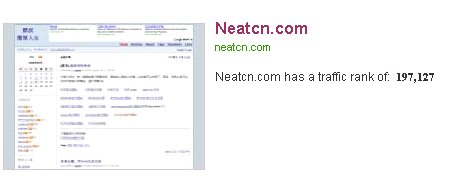
恭喜一下自己,alexa的排名终于进了20万位了
查看alexa上面本网站的排名
下面附上小图。。

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
Submitted by gouki on 2008, November 21, 10:50 AM
Submitted by gouki on 2008, November 20, 11:31 PM
原文地址:http://www.laruence.com/2008/11/20/630.html
膘叔的話:foreach是PHP語言里最常用的語法結構之一了,只要是數組操作,極大可能是會用到它,自從PHP5之后,它也能操作對象了。自此,foreach的使用率又上升了很多。但是有多少人知道它的背後原理呢?記得在以前的時候,好象是說foreach其實就是while( list )等的封裝。但由于一直沒有看過PHP的源碼也不能這么確定。(PS:如果用dezender等破解軟件破解PHP代碼,那么你會發現,代碼是foreach的那塊,都是被替換成while( list each )這種,所以我才會有上面的猜測)正好,看到風雪之隅有這個介紹,就轉貼一下。自己也可以學習一下。呵呵
foreach是PHP中很常用的一个用作数组循环的控制语句。
因为它的方便和易用,自然也就在后端隐藏着很复杂的具体实现方式(对用户透明)
今天,我们就来一起分析分析,foreach是如何实现数组(对象)的遍历的。
本节内容涉及到较多编译原理(lex and yacc)的知识,所以如果您觉得看不太懂,可以先找相关的资料看看。
我们知道PHP是一个脚本语言,也就是说,用户编写的PHP代码最终都是会被PHP解释器解释执行,
特别的,对于PHP来说,所有的用户编写的PHP代码,都会被翻译成PHP的虚拟机ZE的虚拟指令(OPCODES)来执行(参看:深入理解PHP原理之Opcodes).
不论细节的话,就是说,我们所编写的任何PHP脚本,都会最终被翻译成一条条的指令,从而根据指令,由相应的C编写的函数来执行。
那么foreach会被翻译成什么样子呢?
在词法分析阶段,foreach会被识别为一个TOKEN:T_FOREACH,
在语法分析阶段,会被规则:
仔细分析这段语法规则,我们可以发现,对于:
foreach($arr as $key => $val){
echo $key . ‘=>’ . $val .”\n”;
}
会被分析为:
也就是说,对于$key => $val的情况,yacc的内容栈对应的foreach_variable会被替换 {$$=$2};
然后,让我们来看看foreach_statement:
它其实就是一个代码块,体现了我们的 echo $key . ‘=>’ . $val .”\n”;
T_ECHO expr;
显然,实现foreach的核心就是如下3个函数:
zend_do_foreach_begin
zend_do_foreach_cont
zend_do_foreach_end
其中,zend_do_foreach_begin (代码太长,直接写伪码) 主要做了:
1. 记录当前的opline行数(为以后跳转而记录)
2. 对数组进行RESET(讲内部指针指向第一个元素)
3. 获取临时变量 ($val)
4. 设置获取变量的OPCODE FE_FETCH,结果存第3步的临时变量
4. 记录获取变量的OPCODES的行数
而对于 zend_do_foreach_cont来说:
1. 根据foreach_variable的u.EA.type来判断是否引用
2. 根据是否引用来调整zend_do_foreach_begin中生成的FE_FETCH方式
3. 根据zend_do_foreach_begin中记录的取变量的OPCODES的行数,来初始化循环(主要处理在循环内部的循环:do_begin_loop)
最后zend_do_foreach_end:
1. 根据zend_do_foreach_begin中记录的行数信息,设置ZEND_JMP OPCODES
2. 根据当前行数,设置循环体下一条opline, 用以跳出循环
3. 结束循环(处理循环内循环:do_end_loop)
4. 清理临时变量
当然, 在zend_do_foreach_cont 和 zend_do_foreach_end之间 会在语法分析阶段被填充foreach_satement的语句代码。
这样,就实现了foreach的OPCODES line。
比如对于我们开头的实例代码,最终生成的OPCODES是:
我们注意到FE_FETCH的op2的操作数是14,也就是JMP后一条opline,也就是说,在获取完最后一个数组元素以后,FE_FETCH失败的情况下,会跳到第14行opline,从而实现了循环的结束。
而15行opline的op1的操作数是指向了FE_FETCH,也就是无条件跳转到第5行opline,从而实现了循环。
附录:
Submitted by gouki on 2008, November 19, 11:39 PM
最早是14条,后来又补了20条,应该我没有记错吧。或者顺序反了?先是20条才是14条?
