突然收到一封邮件,来自linode。。
Your Linode, linode????, has exceeded the notification threshold (90) for CPU Usage by averaging 111.6% for the last 2 hours. The dashboard for this Linode is located at: <https://manager.linode.com/linodes/dashboard/????>
This is an automated message, please do not respond to this email. If you have questions, please open a support ticket.
You can view or change your alert thresholds under the "Settings" tab of the Linode Manager.
This is not meant as a warning or a representation that you are misusing your resources. We encourage you to modify the thresholds based on your own individual needs.
-----------
上去一看,果然:
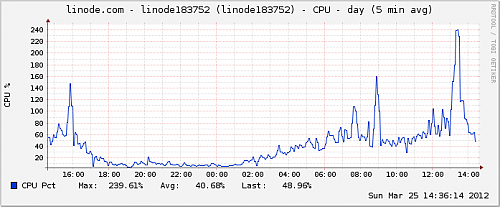
现在开始怀疑,burst的服务器挂掉是不是也是因为这个原因。但,一点不通知也不应该啊。看LOG也看不出什么原因,真纠结啊

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
浏览模式: 标准 | 列表分类:苹果相关
CPU突然过高。。。
Submitted by gouki on 2012, March 25, 10:37 PM
gentoo常用命令
Submitted by gouki on 2012, March 23, 9:50 AM
由于burst上面的虚拟机经常挂掉,然后我申请要退款,burst建议我换个OS或者Reinstall看看,我一咬牙,把VPS换到了linode上面,于是 把burst上面的VPS的OS换成了gentoo,结果我ssh上去之后习惯性的ls,居然告诉我命令不存在。我晶啊。
这下子玩大了。然后找了一下资料,emerge upgrade后,才有了这个命令,我傻眼了。想装B没装成,害惨自己了。
于是,找了下资料,参考:http://hi.baidu.com/chinsung/blog/item/3d21b6deee859f5dccbf1a51.html
1. 更新系统并移除孤立依赖的软件包
# emerge --update --deep --newuse world
# emerge --depclean
# revdep-rebuild (搜索相应缺失的库,并且重新emerge相应的包,需安装gentoolkit,并需运行两次以便确认)
2. emerge常用参数:
2.0 world | system, world范围更广,包含了system,这是两个set,前面不用加--或-
2.1 -p pretend 预览
2.2 -a ask 先予询问
2.3 -c clean 清理系统
2.4 -C unmerge 卸载,与emerge相反
2.5 --depclean 深度清理,移除与系统无关的包
2.6 -h help 帮助文件
2.7 -v verbose 详细内容
2.8 -s search 查找
2.9 -S searchdesc 从文件名和描述中查找,要慢一些
2.10 -u update 升级软件包
2.11 -D deep 计算整个系统的依赖关系
2.12 -e emptytree 清空依赖树,一般不用,危险命令
2.13 -1 oneshot 一次性安装,不将其信息加入系统目录树
2.14 -o onlydeps 只安装其依赖关系,而不安装软件本身
2.15 -t tree 显示其目录树信息
2.16 -k usepkg 使用二进制包
2.17 -K usepkgonly 只使用二进制包
2.18 -f fetchonly 仅下载安装包
2.19 --sync 从指定的rsync站点更新portage树,先前所作所有portage树更改均失效
2.20 -N newuse 使用新的USE FLAG,如有必要,需重新编译
2.21 -n noreplace 更新system,但先前安装的软件不予覆盖
3. 查找最快的mirror
# mirrorselect -s3 -b10 -o -D >> /etc/make.conf
此命令对每个mirror均下载100k文件,以此确定最快源,要注意修改/etc/make.conf
4. 系统升级
# emerge --sync 或 # emerge-webrsync (更新或称同步portage树)
# emerge --update --deep --newuse world
# emerge --depclean -pv
# revdep-rebuild (需安装gentoolkit)
如果使用emerge-webrsync命令进行升级,可先下载最新的portage(以日期命名,而不要用latest命名)至/var/tmp/emerge-webrsync/目录
5. 查看安装XXX的情况,同时列出了使用的 USE 和 LINGUAS
# emerge -pv XXX
6. 在world中增加记录,避免自己已手动编译的软件被再次编译
