Objective-C是一种简单的计算机语言,设计为可以支持真正的面向对象 编程。Objective-C通过提供类定义,方法以及属性的语法,还有其他可以提高类的动态扩展能力的结构等,扩展了标准的ANSI C语言。类的语法和设计主要是基于Smalltalk,最早的面向对象编程语言之一。
如果你以前使用过其他面向对象编程语言,那么下面的信息可以帮助你学习Objective-C的基本语法。许多传统的面向对象概念,例如封装,继承 以及多态,在Objective-C中都有所体现。这里有一些重要的不同,但是这些不同在这文章会表现出来,而且如果你需要还有更多详细的信息存在。
如果你从来没有使用任何编程语言编过程序,那么你至少需要在开始之前,对相关概念进行一些基础的了解。对象的使用和对象对象架构是iPhone程序 设计的基础,理解他们如何交互对创建你的程序非常重要。想了解面向对象概念的,请参看使用Objective-C进行面向对象编程。此外,参看Cocoa 基础指南可以获得Cocoa中的面向对象设计模式的信息。
想了解更多Objective-C语言和语法的细节介绍,请参看Objective-C 2.0编程语言。
Objective-C: C的超集
Objective-C是ANSI版本C编程语言的超集,支持C的基本语法。在C代码中,你定义头文件和源代码文件,从代码实现细节分离公共声明。Objective-C头文件使用的文件名列在表1中。
表1 Objective-C代码的文件扩展名
| 扩展名 | 内容类型 |
| .h | 头文件。头文件包含类,类型,函数和常数的声明。 |
| .m | 源代码文件。这是典型的源代码文件扩展名,可以包含Objective-C和C代码。 |
| .mm | 源代码文件。带有这种扩展名的源代码文件,除了可以包含Objective-C和C代码以外还可以包含C++代码。仅在你的Objective-C代码中确实需要使用C++类或者特性的时候才用这种扩展名。 |
当你需要在源代码中包含头文件的时候,你可以使用标准的#include编译选项,但是Objective-C提供了更好的方 法。#import选项和#include选项完全相同,只是它可以确保相同的文件只会被包含一次。Objective-C的例子和文档都倾向于使 用#import,你的代码也应该是这样的。
字符串
作为C语言的超集,Objective-C支持C语言字符串方面的约定。也就是说,单个字符被单引号包括,字符串被双引号包括。然而,大多数 Objective-C通常不使用C语言风格的字符串。反之,大多数框架把字符串传递给NSString对象。NSString类提供了字符串的类包装, 包含了所有你期望的优点,包括对保存任意长度字符串的内建内存管理机制,支持Unicode,printf风格的格式化工具,等等。因为这种字符串使用的 非常频繁,Objective-C提供了一个助记符可以方便地从常量值创建NSString对象。要使用这个助记符,你需要做的全部事情,是在普通的双引 号字符串前放置一个@符号,如下面的例子所示:
NSString* myString = @"My String\n"; NSString* anotherString = [NSString stringWithFormat:@"%d %s", 1, @"String"]; // 从一个C语言字符串创建Objective-C字符串 NSString* fromCString = [NSString stringWithCString:"A C string" encoding:NSASCIIStringEncoding];
类
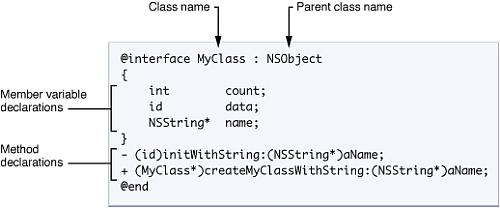
如同所有其他的面向对象语言,类是Objective-C用来封装数据,以及操作数据的行为的基础结构。对象就是类的运行期间实例,它包含了类声明 的实例变量自己的内存拷贝,以及类成员的指针。Objective-C的类规格说明包含了两个部分:接口和实现。接口部分包含了类声明和实例变量的定义, 以及类相关的方法。实现部分包含了类方法的实际代码。图1展现了声明一个叫做MyClass的类的语法,这个类继承自NSObject基础类。类声明总是 由@interface编译选项开始,由@end编译选项结束。类名之后的(用冒号分隔的)是父类的名字。类的实例(或者成员)变量声明在被大括号包含的 代码块中。实例变量块后面就是类声明的方法的列表。每个实例变量和方法声明都以分号结尾。
