网上的资料,都是用svn update命令在post-commit里面进行同步,这里面很多人都忽略了讲最重要的一点,那就是在svn update之前,该目录必须要先用svn checkout一下,否则。update目录会直接忽略该目录。
这,几乎所有的教程里都没讲,我是试了半天啊。。。
后来,也找到了一篇类似教程。希望看到的人少走点弯路。
原文:http://www.unix-center.net/bbs/viewthread.php?tid=11607
Linux环境下配置同步更新的SVN服务器
先搭建环境
Linux版本选择Centos5.0(
膘叔:我是用的ubuntu,具体的安装方法可以参考我的上篇step by step安装svu for ubuntu)
#yum update
#yum -y install gcc
#yum -y install httpd
#yum install mod_dav_svn subversionDependencies Resolved
初期配置 我选择的是以HTTP方式实现SVN功能
cd /etc/httpd/conf.d/
vi subversion.conf
添加以下内容
# Make sure you uncomment the following if they are commented outLoadModule dav_svn_module
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule authz_svn_module modules/mod_authz_svn.so
# Add the following to allow a basic authentication and point Apache to where the actual# repository resides.
<Location /boqii> #访问域名,设置后可以直接用
http://127.0.0.1/boqii来访问了
DAV svn
SVNPath /svn/boqii #SVN建立的版本数据库位置
AuthType Basic
AuthName "Subversion boqii"
AuthUserFile /etc/svn-auth-conf
Require valid-user
</Location>
建立SVN的用户和权限设置
建立第一个用户
htpasswd -cm /etc/svn-auth-conf woody
然后根据提示输入密码并且确认密码,以后再建立用户就不需要再加上参数-c了
htpasswd -m /etc/svn-auth-conf keen
htpasswd -m /etc/svn-auth-conf harry
建立版本数据库
cd /
mkdir svn
cd svn
svnadmin create boqii
chown -R apache.apache boqii
设置APACHE发布信息
DocumentRoot "/www"
<Directory "/www">
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
service httpd start
建立导入目录
cd /
mkdir www
chmod 755 www
chown apache.apache /www
配置钩子程序
[root@www /]# cd /svn/boqii/hooks/
[root@www hooks]# cp post-commit.tmpl post-commit
[root@www hooks]# chmod 755 post-commit
[root@www hooks]# chown apache.apache post-commit
[root@www hooks]# vi post-commit
将里面的所有代码全部注释
添加以下这行代码
svn update --username=woody --password=woody
http://127.0.0.1/boqii /www
然后保存退出
导出版本version:0的数据库内容
svn checkout --username=woody --password=woody
http://127.0.0.1/boqii /www
配置完毕,重启一下APACHE服务器试试看
service httpd restart
参考文章
在 FreeBSD 下架設 Subversion
最简单的SVN (subversion)的配置for centos
Version Control with Subversion我的博客 www.yidaman.com 欢迎大家多多交流我在安装SVN for ubuntu的时候直接参考了本文,因此摘录下来,与各位分享。
原文:http://www.svn8.com/svnpz/20080308/253.html
1. 简介
如果您对 Subversion 还比较陌生,本节将给您一个关于 Subversion 的简要介绍。