# emerge -n fcitx (添加fcitx至emerge tree)
7. 配置文件更新工具
# etc-update 或 # dispatch-conf
8. 查询XXX包用了什么USE(需gentoolkit)
# equery uses XXX
9. 找到 /bin/ls 所属包
# qfile /bin/ls
10. 列出 glibc 包所包含文件
# qlist glibc
11. /etc/portage/package.*应用举例
11.1 package.use
sys-apps/man-pages -nls sys-apps/pciutils -zlib media-libs/freetype bindist app-text/acroread linguas_zh_TW linguas_zh_CN linguas_en
作用:
不改变全局USE的同时,微调包的USE。 开始2个是说这2个包不使用相应的 USE,第三个说明要单独在这个包使用这个USE,最后一个是调整 LINGUAS 的,很容易明白。
11.2 package.keywords
sys-apps/hdparm ~x86
作用:
指定相应的包的 KEYWORDS。比如你想 hdparm 包用 ~x86 的版本,而不用 x86 的版本,就用这个来指定。 注意,因为 emerge 的设计,如果你的 make.conf 里边指定了 ~x86的话,你不能反过来通过指定 x86 而 不要 ~x86,只能用 -~x86 来达到目的。 引用 gentoo@freenode 上<kojiro>的话: ”ACCEPT_KEYWORDS is incremental“
11.3 package.mask
>sys-devel/libtool-1.5.23
作用:
屏蔽某个包某个版本,或者某些版本,甚至整个包。
比如 libtool-1.5.23b 在我的系统有问题,那么就屏蔽一下,只用 比 1.5.23 小的。
11.4 package.unmask
=net-www/apache-2.2.4 games-arcade/stepmania
和 mask 一样,不过效果正好相反。我要用 2.2.4 的 apache,但是 portage 把他 mask 了,所以手动 unmask 一下。
12. 往 default runlevel 里边加入 XXX 服务 (add)
# rc-update -a XXX default
13. 从 default runlevel 里边删除 XXX 服务 (delete)
# rc-update -d XXX default
14. 列出 default runlevel 所有的服务 (show)
# rc-update -s default
15. 删除过期的包
# eclean distfiles (请先 emerge gentoolkit)
16. 清除emerge过程中产生的临时文件
# rm -rf /var/tmp/portage/*
17. 清除所有安装源码包(除非太穷,否则不建议)
# rm -rf /usr/portage/distfiles/*
-------
不管它不管它,先备份,天知道以后会不会用,
巧用VMware虚拟机NAT端口映射使外网访问虚拟机
Submitted by gouki on 2012, February 28, 9:13 AM
以下内容只针对vmware(我只在Server上试过),不知道其他软件怎么样。
遇到的问题是这样的,有朋友的虚拟机出了点问题,想让我帮忙看看,可是如果通过 QQ远程连上去,再打开虚拟机会很卡,所以想到,是否可以让我直接SSH连接上,但因为虚拟机是NAT方式的连接,即IP是私有的,无法直接连上,找了些资料,发现NAT端口映射可以搞定。
以下是资料介绍:原文来自:http://www.linuxso.com/linuxrumen/141.html
NAT中隐藏的端口映射,说明一下环境,利用当然是VMnet8网络连接,在虚拟机中架设win2003的WEB服务器利用WEB默认80端 口,IP为192.168.10.4,真实主机winxp系统有两个IP,内网连接192.168.10.1,外网上IP为 221.196.193.220。外网其他计算机,可以通过访问我的真实主机221.196.193.220,访问到win2003的WEB。
首先说下原理,因为WEB服务是利用80端口,所以在Win2003上建立了WEB服务,80也就自动被打开,因为Win03是内网 ip(192.168.10.4),外网无法通过访问这个地址,找到我的web服务,但是可以通过外网地址(221.196.193.220)访问我的 XP系统,XP又能连接到Win2003,所以把80映射到我的Winxp的系统上是有可能的!
那么废话了,现在说实际操作,打开--编辑--虚拟网络设置--NAT选项卡,如下图:
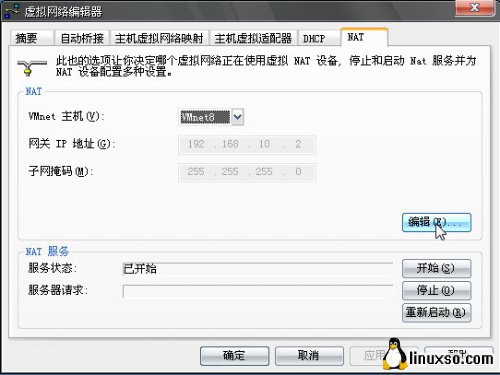
选择编辑,打开NAT设置,这里保持默认就可以,如果你对你自己的网络很熟悉,可以更改网关等项目
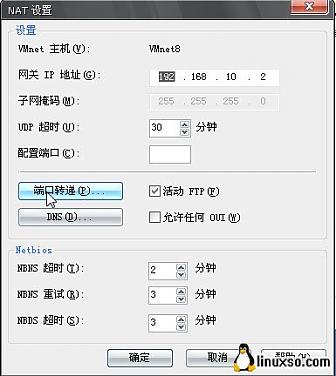
直接打开端口转递,这里就是NAT的端口映射配置了,用实例的WEB服务举例,因为WEB属TCP连接,所以在TCP和UDP上我都做了,转换,点击添加
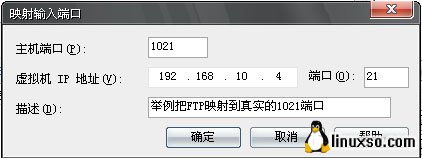
主机端口,填入真实主机要被转换的端口,这里我用FTP又举了个例子,在真实的主机上1021上建立了FTP服务,这样访问时就需要ip后加:,如ftp://192.168.1.1:1021便可正常访问了,这里因为我的XP上没有web服务所以主机端口添的依旧是80.