列表1展现了前面例子中MyClass类的实现。类同与类声明,类实现的位置也由两个编译选项确定,@implementation和@end。这 些选项给编译器提供了要将方法和对应类联系起来,所需的范围信息。因此方法的定义和接口中对应的声明是匹配的,只是多了个代码块而已。
列表1 类实现
@implementation MyClass - (id)initWithString:(NSString *) aName { if (self = [super init]) { count count = 0; data = nil; name = [aName copy]; return self; } } + (MyClass *)createMyClassWithString: (NSString *) aName { return [[[self alloc] initWithString:aName] autorelease]; } @end
注意: 虽然前面的类只声明了方法,但是类可以声明属性。想了解更多关于属性的信息,参看“属性”。
当用变量保存对象的时候,始终应该使用指针类型。Objective-C对变量包含的对象支持强弱两种类型。强类型指针的变量类型声明包含了类名。 弱类型指针使用id作为对象的类型。弱类型指针常用于类的集合,在集合中对象精确的类型可以是未知的。如果你用过强类型语言,你也许觉得使用弱类型变量可 能会带来问题,但是他们实际上给了Objective-C程序巨大的灵活性,而且使它更强大。
下面的例子里,展示了MyClass类的强类型和弱类型声明变量:
MyClass* myObject1; // Strong typing id myObject2; // Weak typing
方法
Objective-C中的类可以声明两种类型的方法:实例方法和类方法。实例方法就是一个方法,它在类的一个具体实例的范围内执行。也就是说,在你调用一个实例方法前,你必须首先创建类的一个实例。而类方法,比较起来,也就是说,不需要你创建一个实例。
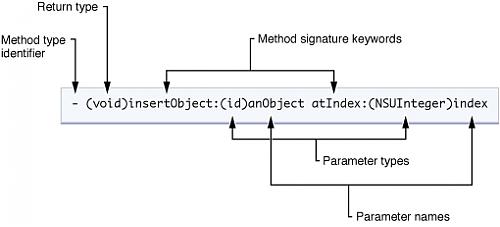
方法声明包括方法类型标识符,返回值类型,一个或多个方法标识关键字,参数类型和名信息。图2展示insertObject:atIndex:实例 方法的声明。声明由一个减号(-)开始,这表明这是一个实例方法。方法实际的名字(insertObject:atIndex:)是所有方法标识关键的级 联,包含了冒号。冒号表明了参数的出现。如果方法没有参数,你可以省略第一个(也是唯一的)方法标识关键字后面的冒号。本例中,这个方法有两个参数。
当你想调用一个方法,你传递消息到对应的对象。这里消息就是方法标识符,以及传递给方法的参数信息。发送给对象的所有消息都会动态分发,这样有利于 实现Objective-C类的多态行为。也就是说,如果子类定义了跟父类的具有相同标识符的方法,那么子类首先收到消息,然后可以有选择的把消息转发 (也可以不转发)给他的父类。
消息被中括号( [ 和 ] )包括。中括号中间,接收消息的对象在左边,消息(包括消息需要的任何参数)在右边。例如,给myArray变量传递消息insertObject:atIndex:消息,你需要使用如下的语法:
[myArray insertObject:anObj atIndex:0];
为了避免声明过多的本地变量保存临时结果,Objective-C允许你使用嵌套消息。每个嵌套消息的返回值可以作为其他消息的参数或者目标。例 如,你可以用任何获取这种值的消息来代替前面例子里面的任何变量。所以,如果你有另外一个对象叫做myAppObject拥有方法,可以访问数组对象,以 及插入对象到一个数组,你可以把前面的例子写成如下的样子:
[[myAppObject getArray] insertObject:[myAppObject getObjectToInsert] atIndex:0];
虽然前面的例子都是传递消息给某个类的实例,但是你也可以传递消息给类本身。当给类发消息,你指定的方法必须被定义为类方法,而不是实例方法。你可以认为类方法跟C++类里面的静态成员有点像(但是不是完全相同的)。
类方法的典型用途是用做创建新的类实例的工厂方法,或者是访问类相关的共享信息的途径。类方法声明的语法跟实例方法的几乎完全一样,只有一点小差别。与实例方法使用减号作为方法类型标识符不同,类方法使用加号( + )。