不过对于大多数人来说,优化css和js是比较重要的,还有 就是尽量在一个页面内出现超过四个域名 的情况。不容易变换的图片采用缓存等等。
当然我也不多说了,直接看文章吧。。。
英文地址:http://developer.yahoo.com/performance/rules.html
中文地址:http://www.dudo.org/article.asp?id=214
Yahoo!的Exceptional Performance团队为改善Web性能带来最佳实践。他们为此进行了一系列的实验、开发了各种工具、写了大量的文章和博客并在各种会议上参与探讨。最佳实践的核心就是旨在提高网站性能。
Excetional Performance团队总结出了一系列可以提高网站速度的方法。可以分为7大类34条。包括内容、服务器、cookie、CSS、JavaScript、图片、移动应用等七部分。
其中内容部分一共十条建议:
一、内容部分
1、尽量减少HTTP请求次数
终端用户响应的时间中,有80%用于下载各项内容。这部分时间包括下载页面中的图像、样式表、脚本、Flash等。通过减少页面中的元素可以减少HTTP请求的次数。这是提高网页速度的关键步骤。
减少页面组件的方法其实就是简化页面设计。那么有没有一种方法既能保持页面内容的丰富性又能达到加快响应时间的目的呢?这里有几条减少HTTP请求次数同时又可能保持页面内容丰富的技术。
合并文件是通过把所有的脚本放到一个文件中来减少HTTP请求的方法,如可以简单地把所有的CSS文件都放入一个样式表中。当脚本或者样式表在不同页面中使用时需要做不同的修改,这可能会相对麻烦点,但即便如此也要把这个方法作为改善页面性能的重要一步。
CSS Sprites是减少图像请求的有效方法。把所有的背景图像都放到一个图片文件中,然后通过CSS的background-image和background-position属性来显示图片的不同部分;
图片地图是把多张图片整合到一张图片中。虽然文件的总体大小不会改变,但是可以减少HTTP请求次数。图片地图只有在 图片的所有组成部分在页面中是紧挨在一起的时候才能使用,如导航栏。确定图片的坐标和可能会比较繁琐且容易出错,同时使用图片地图导航也不具有可读性,因 此不推荐这种方法;
内联图像是使用data:URL scheme的方法把图像数据加载页面中。这可能会增加页面的大小。把内联图像放到样式表(可缓存)中可以减少HTTP请求同时又避免增加页面文件的大小。但是内联图像现在还没有得到主流浏览器的支持。
减少页面的HTTP请求次数是你首先要做的一步。这是改进首次访问用户等待时间的最重要的方法。如同Tenni Theurer的他的博客Browser Cahe Usage - Exposed!中所说,HTTP请求在无缓存情况下占去了40%到60%的响应时间。让那些初次访问你网站的人获得更加快速的体验吧!
2、减少DNS查找次数
域名系统(DNS)提供了域名和IP的对应关系,就像电话本中人名和他们的电话号码的关系一样。当你在浏览器地址栏中输入www.dudo.org时,DNS解析服务器就会返回这个域名对应的IP地址。DNS解析的过程同样也是需要时间的。一般情况下返回给定域名对应的IP地址会花费20到120毫秒的时间。而且在这个过程中浏览器什么都不会做直到DNS查找完毕。
缓存DNS查找可以改善页面性能。这种缓存需要一个特定的缓存服务器,这种服务器一般属于用户的ISP提供商或者本地局域网控制,但是它同样会在用户使用 的计算机上产生缓存。DNS信息会保留在操作系统的DNS缓存中(微软Windows系统中DNS Client Service)。大多数浏览器有独立于操作系统以外的自己的缓存。由于浏览器有自己的缓存记录,因此在一次请求中它不会受到操作系统的影响。
Internet Explorer默认情况下对DNS查找记录的缓存时间为30分钟,它在注册表中的键值为DnsCacheTimeout。Firefox对DNS的查找 记录缓存时间为1分钟,它在配置文件中的选项为network.dnsCacheExpiration(Fasterfox把这个选项改为了1小时)。
当客户端中的DNS缓存都为空时(浏览器和操作系统都为空),DNS查找的次数和页面中主机名的数量相同。这其中包括页面中URL、图片、脚本文件、样式表、Flash对象等包含的主机名。减少主机名的数量可以减少DNS查找次数。
减少主机名的数量还可以减少页面中并行下载的数量。减少DNS查找次数可以节省响应时间,但是减少并行下载却会增加响应时间。我的指导原则是把这些页面中 的内容分割成至少两部分但不超过四部分。这种结果就是在减少DNS查找次数和保持较高程度并行下载两者之间的权衡了。
3、避免跳转
跳转是使用301和302代码实现的。下面是一个响应代码为301的HTTP头:
HTTP/1.1 301 Moved Permanently
Location: http://example.com/newuri
Content-Type: text/html
浏览器会把用户指向到Location中指定的URL。头文件中的所有信息在一次跳转中都是必需的,内容部分可以为空。不管他们的名称,301和302响 应都不会被缓存除非增加一个额外的头选项,如Expires或者Cache-Control来指定它缓存。<meat />元素的刷新标签和JavaScript也可以实现URL的跳转,但是如果你必须要跳转的时候,最好的方法就是使用标准的3XXHTTP状态代 码,这主要是为了确保“后退”按钮可以正确地使用。
但是要记住跳转会降低用户体验。在用户和HTML文档中间增加一个跳转,会拖延页面中所有元素的显示,因为在HTML文件被加载前任何文件(图像、Flash等)都不会被下载。