虚拟机IP地址,填入内网虚拟机的IP,这个是Win2003的IP,服务端口,对应那个服务就填入哪个端口,你可以参考其他文章,常用端口.
描述,无所谓了,写个自己能看懂的就行,不些也没问题啊~
这样一来,你的朋友就可以在IE下输入http://221.196.193.220/ 访问到你虚拟机中Win2003下的WEB服务了,什么?还不可以?自己访问成功可是其他人都不行?
呵呵,不要急,如果你是WINXP SP2的系统,去看看你的防火墙设置吧,添加端口,不用我说了吧,安全起见,把TCP和UDP都加到例外中,就ok了~
PS:1、在虚拟机里配置好IIS和动态域名解析软件
2、如果你的主机处于内网中,请在路由器上设置端口映射,如果主机直接连接互联网,可以忽略此步骤。
-------
嗯,我是作了22端口映射,然后ssh主机的IP,果然能够连上,这下子操作起来访问很多了。
lnmp组件中sablog的配置纠错
Submitted by gouki on 2012, February 21, 10:45 PM
lnmp是现在相对比较容易和被大家所接受的一个套装。由于我用的是Sablog所以我在设定vhost的时候就选了sablog,但是告诉我第二行出错了。
仔细检查了一下,好象确实是有这个问题,一来好象是编码也有问题,二来它copy的规则有点象是discuz的规则,和sablog系统后台中的规则不一样。所以,我根据 sablog后台中的规则进行了修正,立刻正常了。
sablog的默认规则是支持apache的rewrite的。如下:
XML/HTML代码
- # BEGIN Sablog-X
- RewriteEngine On
- RewriteBase /
- # 文章
- RewriteRule ^show-([0-9]+)-([0-9]+)\.shtml$ index.php?action=show&id=$1&page=$2
- # 分类
- RewriteRule ^category-([0-9]+)-([0-9]+)\.shtml$ index.php?action=index&cid=$1&page=$2
- # 只带月份的归档
- RewriteRule ^archives-([0-9]+)-([0-9]+)\.shtml$ index.php?action=index&setdate=$1&page=$2
- # 用户列表、高级搜索、注册、登陆
- RewriteRule ^(archives|search|reg|login|index|links)\.shtml$ index.php?action=$1
- # 全部评论、标签列表、引用列表 带分页
- RewriteRule ^(comments|tagslist|trackbacks|index)-([0-9]+)\.shtml$ index.php?action=$1&page=$2
- # END Sablog-X
注意那个.shtml,那是我自定义的URL后缀,所以你看我的博客的时候,都有这玩意。。。将就点了。说实话,我怀疑这个shtml对SEO有友好度,所以我才这么配置(纯属猜测)
改完后配置是这样的:
XML/HTML代码
- location / {
- rewrite ^/show-([0-9]+)-([0-9]+)\.shtml$ /index.php?action=show&id=$1&page=$2 last;
- rewrite ^/category-([0-9]+)-([0-9]+)\.shtml$ /index.php?action=index&cid=$1&page=$2 last;
- rewrite ^/archives-([0-9]+)-([0-9]+)\.shtml$ /index.php?action=index&setdate=$1&page=$2 last;
- rewrite ^/(archives|search|reg|login|index|links)\.shtml$ /index.php?action=$1 last;
- rewrite ^/(comments|tagslist|trackbacks|index)-([0-9]+)\.shtml$ /index.php?action=$1&page=$2 last;
- }
其实看到没,与apache下的配置很相像,只是在最前面加了 ^/ ,然后在指向的文件前加 /
同时在最后加 last;
嗯,就这样。。。灰常方便,你换了没?
