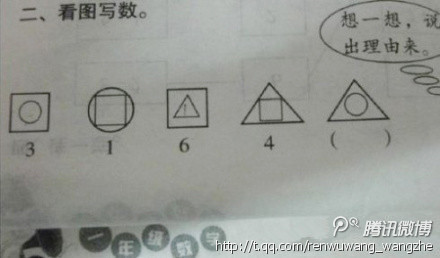
一些智商测试中偶尔也会有这种类似的图。答案是什么?
真的是加减法吗?
你看看这些答案你就知道了,原来,你小学也可能真的没毕业,当年你是怎么毕业的?


 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
浏览模式: 标准 | 列表全部文章
奇怪的题目,妖异的答案,出题者,你在哪里?
Submitted by gouki on 2012, October 30, 11:01 AM
针对品鉴网的一些URL路由设置
Submitted by gouki on 2012, October 29, 1:20 PM
这篇文章又能当成开发文档,也能当成软文,所以,你们就将就着看吧。
yii框架中很早就支持路由功能了。所以,从那时候开始,很多人就开始将项目路由化,举例说明:
http://user.pinjian.net,访问用户中心
http://admin.pinjian.net 访问后台
http://xxxx.pinjian.net 访问Xxx
表面上这是一大堆 网站,其实很有可能是什么?只是一个控制器或者一个module罢了。
http://user.pinjian.net可能对应了什么?http://pinjian.net/user/index,很有可能就这样而已。
而对于yii来说,这个太简单了
在main.php(环境 变量设置中),针对urlManager的rules加入:
PHP代码
- 'urlManager' => array(
- 'urlFormat' => 'path',
- 'showScriptName'=>false,
- 'rules' => array(
- 'http://photo.pinjian.net/<action:\w+>'=>'image/<action>',
- '<controller:\w+>/<id:\d+>' => '<controller>/view',
- '<controller:\w+>/<action:\w+>/<id:\d+>' => '<controller>/<action>',
- '<controller:\w+>/<action:\w+>' => '<controller>/<action>',
- ),
- ),
看看高亮的那一行,是不是很简单?
之前,有一篇博客介绍过的:http://www.neatstudio.com/show-1550-1.shtml,还篇比较详细
对于品鉴网的百度与google的一些搜索数据
Submitted by gouki on 2012, October 27, 9:04 PM
其实品鉴网(http://pinjian.net)上线也才3天,但是浏览量也有一点了。最高的一天也有100IP左右,当然今天就低了。只有10个IP。。。好苦逼啊。周六周日你们都不看美女?
其实做站的时候,我也有想过很多,所以我在街拍那一块就与其他的不一样,分成了各种色系,因为街拍并不是简单的拍完照就完事了,每个人都关注着不同的色系,因为他们有他们自己的风格。
当然我这里不是介绍我的想法和思路,我在做站的时候,虽然大家都知道我的数据是抓取的,不可能自己整理和收集,但我在数据的获取上还是花了一点心思,让数据更加精确化
在内容详细页,目前加入了简单的留言和分享,这是所有的网站都会有的功能,我希望品鉴网也不例外。
当然,过段时间会加入获取墙外原图和处理防盗 链的功能(第一步,获取墙外原图,也很快就会完成了)
最后说一下:
三天,google已经有2条收入了,但百度还是没有任何收入,亏我还用了百度的统计,而且还主动提交了我的网址,但居然还是没有任何收入。。。
其实,收入是收录。不过我喜欢收入这个词。。。
Unicode转换
Submitted by gouki on 2012, October 26, 9:51 AM
其实只是一段很少的代码。
http://www.kalvin.cn/article/php-encrypt-decrypt-unicode-string-functions-and-escape/
- <?php
- function uni_decode($s) {
- preg_match_all('/\&\#([0-9]{2,5})\;/', $s, $html_uni);
- preg_match_all('/[\\\%]u([0-9a-f]{4})/ie', $s, $js_uni);
- $source = array_merge($html_uni[0], $js_uni[0]);
- $js = array();
- for($i=0;$i<count($js_uni[1]);$i++) {
- $js[] = hexdec($js_uni[1][$i]);
- }
- $utf8 = array_merge($html_uni[1], $js);
- $code = $s;
- for($j=0;$j<count($utf8);$j++) {
- $code = str_replace($source[$j], unicode2utf8($utf8[$j]), $code);
- }
- return $code;//$s;//preg_replace('/\\\u([0-9a-f]{4})/ie', "chr(hexdec('\\1'))", $s);
- }
- function unicode2utf8($c) {
- $str="";
- if ($c < 0x80) {
- $str.=chr($c);
- } else if ($c < 0x800) {
- $str.=chr(0xc0 | $c>>6);
- $str.=chr(0x80 | $c & 0x3f);
- } else if ($c < 0x10000) {
- $str.=chr(0xe0 | $c>>12);
- $str.=chr(0x80 | $c>>6 & 0x3f);
- $str.=chr(0x80 | $c & 0x3f);
- } else if ($c < 0x200000) {
- $str.=chr(0xf0 | $c>>18);
- $str.=chr(0x80 | $c>>12 & 0x3f);
- $str.=chr(0x80 | $c>>6 & 0x3f);
- $str.=chr(0x80 | $c & 0x3f);
- }
- return $str;
- }
- $str='%u5927%u5BB6%u597D%uFF0C我是孤魂!<br />\u8FD9\u662F\u6D4B\u8BD5\u6587\u672C\uFF01';
- echo uni_decode($str); // 大家好,我是孤魂!这是测试文本!
- ?>
这段代码以前也写过,而且,其实用的地方挺多,比如json的字符串(有些只是json处理了一下,但并不能完全转换,总不能强制变成json格式再转换吧?)
其实黑的很方便,而且这段代码在PHP手册中的注释里也出现过,但一下子找不到了,于是看到后就做了个备份罢了
图片附件(缩略图):
品鉴网
Submitted by gouki on 2012, October 25, 10:33 PM
在晚上花了两个小时做了一个品鉴网(http://pinjian.net),收集一些美女的图片,还有一些搞笑图,当然壁纸什么的明显是要收集的啦,不然就太可惜了。。。
其实这种网站我很久前就想做了,但一直没有时间没有精力。这两天,晚上喝了点酒,不能做公司的事情,于是就噌噌噌的写了一点代码,把这个站就架设了起来。
话说,我还有好些个域名没有派上用场。
如果你有兴趣,我也可以出手一两个,反正闲着也是闲着:
yzhan.com
yiilog.com
7458.net
52cd.net
kkread.com
等。当然还有一些,就不一一透露了,从00年至今,在上面至今花费了将近2W左右的费用了吧。有些都不太想再收集域名了,而且有些域名还不是特别的好。累了
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [669]
- python [0]
- Go [9]
- Flutter [227]
- lua [0]
- Scala & Ruby [92]
- Javascript [307]
- PHP Framework [65]
- Linux [5]
- 苹果相关 [286]
- DataBase [0]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [982]
- Baby [161]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- It's going to be ending of...
07-05 - url - 好老的博客系统,当年用过。竟然还有人在用。
06-28 - im2828 - 你好,这个现在不能下载了,请重新提供一下吧
06-18 - 海东青 - 你这博客皮肤都20年了吧,该换了
05-27 - 月票的进哥 - 不用感觉,就是死了,停服公告都发出来了
05-27 - imlonghao
博客信息
- 分类数量: 17
- 文章数量: 3154
- 评论数量: 1911
- 标签数量: 2284
- 附件数量: 940
- 注册用户: 56
- 今日访问: 26273
- 总访问量: 75770767
- 程序版本: 1.6