有一种经常被网页开发者忽略却往往十分浪费响应时间的跳转现象。这种现象发生在当URL本该有斜杠(/)却被忽略掉时。例如,当我们要访问http: //astrology.yahoo.com/astrology 时,实际上返回的是一个包含301代码的跳转,它指向的是http://astrology.yahoo.com/astrology/ (注意末尾的斜杠)。在Apache服务器中可以使用Alias 或者 mod_rewrite或者the DirectorySlash来避免。
连接新网站和旧网站是跳转功能经常被用到的另一种情况。这种情况下往往要连接网站的不同内容然后根据用户的不同类型(如浏览器类型、用户账号所属类型)来 进行跳转。使用跳转来实现两个网站的切换十分简单,需要的代码量也不多。尽管使用这种方法对于开发者来说可以降低复杂程度,但是它同样降低用户体验。一个 可替代方法就是如果两者在同一台服务器上时使用Alias和mod_rewrite和实现。如果是因为域名的不同而采用跳转,那么可以通过使用Alias 或者mod_rewirte建立CNAME(保存一个域名和另外一个域名之间关系的DNS记录)来替代。
4、可缓存的AJAX
Ajax经常被提及的一个好处就是由于其从后台服务器传输信息的异步性而为用户带来的反馈的即时性。但是,使用Ajax并不能保证用户不会在等待异步的 JavaScript和XML响应上花费时间。在很多应用中,用户是否需要等待响应取决于Ajax如何来使用。例如,在一个基于Web的Email客户端 中,用户必须等待Ajax返回符合他们条件的邮件查询结果。记住一点,“异步”并不异味着“即时”,这很重要。
为了提高性能,优化Ajax响应是很重要的。提高Ajxa性能的措施中最重要的方法就是使响应具有可缓存性,具体的讨论可以查看Add an Expires or a Cache-Control Header。其它的几条规则也同样适用于Ajax:
Gizp压缩文件
减少DNS查找次数
精简JavaScript
避免跳转
配置ETags
让我们来看一个例子:一个Web2.0的Email客户端会使用Ajax来自动完成对用户地址薄的下载。如果用户在上次使用过Email web应用程序后没有对地址薄作任何的修改,而且Ajax响应通过Expire或者Cacke-Control头来实现缓存,那么就可以直接从上一次的缓 存中读取地址薄了。必须告知浏览器是使用缓存中的地址薄还是发送一个新的请求。这可以通过为读取地址薄的Ajax URL增加一个含有上次编辑时间的时间戳来实现,例如,&t=11900241612等。如果地址薄在上次下载后没有被编辑过,时间戳就不变,则 从浏览器的缓存中加载从而减少了一次HTTP请求过程。如果用户修改过地址薄,时间戳就会用来确定新的URL和缓存响应并不匹配,浏览器就会重要请求更新 地址薄。
即使你的Ajxa响应是动态生成的,哪怕它只适用于一个用户,那么它也应该被缓存起来。这样做可以使你的Web2.0应用程序更加快捷。
5、推迟加载内容
你可以仔细看一下你的网页,问问自己“哪些内容是页面呈现时所必需首先加载的?哪些内容和结构可以稍后再加载?
把整个过程按照onload事件分隔成两部分,JavaScript是一个理想的选择。例如,如果你有用于实现拖放和动画的JavaScript,那么它 就以等待稍后加载,因为页面上的拖放元素是在初始化呈现之后才发生的。其它的例如隐藏部分的内容(用户操作之后才显现的内容)和处于折叠部分的图像也可以 推迟加载
工具可以节省你的工作量:YUI Image Loader可以帮你推迟加载折叠部分的图片,YUI Get utility是包含JS和 CSS的便捷方法。比如你可以打开Firebug的Net选项卡看一下Yahoo的首页。
当性能目标和其它网站开发实践一致时就会相得益彰。这种情况下,通过程序提高网站性能的方法告诉我们,在支持JavaScript的情况下,可以先去除用 户体验,不过这要保证你的网站在没有JavaScript也可以正常运行。在确定页面运行正常后,再加载脚本来实现如拖放和动画等更加花哨的效果。
6、预加载
预加载和后加载看起来似乎恰恰相反,但实际上预加载是为了实现另外一种目标。预加载是在浏览器空闲时请求将来可能会用到的页面内容(如图像、样式表和脚 本)。使用这种方法,当用户要访问下一个页面时,页面中的内容大部分已经加载到缓存中了,因此可以大大改善访问速度。
下面提供了几种预加载方法:
无条件加载:触发onload事件时,直接加载额外的页面内容。以Google.com为例,你可以看一下它的spirit image图像是怎样在onload中加载的。这个spirit image图像在google.com主页中是不需要的,但是却可以在搜索结果页面中用到它。
有条件加载:根据用户的操作来有根据地判断用户下面可能去往的页面并相应的预加载页面内容。在search.yahoo.com中你可以看到如何在你输入内容时加载额外的页面内容。
有预期的加载:载入重新设计过的页面时使用预加载。这种情况经常出现在页面经过重新设计后用户抱怨“新的页面看起来很 酷,但是却比以前慢”。问题可能出在用户对于你的旧站点建立了完整的缓存,而对于新站点却没有任何缓存内容。因此你可以在访问新站之前就加载一部内容来避 免这种结果的出现。在你的旧站中利用浏览器的空余时间加载新站中用到的图像的和脚本来提高访问速度。
7、减少DOM元素数量
一个复杂的页面意味着需要下载更多数据,同时也意味着JavaScript遍历DOM的效率越慢。比如当你增加一个事件句柄时在500和5000个DOM元素中循环效果肯定是不一样的。