Subversion 是一款开放源代码的版本控制系统。使用 Subversion,您可以重新加载源代码和文档的历史版本。Subversion 管理了源代码在各个时期的版本。一个文件树被集中放置在文件仓库中。这个文件仓库很像是一个传统的文件服务器,只不过它能够记住文件和目录的每一次变化。
2. 假设
首先我们假设您能够在 Ubuntu 中操作 Linux 的命令、编辑文件、启动和停止服务。当然,我们还认为您的 Ubuntu 正在运行中,您可以使用 sudo 操作并且您打算使用 Subversion。
我们假设您可能需要使用所有可能的方法访问 SVN 文件仓库。同时我们也认为您应该已经配置好了您的 /etc/apt/sources.list 文件。
3. 本文涉及的范围
要通过 HTTP 协议访问 SVN 文件仓库,您需要安装并配置好 Web 服务器。Apache 2 被证实可以很好的与 SVN 一起工作。关于 Apache 2 的安装超出了本文的范围,尽管如此,本文还是会涉及如何配置 Apache 2 使用 SVN。
类似的,要通过 HTTPS 协议访问 SVN 文件仓库,您需要在您的 Apache 2 中安装并配置好数字证书,这也不在本文的讨论范围之中。
4. 安装
幸运的,Subversion 已经包含在 main 仓库中。所以,要安装 Subversion,您只需要简单的运行:
$ sudo apt-get install subversion
$ sudo apt-get install libapache2-svn
如果系统报告了依赖关系的错误,请找出相应的软件包并安装它们。如果存在其它问题,也请自行解决。如果您是再不能解决这些问题,可以考虑通过 Ubuntu 的网站、Wiki、论坛或邮件列表寻求支持。
5. 服务器配置
您应该已经安装了上述的软件包。本节将阐述如何创建 SVN 文件仓库以及如何设置项目的访问权限。
5.1. 创建 SVN 仓库
许多位置都可以放置 Subversion 文件仓库,其中两个最常用的是:/usr/local/svn 以及 /home/svn。为了在下面的描述中简单明了,我们假设您的 Subversion 文件仓库放在 /home/svn,并且你的项目名称是简单的“myproject”。
同样的,也有许多常用的方式设置文件仓库的访问权限。然而,这也是安装过程中最经常出现错误 的地方,因此我们会对此进行一个详细说明。典型的情况下,您应该创建一个名为“Subversion”的组来拥有文件仓库所在的目录。下面是一个快速的操 作说明,有关内容请参考相关文档的详细说明:
在 Ubuntu 菜单上选择“系统->系统管理->用户和组”;
切换到“组”标签;
点击“添加组”按钮;
组名为“subversion”;
将您自己和“www-data”(Apache 用户)加入组成员中;
点击“OK”以确认修改,关闭该程序。
您需要注销然后再登录以便您能够成为 subversion 组的一员,然后就可以执行签入文件(Check in,也称提交文件)的操作了。
现在执行下面的命令
$ sudo mkdir /home/svn
$ cd /home/svn
$ sudo mkdir myproject
$ sudo chown -R root:subversion myproject
$ sudo chmod -R g+rws myproject
最后的一条命令赋予组成员对所有新加入文件仓库的文件拥有相应的权限。
下面的命令用于创建 SVN 文件仓库:
$ sudo svnadmin create /home/svn/myproject
6. 访问方式
Subversion 文件仓库可以通过许多不同的方式进行访问(Check Out,签出)——通过本地硬盘,或者通过各种网络协议。无论如何,文件仓库的位置总是使用 URL 来表示。下表显示了不同的 URL 模式对应的访问方法:
模式
访问方法
file:///
直接访问本地硬盘上文件仓库
http://
通过 WebDAV 协议访问支持 Subversion 的 Apache 2 Web 服务器
https://
类似 http://,支持 SSL 加密
svn://
通过自带协议访问 svnserve 服务器
svn+ssh://
类似 svn://,支持通过 SSH 通道
本节中,我们将看到如何配置 SVN 以使之能够通过所有的方法得以访问。当然这里我们之讨论基本的方法。要了解更高级的用途,我们推荐您阅读《使用 Subversion 进行版本控制》在线电子书。
6.1. 直接访问文件仓库(file://)
这是所有访问方式中最简单的。它不需要事先运行任何 SVN 服务。这种访问方式用于访问本地的 SVN 文件仓库。语法是:
$ svn co file:///home/svn/myproject
或者
$ svn co file://localhost/home/svn/myproject
注意:如果您并不确定主机的名称,您必须使用三个斜杠(///),而如果您指定了主机的名称,则您必须使用两个斜杠(//).
