Submitted by gouki on 2012, December 12, 11:57 PM
说到获取公网IP,那方法是相当的多啊
1、利用第三方服务:ip138,用脚本访问他的首页,然后正则取出自己的IP
2、还是处用第三方的服务,如QQ,那种QQ判断来源IP,然后得到地址URL,连上去也能获取IP,当然也得正则
3、自己在自己的服务器上架个服务。返回公网IP,
4、利用dns的服务,比如 这样:
XML/HTML代码
- function getClientIp(){
- $socket = socket_create(AF_INET, SOCK_STREAM, 6);
- $ret = socket_connect($socket,'ns1.dnspod.net',6666);
- $buf = socket_read($socket, 16);
- socket_close($socket);
- return $buf;
- }
5、利用tracert,基本上也能获取 IP。ping也行。只是麻烦了一点
6、如果是本机直接拨号,那就方便了ifconfig , ipconfig /all也可以
PHP | 评论:0
| 阅读:20039
Submitted by SubZero on 2012, December 10, 11:03 PM
好吧,我感觉又被xcache骗了。当然也可能是他们没注意吧。
在网站上,他们说:
修复版本. XCache admin 页面有大量改进, 增加 namespace 支持, 等等. 更新 API, 新增了一些 INI 设置. 新增 "诊断" 模块给出一些专家级建议 (htdocs 中). 进程异常时自动禁用缓存 (运行期间). 警告: 本版本开始使用 extension= 来加载 XCache. 不再支持采用 zend_extension= 方式加载.
再接着说上面的那句警告:本版本开始使用Extension那句
OK,当我装完的时候:
XML/HTML代码
- root@MyDebian64Bit:~/xcache-3.0.0# make install
- Installing shared extensions: /usr/lib/php5/20090626/
你看,成功了,但是看了一下xcache.ini。。。
XML/HTML代码
- [xcache-common]
- ;; install as zend extension (recommended), normally "$extension_dir/xcache.so"
- zend_extension = /usr/lib/php5/20090626/xcache.so
一下子就与说明不太一致了
PHP | 评论:1
| 阅读:16542
Submitted by SubZero on 2012, December 10, 9:21 AM
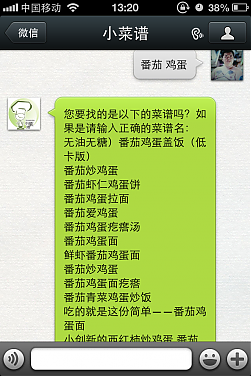
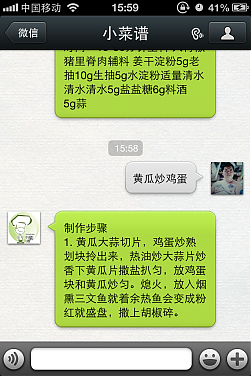
想不到,我的http://xiaocaipu.com还没有上线,我的微信功能却已经正常在运作了。
打开微信搜索好友,如果按帐号添加,就搜索:xiaocaipu,如果搜索公众帐号,就搜:小菜谱。当然,你懒的话,就扫描这个:
小LOGO是http://82982.com的小茗帮忙做的。。那一群设计师的朋友啊什么的,都说自己没空,我纠结啊。
不知道这个帐号是做什么的?那我得上好多图了。。。
先上两个简单的图吧
这些只是基础功能,还有相对比较高级一点的功能:
Tags: 小菜谱
PHP | 评论:1
| 阅读:16107
Submitted by SubZero on 2012, December 8, 2:32 PM
pcntl在很久很久之前就听过了,但是一直没有尝试着真正要用它。这不,遇到socket问题了,看socket,遇到pcntl了,再看看吧。
这里是某个人的测试代码:
PHP代码
- <?php
-
-
-
-
-
-
-
-
- function new_child($func_name)
- {
- $args = func_get_args();
- unset($args[0]);
- $pid = pcntl_fork();
- if ($pid == 0) {
- function_exists($func_name) and exit(call_user_func_array($func_name, $args)) or exit(-1);
- }
- else if ($pid == -1) {
- echo "Couldn’t create child process .";
- }
- }
-
- function test($prefix, $num)
- {
- while ($i++ < $num) {
- echo $prefix . $i ."\n";
- }
- }
-
- new_child("test", "child process ", 100);
-
- test("parent process", 100);
-
- ?>
因为上面有作者有注释,所以我就不再多贴这篇文章的地址了。原网页的代码是错误的。我改了一下。原作者说的是:父进程输出50个左右时,子进程就开始运行了。我这边不是。我把数据改成1000后,发现父进程在950多的时候,子进程开始运行了。
当然,看手册也可以,对了,风雪之隅也写过类似的文章,http://www.laruence.com/2009/06/11/930.html,他提到的优点就是:
XML/HTML代码
- 优点:
- 1. 使用多进程, 子进程结束以后, 内核会负责回收资源
- 2. 使用多进程,子进程异常退出不会导致整个进程Thread退出. 父进程还有机会重建流程.
- 3. 一个常驻主进程, 只负责任务分发, 逻辑更清楚.
然后他的代码就与上面有点区别,不过说白了还是大同小异:
PHP代码
- #!/bin/env php
- <?php
-
-
-
-
-
-
-
-
-
- if (substr(php_sapi_name(), 0, 3) !== 'cli') {
- die("This Programe can only be run in CLI mode");
- }
-
-
- set_time_limit(0);
-
- $pid = posix_getpid();
- $user = posix_getlogin();
-
- echo <<<EOD
- USAGE: [command | expression]
- input php code to execute by fork a new process
- input quit to exit
-
- Shell Executor version 1.0.0 by laruence
- EOD;
-
- while (true) {
-
- $prompt = "\n{$user}$ ";
- $input = readline($prompt);
-
- readline_add_history($input);
- if ($input == 'quit') {
- break;
- }
- process_execute($input . ';');
- }
-
- exit(0);
-
- function process_execute($input) {
- $pid = pcntl_fork();
- if ($pid == 0) {
- $pid = posix_getpid();
- echo "* Process {$pid} was created, and Executed:\n\n";
- eval($input);
- exit;
- } else {
- $pid = pcntl_wait($status, WUNTRACED);
- if (pcntl_wifexited($status)) {
- echo "\n\n* Sub process: {$pid} exited with {$status}";
- }
- }
- }
做个笔记。
Tags: 多进程, pcntl
PHP | 评论:0
| 阅读:38128
Submitted by SubZero on 2012, December 6, 11:16 PM
其实本来不想定这个标题的。只是做了几个小小的测试
我用php实现了socket server,然后在命令行下做了点测试。在命令行下访问soap,并将返回值 给了客户端。
测试了一下。网速比较卡的情况下,基本在0.8秒左右
然后我直接访问soap,打印出来的时候都差不多比命令行返回结果多了0.2秒。
这只是测试了soap请求一次。后来,我请求了两次。发现速度又快了0.1秒。
总计快了0.3秒。在命令行下用socket server返回数据好象快了一点。
-----------
文章只是我的一次记录,没有什么特别的意义。虽然不太科学,但对我来说,有三四台服务器的情况下,利用这个来交换数据还是有点用的。目前我的socket server只能用PHP实现,因为 部分代码都是靠PHP来获取数据的。本来想用go或者python来实现的,但目前没有时间。先用PHP了
PHP | 评论:1
| 阅读:18632