大量的DOM元素的存在意味着页面中有可以不用移除内容只需要替换元素标签就可以精简的部分。你在页面布局中使用表格了吗?你有没有仅仅为了布局而引入更多的<div>元素呢?也许会存在一个适合或者在语意是更贴切的标签可以供你使用。
YUI CSS utilities可以给你的布局带来巨大帮助:grids.css可以帮你实现整体布局,font.css和reset.css可以帮助你移除浏览器默 认格式。它提供了一个重新审视你页面中标签的机会,比如只有在语意上有意义时才使用<div>,而不是因为它具有换行效果才使用它。
DOM元素数量很容易计算出来,只需要在Firebug的控制台内输入:
document.getElementsByTagName('*').length
那么多少个DOM元素算是多呢?这可以对照有很好标记使用的类似页面。比如Yahoo!主页是一个内容非常多的页面,但是它只使用了700个元素(HTML标签)。
8、根据域名划分页面内容
把页面内容划分成若干部分可以使你最大限度地实现平行下载。由于DNS查找带来的影响你首先要确保你使用的域名数量在2个到4个之间。例如,你可以把用到 的HTML内容和动态内容放在www.example.org上,而把页面各种组件(图片、脚本、CSS)分别存放在 statics1.example.org和statics.example.org上。
你可在Tenni Theurer和Patty Chi合写的文章Maximizing Parallel Downloads in the Carpool Lane找到更多相关信息。
9、使iframe的数量最小
ifrmae元素可以在父文档中插入一个新的HTML文档。了解iframe的工作理然后才能更加有效地使用它,这一点很重要。
<iframe>优点:
<iframe>的缺点:
10、不要出现404错误
HTTP请求时间消耗是很大的,因此使用HTTP请求来获得一个没有用处的响应(例如404没有找到页面)是完全没有必要的,它只会降低用户体验而不会有一点好处。
有些站点把404错误响应页面改为“你是不是要找***”,这虽然改进了用户体验但是同样也会浪费服务器资源(如数据库等)。最糟糕的情况是指向外部 JavaScript的链接出现问题并返回404代码。首先,这种加载会破坏并行加载;其次浏览器会把试图在返回的404响应内容中找到可能有用的部分当 作JavaScript代码来执行。
在本系列的第一节中,讲了提高网站性能中网站“内容”有关的10条原则。除了在网站在内容上的改进外,在网站服务器端上也有需要注意和改进的地方,它们包括:
11、使用内容分发网络
用户与你网站服务器的接近程度会影响响应时间的长短。把你的网站内容分散到多个、处于不同地域位置的服务器上可以加快下载速度。但是首先我们应该做些什么呢?
按地域布置网站内容的第一步并不是要尝试重新架构你的网站让他们在分发服务器上正常运行。根据应用的需求来改变网站结构,这可能会包括一些比较复杂的任 务,如在服务器间同步Session状态和合并数据库更新等。要想缩短用户和内容服务器的距离,这些架构步骤可能是不可避免的。
要记住,在终端用户的响应时间中有80%到90%的响应时间用于下载图像、样式表、脚本、Flash等页面内容。这就是网站性能黄金守则。和重新设计你的 应用程序架构这样比较困难的任务相比,首先来分布静态内容会更好一点。这不仅会缩短响应时间,而且对于内容分发网络来说它更容易实现。
内容分发网络(Content Delivery Network,CDN)是由一系列分散到各个不同地理位置上的Web服务器组成的,它提高了网站内容的传输速度。用于向用户传输内容的服务器主要是根据 和用户在网络上的靠近程度来指定的。例如,拥有最少网络跳数(network hops)和响应速度最快的服务器会被选定。
一些大型的网络公司拥有自己的CDN,但是使用像Akamai Technologies,Mirror Image Internet, 或者Limelight Networks这 样的CDN服务成本却非常高。对于刚刚起步的企业和个人网站来说,可能没有使用CDN的成本预算,但是随着目标用户群的不断扩大和更加全球化,CDN就是 实现快速响应所必需的了。以Yahoo来说,他们转移到CDN上的网站程序静态内容节省了终端用户20%以上的响应时间。使用CDN是一个只需要相对简单 地修改代码实现显著改善网站访问速度的方法。
12、为文件头指定Expires或Cache-Control
这条守则包括两方面的内容:
对于静态内容:设置文件头过期时间Expires的值为“Never expire”(永不过期)
对于动态内容:使用恰当的Cache-Control文件头来帮助浏览器进行有条件的请求
网页内容设计现在越来越丰富,这就意味着页面中要包含更多的脚本、样式表、图片和Flash。第一次访问你页面的用户就意味着进行多次的HTTP请求,但 是通过使用Expires文件头就可以使这样内容具有缓存性。它避免了接下来的页面访问中不必要的HTTP请求。Expires文件头经常用于图像文件, 但是应该在所有的内容都使用他,包括脚本、样式表和Flash等。
浏览器(和代理)使用缓存来减少HTTP请求的大小和次数以加快页面访问速度。Web服务器在HTTP响应中使用Expires文件头来告诉客户端内容需 要缓存多长时间。下面这个例子是一个较长时间的Expires文件头,它告诉浏览器这个响应直到2010年4月15日才过期。
Expires: Thu, 15 Apr 2010 20:00:00 GMT