linux中的inode简单介绍
Submitted by gouki on 2012, February 9, 9:10 AM
linux下面有一个很恶心的说法,就是磁盘空间再大,但如果没有inode了,磁盘也就相当于没用了(这个没用是指剩余空间再大,也存不进东西)
这种问题在ext3上很容易出现,如果磁盘格式是Ext3,然后又是用来存一些小文件(如图片、icon等小而多的文件)时,很容易出现这种问题。所以一般图片服务器都是不用Ext格式的。
虚拟机上居然出现了这种问题,所以找了一下资料,找到了这篇文章:http://www.cnblogs.com/shapherd/archive/2012/02/07/2341638.html
最近在linux上创建目录的时候出现mkdir:Cannot create directory***: No space left on device, 但是df的时候发现空间还有几百G(有同事是中文的机器出现Mkdir: 无法创建目录***,设备上没有空间)。不能继续创建目录或者touch文件的原因是Inode满了。
Inode的数量是有限制的,每个文件对应一个Inode, 那么如何查看inode的最大数量呢,
XML/HTML代码
- [work@*** ~]$ df -i
- Filesystem Inodes IUsed IFree IUse% Mounted on
- /dev/cciss/c0d0p2 1154176 172807 981369 15% /
- /dev/cciss/c0d0p3 88309760 51951 88257809 1% /home
可以看到Inode的总量,已经使用的Inode数量,和剩余数量。
如果watch -n 1 “df -i”一下, 然后去创建一个文件, 会发现已用的加一,未用的减一
简单了解下Inode在文件系统中的地位:
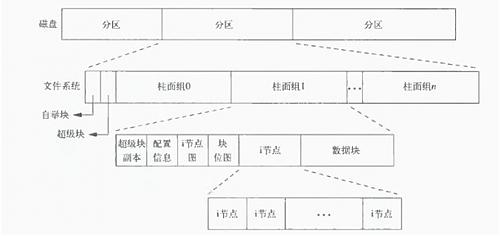
Linux会为每一个文件分配一个唯一的inode节点。在linux中,文件的文件名、文件属性、文件内容是分别存储的:文件名存放在目录项(即 dentry)中,文件属性存放在inode中,文件内容存放在block中。Linux在查找文件时,首先先读取dentry,dentry中存储的文 件名和inode编号的一个映射表, 根据这个表找到inode编号,再根据inode找到磁盘中的文件。
可以用ls -i查看文件对应的inode编号, 也可以直接stat一个文件, 会有很全的信息。
----------
ext4好象听说是好了很多,但更多的人在做图片服务器的时候都选择了:ReiserFS,可惜它不再更新了,为什么呢?因为。。。Linux文件系统reiserfs作者:Hans Reiser被判入狱15年
http://linux.solidot.org/linux/08/08/30/0449258.shtml
- Linux文件系统reiserfs作者Hans Reiser因谋杀妻子正式被宣判入狱15年。今年早些时候,Reiser承认了罪行,并领着警察挖掘出妻子的遗体。他的陪审团在4月份判定Reiser一级谋杀罪名成立,将面临25年的监禁。但是随后政府和他进行了秘密交易,如果他透露妻子的遗体并放弃上诉的权利,他的入狱期限将降至15年。
- 在宣判前Reiser发表声明,“我真诚的为我的罪行向社会致歉。每一个生命都是神圣的,我取走了一个人类的生命,对此我感到难过。”Hans Reiser在2006年9月下午4:30杀手了妻子Nina,他用手捂住她的嘴,使她窒息而死。他暂时将其藏在浴室,后移至汽车,尸体一直在车上呆了两天直到他寻找到埋藏的地点。"
BTW:这里有一篇科普文章:http://www.serverfocus.org/reiserfs-vs-ext4-vs-xfs-vs-zfs-vs-btrfs
原来,reiserfs已经升级到4了。
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [668]
- python [0]
- Go [9]
- Flutter [227]
- lua [0]
- Scala & Ruby [92]
- Javascript [307]
- PHP Framework [65]
- Linux [5]
- 苹果相关 [286]
- DataBase [0]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [982]
- Baby [161]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- It's going to be ending of...
07-05 - url - 好老的博客系统,当年用过。竟然还有人在用。
06-28 - im2828 - 你好,这个现在不能下载了,请重新提供一下吧
06-18 - 海东青 - 你这博客皮肤都20年了吧,该换了
05-27 - 月票的进哥 - 不用感觉,就是死了,停服公告都发出来了
05-27 - imlonghao
博客信息
- 分类数量: 17
- 文章数量: 3153
- 评论数量: 1911
- 标签数量: 2284
- 附件数量: 940
- 注册用户: 56
- 今日访问: 23791
- 总访问量: 75701493
- 程序版本: 1.6