对文件仓库的访问权限基于文件系统的权限。如果该用户具有读/写权限,那么他/她就可以签出/提交修改。如果您像前面我们说描述的那样设置了相应的组,您可以简单的将一个用户添加到“subversion”组中以使其具有签出和提交的权限。
6.2. 通过 WebDAV 协议访问(http://)
要通过 WebDAV 协议访问 SVN 文件仓库,您必须配置您的 Apache 2 Web 服务器。您必须加入下面的代码片段到您的 /etc/apach2/apache2.conf 中:
DAV svn
SVNPath /home/svn/myproject
AuthType Basic
AuthName "myproject subversion repository"
AuthUserFile /etc/subversion/passwd
Require valid-user
当您添加了上面的内容,您必须重新起动 Apache 2 Web 服务器,请输入下面的命令:
sudo /etc/init.d/apache2 restart
接下来,您需要创建 /etc/subversion/passwd 文件,该文件包含了用户授权的详细信息。要添加用户,您可以执行下面的命令:
sudo htpasswd2 /etc/subversion/passwd user_name
它会提示您输入密码,当您输入了密码,该用户就建立了。您可以通过下面的命令来访问文件仓库:
$ svn co http://hostname/svn/myproject myproject --username user_name
它会提示您输入密码。您必须输入您使用 htpasswd2 设置的密码。当通过验证,项目的文件就被签出了。
警告:密码是通过纯文本传输的。如果您担心密码泄漏的问题,我们建议您使用 SSL 加密,有关详情请看下一节。
6.3. 通过具有安全套接字(SSL)的 WebDAV 协议访问(https://)
通过具有 SSL 加密的 WebDAV 协议访问 SVN 文件仓库(https://)非常类似上节所述的内容,除了您必须为您的 Apache 2 Web 服务器设置数字证书之外。
您可以安装由诸如 Verisign 发放的数字签名,或者您可以安装您自己的数字签名。
我们假设您已经为 Apache 2 Web 服务器安装和配置好了相应的数字证书。现在按照上一节所描述的方法访问 SVN 文件仓库,别忘了把 http:// 换成 https://。如何,几乎是一模一样的!
6.4. 通过自带协议访问(svn://)
当您创建了 SVN 文件仓库,您可以修改 /home/svn/myproject/conf/svnserve.conf 来配置其访问控制。
例如,您可以取消下面的注释符号来设置授权机制:
# [general]
# password-db = passwd
现在,您可以在“passwd”文件中维护用户清单。编辑同一目录下“passwd”文件,添加新用户。语法如下:
username = password
要了解详情,请参考该文件。
现在,您可以在本地或者远程通过 svn:// 当文 SVN 了,您可以使用“svnserve”来运行 svnserver,语法如下:
$ svnserve -d --foreground -r /home/svn
# -d -- daemon mode
# --foreground -- run in foreground (useful for debugging)
# -r -- root of directory to serve
要了解更多信息,请输入:
$ svnserve --help
当您执行了该命令,SVN 就开始监听默认的端口(3690)。您可以通过下面的命令来访问文件仓库:
$ svn co svn://hostname/myproject myproject --username user_name
基于服务器的配置,它会要求输入密码。一旦通过验证,就会签出文件仓库中的代码。
要同步文件仓库和本地的副本,您可以执行 update 子命令,语法如下:
$ cd project_dir
$ svn update
要了解更多的 SVN 子命令,您可以参考手册。例如要了解 co (checkout) 命令,请执行:
$ svn co help
6.5. 通过具有安全套接字(SSL)的自带协议访问(svn+ssh://)
配置和服务器进程于上节所述相同。我们假设您已经运行了“svnserve”命令。
我们还假设您运行了 ssh 服务并允许接入。要验证这一点,请尝试使用 ssh 登录计算机。如果您可以登录,那么大功告成,如果不能,请在执行下面的步骤前解决它。
svn+ssh:// 协议使用 SSL 加密来访问 SVN 文件仓库。如您所知,数据传输是加密的。要访问这样的文件仓库,请输入:
$ svn co svn+ssh://hostname/home/svn/myproject myproject --username user_name
注意:在这种方式下,您必须使用完整的路径(/home/svn/myproject)来访问 SVN 文件仓库
基于服务器的配置,它会要求输入密码。您必须输入您用于登录 ssh 的密码,一旦通过验证,就会签出文件仓库中的代码。
您还应该参考 SVN book 以了解关于 svn+ssh:// 协议的详细信息。
7. 参考资料
Setting up Apache on Ubuntu
SVN Home page
SVN Book
Apache 2 Documentation
Mod-SSL
Apache-SSL SvYLinux联盟
Linux联盟收集整理 ,转贴请标明原始链接,如有任何疑问欢迎来本站Linux论坛讨论
一直在关注着MYSQL的优化工作,但却也从来没有从硬件方面进行过探讨,前段时间有人在群里贴了一个msyql部落的链接,跑上去偷偷看了两眼,发现还是有点料的。以下就是其中的一点料:
http://www.mysqlsystems.com/?p=3
以前一直在MySQL的本家做咨询工作,所以我下面和大家讨论的话题是一个我在工作中经常遇到的问题。
什么时候我们应该升级硬件?什么时候应该修改配置?