如果你使用的是Apache服务器,可以使用ExpiresDefault来设定相对当前日期的过期时间。下面这个例子是使用ExpiresDefault来设定请求时间后10年过期的文件头:
ExpiresDefault "access plus 10 years"
要切记,如果使用了Expires文件头,当页面内容改变时就必须改变内容的文件名。依Yahoo!来说我们经常使用这样的步骤:在内容的文件名中加上版本号,如yahoo_2.0.6.js。
使用Expires文件头只有会在用户已经访问过你的网站后才会起作用。当用户首次访问你的网站时这对减少HTTP请求次数来说是无效的,因为浏览器的缓 存是空的。因此这种方法对于你网站性能的改进情况要依据他们“预缓存”存在时对你页面的点击频率(“预缓存”中已经包含了页面中的所有内容)。Yahoo!建立了一套测量方法,我们发现所有的页面浏览量中有75~85%都有“预缓存”。通过使用Expires文件头,增加了缓存在浏览器中内容的数量,并且可以在用户接下来的请求中再次使用这些内容,这甚至都不需要通过用户发送一个字节的请求。
13、Gzip压缩文件内容
网络传输中的HTTP请求和应答时间可以通过前端机制得到显著改善。的确,终端用户的带宽、互联网提供者、与对等交换点的靠近程度等都不是网站开发者所能决定的。但是还有其他因素影响着响应时间。通过减小HTTP响应的大小可以节省HTTP响应时间。
从HTTP/1.1开始,web客户端都默认支持HTTP请求中有Accept-Encoding文件头的压缩格式:
Accept-Encoding: gzip, deflate
如果web服务器在请求的文件头中检测到上面的代码,就会以客户端列出的方式压缩响应内容。Web服务器把压缩方式通过响应文件头中的Content-Encoding来返回给浏览器。
Content-Encoding: gzip
Gzip是目前最流行也是最有效的压缩方式。这是由GNU项目开发并通过RFC 1952来标准化的。另外仅有的一个压缩格式是deflate,但是它的使用范围有限效果也稍稍逊色。
Gzip大概可以减少70%的响应规模。目前大约有90%通过浏览器传输的互联网交换支持gzip格式。如果你使用的是Apache,gzip模块配置和你的版本有关:Apache 1.3使用mod_zip,而Apache 2.x使用moflate。
浏览器和代理都会存在这样的问题:浏览器期望收到的和实际接收到的内容会存在不匹配的现象。幸好,这种特殊情况随着旧式浏览器使用量的减少在减少。Apache模块会通过自动添加适当的Vary响应文件头来避免这种状况的出现。
服务器根据文件类型来选择需要进行gzip压缩的文件,但是这过于限制了可压缩的文件。大多数web服务器会压缩HTML文档。对脚本和样式表进行压缩同 样也是值得做的事情,但是很多web服务器都没有这个功能。实际上,压缩任何一个文本类型的响应,包括XML和JSON,都值得的。图像和PDF文件由于 已经压缩过了所以不能再进行gzip压缩。如果试图gizp压缩这些文件的话不但会浪费CPU资源还会增加文件的大小。
Gzip压缩所有可能的文件类型是减少文件体积增加用户体验的简单方法。
14、配置ETag
Entity tags(ETags)(实体标签)是web服务器和浏览器用于判断浏览器缓存中的内容和服务器中的原始内容是否匹配的一种机制(“实体”就是所说的“内 容”,包括图片、脚本、样式表等)。增加ETag为实体的验证提供了一个比使用“last-modified date(上次编辑时间)”更加灵活的机制。Etag是一个识别内容版本号的唯一字符串。唯一的格式限制就是它必须包含在双引号内。原始服务器通过含有 ETag文件头的响应指定页面内容的ETag。
HTTP/1.1 200 OK
Last-Modified: Tue, 12 Dec 2006 03:03:59 GMT
ETag: "10c24bc-4ab-457e1c1f"
Content-Length: 12195
稍后,如果浏览器要验证一个文件,它会使用If-None-Match文件头来把ETag传回给原始服务器。在这个例子中,如果ETag匹配,就会返回一 个304状态码,这就节省了12195字节的响应。 GET /i/yahoo.gif HTTP/1.1
Host: us.yimg.com
If-Modified-Since: Tue, 12 Dec 2006 03:03:59 GMT
If-None-Match: "10c24bc-4ab-457e1c1f"
HTTP/1.1 304 Not Modified
ETag的问题在于,它是根据可以辨别网站所在的服务器的具有唯一性的属性来生成的。当浏览器从一台服务器上获得页面内容后到另外一台服务器上进行验证时 ETag就会不匹配,这种情况对于使用服务器组和处理请求的网站来说是非常常见的。默认情况下,Apache和IIS都会把数据嵌入ETag中,这会显著 减少多服务器间的文件验证冲突。
Apache 1.3和2.x中的ETag格式为inode-size-timestamp。即使某个文件在不同的服务器上会处于相同的目录下,文件大小、权限、时间戳等都完全相同,但是在不同服务器上他们的内码也是不同的。
IIS 5.0和IIS 6.0处理ETag的机制相似。IIS中的ETag格式为Filetimestamp:ChangeNumber。用ChangeNumber来跟踪 IIS配置的改变。网站所用的不同IIS服务器间ChangeNumber也不相同。 不同的服务器上的Apache和IIS即使对于完全相同的内容产生的ETag在也不相同,用户并不会接收到一个小而快的304响应;相反他们会接收一个正 常的200响应并下载全部内容。如果你的网站只放在一台服务器上,就不会存在这个问题。但是如果你的网站是架设在多个服务器上,并且使用Apache和 IIS产生默认的ETag配置,你的用户获得页面就会相对慢一点,服务器会传输更多的内容,占用更多的带宽,代理也不会有效地缓存你的网站内容。即使你的 内容拥有Expires文件头,无论用户什么时候点击“刷新”或者“重载”按钮都会发送相应的GET请求。
