尝试用qq的企业邮箱发一些邮件的时候,发现被文档坑了一小把(不是QQ的错,是我的错)
文档中说smtp发送的时候,得用SSL方式,同时端口为465或者587,于是我在phpmailer里设定了port = 465,于是直接发送。发现报错。老是说邮件地址有问题
1、检查phpmailer,发现。如果设置port为465,这时候其实是要设定SMTPSecure=ssl的
当设置了SMTPSecure='ssl'后,发送成功
2、其实,也可以不用SSL的,只要仍然使用 25端口发送就OK了,并非一定得用SSL来发送。。。
所以,通过QQ企业邮箱的smtp发送邮件就有两个方法 ,ssl和标准的smtp。
Over

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
浏览模式: 标准 | 列表分类:PHP
被QQ exmail的文档坑了下
Submitted by gouki on 2013, January 28, 2:22 PM
yii with的排序
Submitted by gouki on 2013, January 23, 9:51 AM
Yii在自己的AR中实现了relations,于是我们可以利用relations实现一些left join或者其他join能做的事情,常见的大家都懂,什么 belongs_to,has_one,has_many,many_to_many之类的
但用的最多的,一般都是has_one,has_many,毕竟查关联数据这个最方便了。
于是我们就会Table::model()->with('a','b')->findAll($cdbcriteria);
这个时候,如果需要用到a或b的排序,就有点痛苦,直接在$cdbcriteria中写的话,往往会报字段不存在,因此可以尝试这样
1、直接在relations中,在写成a时,直接加入'order'=>'id DESC'之类的内容
2、在with()中写: with(array('a'=>array('order'=>'id DESC'),'b'))
这样是不是就很方便了呢?
当然上面的代码是通过:
PHP代码
- public function with()
- {
- if(func_num_args()>0)
- {
- $with=func_get_args();
- if(is_array($with[0])) // the parameter is given as an array
- $with=$with[0];
- if(!empty($with))
- $this->getDbCriteria()->mergeWith(array('with'=>$with));
- }
- return $this;
- }
看了这段代码就基本上了解用法了,手册里也说了:
Specifies which related objects should be eagerly loaded. This method takes variable number of parameters. Each parameter specifies the name of a relation or child-relation. For example,
// find all posts together with their author and comments
Post::model()->with('author','comments')->findAll();
// find all posts together with their author and the author's profile
Post::model()->with('author','author.profile')->findAll();
The relations should be declared in relations().
By default, the options specified in relations() will be used to do relational query. In order to customize the options on the fly, we should pass an array parameter to the with() method. The array keys are relation names, and the array values are the corresponding query options. For example,
Post::model()->with(array(
'author'=>array('select'=>'id, name'),
'comments'=>array('condition'=>'approved=1', 'order'=>'create_time'),
))->findAll();
所以,有时候看看手册还是很重要的。
Typecho Slug 拼音插件
Submitted by gouki on 2013, January 18, 12:57 AM
用法很方便,功能也很简单,如果你的typecho不是以slug的方式显示的,那就没有意义了
如果以slug的方式显示,一般是自己主动写成英文的话,那也没有意义,我这个只是好玩罢了。
自动将标题转成拼音。
在编辑和保存的时候,会自动将它转成slug。如果slug为空,或者为数字(可能是文章ID)的情况下,自动转成拼音
因为,该插件不需要你改程序,也没有配置文件 ,所以就不多介绍了。
下载地址:
---update: 2020-04-14
怎么不解析attach信息了?
Yii不启用LOG,记录当前所有的错误信息
Submitted by gouki on 2013, January 7, 11:13 PM
在不启用LOG的情况下,如何记录错误呢?
我们都知道可以在出错的时候跳转到site/error下面那么也就相当于在输出error前将错误记录下来。
这时候我们当然是可以通过error_log来处理,也可以通过 自己写一段file_put_contents来将错误记录下来:error['errormsg'],将它保存就OK了。但有没有其他办法?
嗯,不需要自己控制程序,只要写三行代码就OK
PHP代码
- $logger = new CFileLogRoute();
- $logger->init();
- $logger->collectLogs(Yii::getLogger(),true);
在判断完是否正确的时候就可以用这些代码将LOG存储下来。多方便 啊
图片附件(缩略图):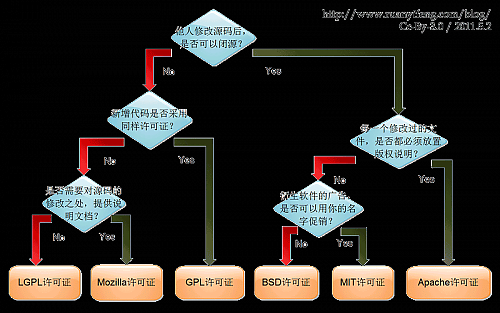
试用gist
Submitted by gouki on 2012, December 29, 5:17 PM
其实gist功能早就见过了。类似功能的网站也非常多,但那些是不要注册 的。不过github这个gist嘛,注册了也有好处。自己把自己曾经写过的代码,还算好的代码,或者有想法的代码缓存下来。对自己以后 回顾的时候也有好处。
毕竟存在自己的电脑上也容易丢掉。这样多了一个碎片的管理,多少也有点好处。
比如,我就有这样一段:
PHP代码
- <?php
- $str = "101|1;0|4;1|0;0|0;0|0";
- //第一种
- $array = explode(';', $str);
- $items = array();
- foreach ($array as $v) {
- list($k, $v) = explode('|', $v);
- if (emptyempty($v)) {
- continue;
- }
- $items[$v] = $k;
- }
- echo "<pre>";
- print_r($items);
- echo "</pre>";
- //第二种
- parse_str(preg_replace(array('/\d+\|0/','/;/','/\|/'),array("","&","="),$str),$result);
- echo "<pre>";
- print_r($result);
- echo "</pre>";
看上去有点乱。不过。。。到:https://gist.github.com/4405542看就好很多了。。
我看看在代码里能不能引用:
图片附件: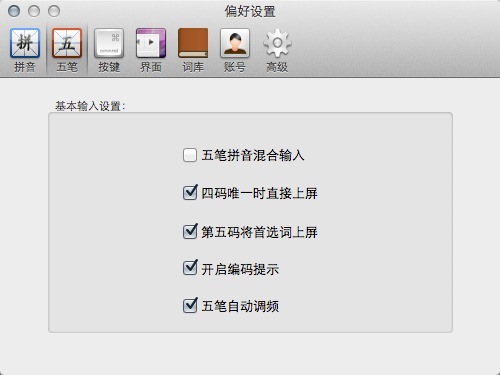
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [669]
- python [0]
- Go [9]
- Flutter [227]
- lua [0]
- Scala & Ruby [92]
- Javascript [307]
- PHP Framework [65]
- Linux [5]
- 苹果相关 [286]
- DataBase [0]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [982]
- Baby [161]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- It's going to be ending of...
07-05 - url - 好老的博客系统,当年用过。竟然还有人在用。
06-28 - im2828 - 你好,这个现在不能下载了,请重新提供一下吧
06-18 - 海东青 - 你这博客皮肤都20年了吧,该换了
05-27 - 月票的进哥 - 不用感觉,就是死了,停服公告都发出来了
05-27 - imlonghao
博客信息
- 分类数量: 17
- 文章数量: 3154
- 评论数量: 1911
- 标签数量: 2284
- 附件数量: 940
- 注册用户: 56
- 今日访问: 3618
- 总访问量: 75927803
- 程序版本: 1.6