下面的例子演示了一个类方法如何作为类的工厂方法。在这里,arrayWithCapacity是NSMutableArray类的类方法,为类的新实例分配内容并初始化,然后返回给你。
NSMutableArray* myArray = nil; // nil is essentially the same as NULL // Create a new array and assign it to the myArray variable. myArray = [NSMutableArray arrayWithCapacity:0];
属性
属性是用来代替声明存取方法的便捷方式。属性不会在你的类声明中创建一个新的实例变量。他们仅仅是定义方法访问已有的实例变量的速记方式而已。暴露 实例变量的类,可以使用属性记号代替getter和setter语法。类还可以使用属性暴露一些“虚拟”的实例变量,他们是部分数据动态计算的结果,而不 是确实保存在实例变量内的。
实际上可以说,属性节约了你必须要些的大量多余的代码。因为大多数存取方法都是用类似的方式实现的,属性避免了为类暴露的每个实例变量提供不同的 getter和setter的需求。取而代之的是,你用属性声明指定你希望的行为,然后在编译期间合成基于声明的实际的getter和setter方法。
属性声明应该放在类接口的方法声明那里。基本的定义使用@property编译选项,紧跟着类型信息和属性的名字。你还可以用定制选项对属性进行配置,这决定了存取方法的行为。下面的例子展示了一些简单的属性声明:
@property BOOL flag; @property (copy) NSString* nameObject; // Copy the object during assignment. @property (readonly) UIView* rootView; // Create only a getter method.
使用属性另外的好处就是你可以在代码中访问他们的时候,使用点语法,如下面的例子所示:
myObject.flag = YES; CGRect viewFrame = myObject.rootView.frame;
虽然前面例子里面的对象和属性名是故意这么取的,他们还是展现了属性的灵活性。点语法实际上隐藏了对应的方法调用。每个可读的属性由一个与属性同名 的方法支持。每个可写属性由一个叫做“set属性名”的额外方法来支持,属性名的第一个字母要大写。(这些方法是属性的实际实现方式,也是你可以声明一个 没有任何实例变量支持的属性声明的原因。)如果用方法来代替前面代码中的属性,你就要下下面的代码:
[myObject setFlag:YES]; CGRect viewFrame = [[myObject rootView] frame];
要了解更多关于如何声明属性的信息,参看Objective-C 2.0编程语言的属性一章。
协议和代理
协议声明了可以被任何类实现的方法。协议不是那些类本身。他们仅是定义一个接口,其他的对象去负责实现。你实现了协议里面的方法,就叫做符合协议。
在iPhone OS中协议常用来实现委托对象。委托对象就是一个对象以其他的对象的模式行事。了解协议,委托和对象最好的办法就是看一个例子。
UIApplication类实现了一个程序需要的行为。如果想接收程序当前状态的简单消息,并不需要强制你创建UIApplication的一个 子类,反之UIApplication类通过调用委托对象的指定方法来分发这些通知消息。实现UIApplicationDelegate方法的对象都可 以接受这样的通知,并进行响应的反应。
协议的声明跟类接口的声明很像,只是协议没有父类,而且他们不会定义任何实例变量。下面的例子展示了一个有一个方法的协议声明:
@protocol MyProtocol - (void)myProtocolMethod; @end
在大多数委托协议情况下,使用某种协议仅仅是简单的实现协议定义的方法而已。 有些协议要求你明确的表明你支持这种协议,协议可以指定必须或者可选的方法。在你深入开发的过程中,你应该花点时间学习协议以及他们的用途,请阅读 Objective-C 2.0编程语言的协议章节。
更多的信息
前面的信息是为了让你对Objective-C语言的基础所有了解。本文提到的语言特性,你可以在阅读完整文档的时候找到。但是这个语言不仅仅有这些特性,所以最好请仔细阅读文档Objective-C 2.0编程语言。
参考:http://tiny4cocoa.com/doc/xcode-doc/learn-objective-c