如果你没有使用ETag提供的灵活的验证模式,那么干脆把所有的ETag都去掉会更好。Last-Modified文件头验证是基于内容的时间戳的。去掉ETag文件头会减少响应和下次请求中文件的大小。微软的这篇支持文稿讲述了如何去掉ETag。在Apache中,只需要在配置文件中简单添加下面一行代码就可以了:
FileETag none
15、尽早刷新输出缓冲
当用户请求一个页面时,无论如何都会花费200到500毫秒用于后台组织HTML文件。在这期间,浏览器会一直空闲等待数据返回。在PHP中,你可以使用 flush()方法,它允许你把已经编译的好的部分HTML响应文件先发送给浏览器,这时浏览器就会可以下载文件中的内容(脚本等)而后台同时处理剩余的 HTML页面。这样做的效果会在后台烦恼或者前台较空闲时更加明显。
输出缓冲应用最好的一个地方就是紧跟在<head />之后,因为HTML的头部分容易生成而且头部往往包含CSS和JavaScript文件,这样浏览器就可以在后台编译剩余HTML的同时并行下载它们。 例子:
... <!-- css, js -->
</head>
<?php flush(); ?>
<body>
... <!-- content -->
为了证明使用这项技术的好处,Yahoo!搜索率先研究并完成了用户测试。
16、使用GET来完成AJAX请求
Yahoo!Mail团 队发现,当使用XMLHttpRequest时,浏览器中的POST方法是一个“两步走”的过程:首先发送文件头,然后才发送数据。因此使用GET最为恰 当,因为它只需发送一个TCP包(除非你有很多cookie)。IE中URL的最大长度为2K,因此如果你要发送一个超过2K的数据时就不能使用GET 了。
一个有趣的不同就是POST并不像GET那样实际发送数据。根据HTTP规范,GET意味着“获取”数据,因此当你仅仅获取数据时使用GET更加有意义(从语意上讲也是如此),相反,发送并在服务端保存数据时使用POST。
在第一部分和第二部分中我们分别介绍了改善网站性能中页面内容和服务器的几条守则,除此之外,JavaScript和CSS也是我们页面中经常用到的内容,对它们的优化也提高网站性能的重要方面:
CSS:
JavaScript
17、把样式表置于顶部
在研究Yahoo!的性能表现时,我们发现把样式表放到文档的<head />内部似乎会加快页面的下载速度。这是因为把样式表放到<head />内会使页面有步骤的加载显示。
注重性能的前端服务器往往希望页面有秩序地加载。同时,我们也希望浏览器把已经接收到内容尽可能显示出来。这对于拥有较多内容的页面和网速较慢的用户来说特别重要。向用户返回可视化的反馈,比如进程指针,已经有了较好的研究并形成了正式文档。在我们的研究中HTML页面就是进程指针。当浏览器有序地加载文件头、导航栏、顶部的logo等对于等待页面加载的用户来说都可以作为可视化的反馈。这从整体上改善了用户体验。
把样式表放在文档底部的问题是在包括Internet Explorer在内的很多浏览器中这会中止内容的有序呈现。浏览器中止呈现是为了避免样式改变引起的页面元素重绘。用户不得不面对一个空白页面。
HTML规范清 楚指出样式表要放包含在页面的<head />区域内:“和<a />不同,<link />只能出现在文档的<head />区域内,尽管它可以多次使用它”。无论是引起白屏还是出现没有样式化的内容都不值得去尝试。最好的方案就是按照HTML规范在文 档<head />内加载你的样式表。
18、避免使用CSS表达式(Expression)
CSS表达式是动态设置CSS属性的强大(但危险)方法。Internet Explorer从第5个版本开始支持CSS表达式。下面的例子中,使用CSS表达式可以实现隔一个小时切换一次背景颜色:
background-color: expression( (new Date()).getHours()%2 ? "#B8D4FF" : "#F08A00" );
如上所示,expression中使用了JavaScript表达式。CSS属性根据JavaScript表达式的计算结果来设置。expression方法在其它浏览器中不起作用,因此在跨浏览器的设计中单独针对Internet Explorer设置时会比较有用。
表达式的问题就在于它的计算频率要比我们想象的多。不仅仅是在页面显示和缩放时,就是在页面滚动、乃至移动鼠标时都会要重新计算一次。给CSS表达式增加一个计数器可以跟踪表达式的计算频率。在页面中随便移动鼠标都可以轻松达到10000次以上的计算量。
一个减少CSS表达式计算次数的方法就是使用一次性的表达式,它在第一次运行时将结果赋给指定的样式属性,并用这个属性来代替CSS表达式。如果样式属性 必须在页面周期内动态地改变,使用事件句柄来代替CSS表达式是一个可行办法。如果必须使用CSS表达式,一定要记住它们要计算成千上万次并且可能会对你 页面的性能产生影响。
19、使用外部JavaScript和CSS
很多性能规则都是关于如何处理外部文件的。但是,在你采取这些措施前你可能会问到一个更基本的问题:JavaScript和CSS是应该放在外部文件中呢还是把它们放在页面本身之内呢?