作为DBA,老板和公司总是希望我们以最小的投入换来最大的性能(效益)。不过我并没有暗示大家,我接下讨论的话题,会是让各位避免购买硬件。
对于上面的答案很多人肯定会说两者都做,或者只做配置修改。我想我没有给大家出选择题,只是拿出来做任何一个考虑的时候,哪些因素影响着我们。我的回答经常是:
1.使劲优化MySQL服务器和查询语句
先看看别人的例子,或者仔细读一些MySQL的手册吧,这样你可以优化一些非常简单的my.cnf。也许最简单的index提高了几十倍的性能。不要轻易买硬件!
2. 先看看你的硬件整体架构是否平衡?
这个问题比较复杂,需要配合你的系统管理员来做,比较小的公司可能是一个人包了 这两个角色。我曾经去过一个沈阳的ISV那边,他们是一个大数据量,并发的使用MySQL。后来随着业务增加,其中三台IBM的P机放数据库的机器负担非 常重,后来老板下死令要dba调性能。DBA在尝试了很多种手册上的方法后,均无明显效果。后来在很多次交流以后才得知,他们信息中心还有4台机器跑着 Mail服务器,任务量非常轻。在建议他们利用上这些机器可能配置的情况下,性能很快就上去了
3. 没办法,服务器全用上了?
这种情况也非常常见,特别是对于那些服务器24小时都有人访问的web公司,如 youtube。如果用一些性能监视工具去监控整个服务器,结果看看一整天的流量和性能图,可能会大跌眼镜,服务并不是每时每刻都非常慢,而是某个特定时 间段,排除网络的原因,服务器备份的时候或者DBA下班的时候设置的半夜Cron工作总是对数据库有非常大的压力。
4. 还是买硬件吧,有什么建议?
性能调优有句老话,没有最好只有更好。一个系统的性能出现问题,是各个环节的累计造成的。用微观经济学的说法就是我们要使用边际成本最高的投入。
下面几种情况可以考虑相应的部件升级,经济危机了,整机成本太高而且是在没有必要。
IO读写太多,也许考虑买一条200块的内存?
增加CPU运算,也许考虑买一台x86的服务器,忘记Sun的CMT吧,因为MySQL的限制,使用不了这么多线程,反倒增加负担。
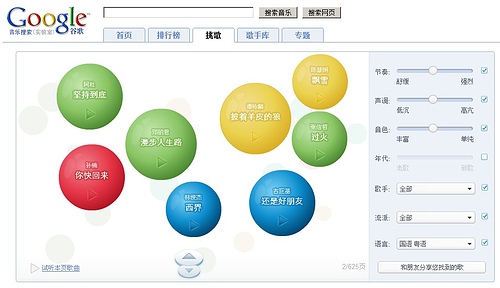
在google reader里闲逛的时候,看到了这个介绍,看界面,如果加上连线的话,就有点象微软那个“人立方”网站了。去了谷歌的网站,并尝试着根据上面的条件搜索了一下,发觉使用起来还是很方便的.
点击试听后会去一个top100.cn的网站,同样是采用了flash,估计是为了播放器可以兼容任何浏览器吧?还可以下载,只是不知道这些歌的版权如何处理(搞得象自己是FQ一样,装的很清高的样子,哈哈),下载的时候,提示来源是:file1.top100.cn,所以,黑黑。。。。
以下内容来自作者的介绍:http://www.awflasher.com/
我有幸在这个项目中扮演了主力ActionScript开发者和部分交互设计师的角色。
这个项目的交互创意、UI设计主要来自于Eicostudio(2004 年我大三的时候曾经膜拜过工作室创始人之一Rokey大牛的作品,他们都是国内最专业的UI设计师)和Google中国的UX团队。Google中国的 UX团队给予了我极大的帮助,在同Google UX团队的合作中,我能非常清楚地感受到他们每一个人对细节的执着追求和对中文搜索事业的敬业精神,每一个颜色,每一个字体样式,每一个UI组件的使用模 式和位置,都经过反复的斟酌才最终敲定。
同时,项目质量控制上面也要感谢J、M、B、T等谷歌Music团队的工程师的帮助。老实说,我从来没有在一个ActionScript项目中被内存回收折磨得不得不重写一个几千行的类 - 感谢诸位工程师的支持和建议。
具体如何使用我觉得就没必要具体介绍了吧,根据右侧的几个筛选条件进行选择,可以找到你想要的一种特定类型的音乐,十分方便,大家使用起来有什么意见和建议也欢迎在我的Blog留言。
本文来自:http://www.awflasher.com/blog/archives/1738