在实际应用中使用外部文件可以提高页面速度,因为JavaScript和CSS文件都能在浏览器中产生缓存。内置在HTML文档中的JavaScript 和CSS则会在每次请求中随HTML文档重新下载。这虽然减少了HTTP请求的次数,却增加了HTML文档的大小。从另一方面来说,如果外部文件中的 JavaScript和CSS被浏览器缓存,在没有增加HTTP请求次数的同时可以减少HTML文档的大小。
关键问题是,外部JavaScript和CSS文件缓存的频率和请求HTML文档的次数有关。虽然有一定的难度,但是仍然有一些指标可以一测量它。如果一 个会话中用户会浏览你网站中的多个页面,并且这些页面中会重复使用相同的脚本和样式表,缓存外部文件就会带来更大的益处。
许多网站没有功能建立这些指标。对于这些网站来说,最好的坚决方法就是把JavaScript和CSS作为外部文件引用。比较适合使用内置代码的例外就是网站的主页,如Yahoo!主页和My Yahoo!。主页在一次会话中拥有较少(可能只有一次)的浏览量,你可以发现内置JavaScript和CSS对于终端用户来说会加快响应时 间。
对于拥有较大浏览量的首页来说,有一种技术可以平衡内置代码带来的HTTP请求减少与通过使用外部文件进行缓存带来的好处。其中一个就是在首页中内置 JavaScript和CSS,但是在页面下载完成后动态下载外部文件,在子页面中使用到这些文件时,它们已经缓存到浏览器了。
20、削减JavaScript和CSS
精简是指从去除代码不必要的字符减少文件大小从而节省下载时间。消减代码时,所有的注释、不需要的空白字符(空格、换行、tab缩进)等都要去掉。在 JavaScript中,由于需要下载的文件体积变小了从而节省了响应时间。精简JavaScript中目前用到的最广泛的两个工具是JSMin和YUI Compressor。YUI Compressor还可用于精简CSS。
混淆是另外一种可用于源代码优化的方法。这种方法要比精简复杂一些并且在混淆的过程更易产生问题。在对美国前10大网站的调查中发现,精简也可以缩小原来 代码体积的21%,而混淆可以达到25%。尽管混淆法可以更好地缩减代码,但是对于JavaScript来说精简的风险更小。
除消减外部的脚本和样式表文件外,<script>和<style>代码块也可以并且应该进行消减。即使你用Gzip压缩过脚本 和样式表,精简这些文件仍然可以节省5%以上的空间。由于JavaScript和CSS的功能和体积的增加,消减代码将会获得益处。
21、用<link>代替@import
前面的最佳实现中提到CSS应该放置在顶端以利于有序加载呈现。
在IE中,页面底部@import和使用<link>作用是一样的,因此最好不要使用它。
22、避免使用滤镜
IE独有属性AlphaImageLoader用于修正7.0以下版本中显示PNG图片的半透明效果。这个滤镜的问题在于浏览器加载图片时它会终止内容的 呈现并且冻结浏览器。在每一个元素(不仅仅是图片)它都会运算一次,增加了内存开支,因此它的问题是多方面的。
完全避免使用AlphaImageLoader的最好方法就是使用PNG8格式来代替,这种格式能在IE中很好地工作。如果你确实需要使用AlphaImageLoader,请使用下划线_filter又使之对IE7以上版本的用户无效。
23、把脚本置于页面底部
脚本带来的问题就是它阻止了页面的平行下载。HTTP/1.1 规范建议,浏览器每个主机名的并行下载内容不超过两个。如果你的图片放在多个主机名上,你可以在每个并行下载中同时下载2个以上的文件。但是当下载脚本时,浏览器就不会同时下载其它文件了,即便是主机名不相同。
在某些情况下把脚本移到页面底部可能不太容易。比如说,如果脚本中使用了document.write来插入页面内容,它就不能被往下移动了。这里可能还会有作用域的问题。很多情况下,都会遇到这方面的问题。
一个经常用到的替代方法就是使用延迟脚本。DEFER属性表明脚本中没有包含document.write,它告诉浏览器继续显示。不幸的 是,Firefox并不支持DEFER属性。在Internet Explorer中,脚本可能会被延迟但效果也不会像我们所期望的那样。如果脚本可以被延迟,那么它就可以移到页面的底部。这会让你的页面加载的快一点。
24、剔除重复脚本
在同一个页面中重复引用JavaScript文件会影响页面的性能。你可能会认为这种情况并不多见。对于美国前10大网站的调查显示其中有两家存在重复引 用脚本的情况。有两种主要因素导致一个脚本被重复引用的奇怪现象发生:团队规模和脚本数量。如果真的存在这种情况,重复脚本会引起不必要的HTTP请求和 无用的JavaScript运算,这降低了网站性能。
在Internet Explorer中会产生不必要的HTTP请求,而在Firefox却不会。在Internet Explorer中,如果一个脚本被引用两次而且它又不可缓存,它就会在页面加载过程中产生两次HTTP请求。即时脚本可以缓存,当用户重载页面时也会产 生额外的HTTP请求。
除增加额外的HTTP请求外,多次运算脚本也会浪费时间。在Internet Explorer和Firefox中不管脚本是否可缓存,它们都存在重复运算JavaScript的问题。
一个避免偶尔发生的两次引用同一脚本的方法是在模板中使用脚本管理模块引用脚本。在HTML页面中使用<script />标签引用脚本的最常见方法就是:
<script type="text/javascript" src="menu_1.0.17.js"></script>
在PHP中可以通过创建名为insertScript的方法来替代:
<?php insertScript("menu.js") ?>
为了防止多次重复引用脚本,这个方法中还应该使用其它机制来处理脚本,如检查所属目录和为脚本文件名中增加版本号以用于Expire文件头等。
25、减少DOM访问
使用JavaScript访问DOM元素比较慢,因此为了获得更多的应该页面,应该做到:
有关此方面的更多信息请查看Julien Lecomte在YUI专题中的文章“高性能Ajax应该程序”。
26、开发智能事件处理程序
有时候我们会感觉到页面反应迟钝,这是因为DOM树元素中附加了过多的事件句柄并且些事件句病被频繁地触发。这就是为什么说使用event delegation(事件代理)是一种好方法了。如果你在一个div中有10个按钮,你只需要在div上附加一次事件句柄就可以了,而不用去为每一个按 钮增加一个句柄。事件冒泡时你可以捕捉到事件并判断出是哪个事件发出的。
你同样也不用为了操作DOM树而等待onload事件的发生。你需要做的就是等待树结构中你要访问的元素出现。你也不用等待所有图像都加载完毕。
你可能会希望用DOMContentLoaded事件来代替onload,但是在所有浏览器都支持它之前你可使用YUI 事件应用程序中的onAvailable方法。
有关此方面的更多信息请查看Julien Lecomte在YUI专题中的文章“高性能Ajax应该程序”。
我们在前面的几节中分别讲了提高网站性能中内容、服务器、JavaScript和CSS等方面的内容。除此之外,图片和Coockie也是我们网站中几乎不可缺少组成部分,此外随着移动设备的流行,对于移动应用的优化也十分重要。这主要包括:
Coockie:
图片:
移动应用:
27、减小Cookie体积
HTTP coockie可以用于权限验证和个性化身份等多种用途。coockie内的有关信息是通过HTTP文件头来在web服务器和浏览器之间进行交流的。因此保持coockie尽可能的小以减少用户的响应时间十分重要。
有关更多信息可以查看Tenni Theurer和Patty Chi的文章“When the Cookie Crumbles”。这们研究中主要包括:
28、对于页面内容使用无coockie域名
当浏览器在请求中同时请求一张静态的图片和发送coockie时,服务器对于这些coockie不会做任何地使用。因此他们只是因为某些负面因素而创建的 网络传输。所有你应该确定对于静态内容的请求是无coockie的请求。创建一个子域名并用他来存放所有静态内容。
如果你的域名是www.example.org,你可以在static.example.org上存在静态内容。但是,如果你不是在 www.example.org上而是在顶级域名example.org设置了coockie,那么所有对于static.example.org的请求 都包含coockie。在这种情况下,你可以再重新购买一个新的域名来存在静态内容,并且要保持这个域名是无coockie的。Yahoo!使用的是 ymig.com,YouTube使用的是ytimg.com,Amazon使用的是images-anazon.com等等。
使用无coockie域名存在静态内容的另外一个好处就是一些代理(服务器)可能会拒绝对coockie的内容请求进行缓存。一个相关的建议就是,如果你 想确定应该使用example.org还是www.example.org作为你的一主页,你要考虑到coockie带来的影响。忽略掉www会使你除了 把coockie设置到*.example.org(*是泛域名解析,代表了所有子域名译者dudo注)外没有其它选择,因此出于性能方面的考虑最好是使用带有www的子域名并且在它上面设置coockie。
29、优化图像
设计人员完成对页面的设计之后,不要急于将它们上传到web服务器,这里还需要做几件事:
31、不要在HTML中缩放图像
不要为了在HTML中设置长宽而使用比实际需要大的图片。如果你需要:
<img width="100" height="100" src="mycat.jpg" alt="My Cat" />
那么你的图片(mycat.jpg)就应该是100x100像素而不是把一个500x500像素的图片缩小使用。
32、favicon.ico要小而且可缓存
favicon.ico是位于服务器根目录下的一个图片文件。它是必定存在的,因为即使你不关心它是否有用,浏览器也会对它发出请求,因此最好不要返回一 个404 Not Found的响应。由于是在同一台服务器上,它每被请求一次coockie就会被发送一次。这个图片文件还会影响下载顺序,例如在IE中当你在 onload中请求额外的文件时,favicon会在这些额外内容被加载前下载。
因此,为了减少favicon.ico带来的弊端,要做到:
Imagemagick可以帮你创建小巧的favicon。
33、保持单个内容小于25K
这条限制主要是因为iPhone不能缓存大于25K的文件。注意这里指的是解压缩后的大小。由于单纯gizp压缩可能达不要求,因此精简文件就显得十分重要。
查看更多信息,请参阅Wayne Shea和Tenni Theurer的文件“Performance Research, Part 5: iPhone Cacheability - Making it Stick”。
34、打包组件成复合文本
把页面内容打包成复合文本就如同带有多附件的Email,它能够使你在一个HTTP请求中取得多个组件(切记:HTTP请求是很奢侈的)。当你使用这条规则时,首先要确定用户代理是否支持(iPhone就不支持)。
Submitted by gouki on 2008, November 18, 5:52 PM
转载自中文网站管理员博客
跟网络管理员沟通时经常会出现这种情形,一些广为传播的理念可能在过去是正确的,但是可能已不再切合目前的情况了。当我们最近在跟几个朋友谈及关于网址的结构时就碰到这种情况。其中一个朋友很担心动态网址的使用,甚至认为“搜索引擎无法处理动态网址”。另外一个朋友觉得动态网址对搜索引擎来说完全不是问 题,那些都是过去的事了。还有一个甚至说他从来都搞不懂动态网址和静态网址相比有什么区别。对于我们来说,这一刻使我们决定要好好研究一下动态网址和静态 网址这个话题。首先,让我们来界定一下我们要谈论的主题:
什么是静态网址?
一个静态网址,顾名思义,就是一个不会发生变化的网址,它通常不包含任何网址参数。例如:http://www.example.com/archive/january.htm。您可以在搜索框里输入 filetype:html 在谷歌上搜索静态网址。更新此种类型网址的页面会比较耗费时间,尤其是当信息量增长很快时,因为每一个单独的页面都必须更改编译代码。这也是为什么网站管理员们在处理大型的、经常更新的网站,像在线购物网站、论坛社区、博客或者是内容管理系统时,会使用动态网址的原因。
什么是动态网址?
如果一个网站的内容存储于一个数据库,并且根据要求来显示页面,这时就可以使用动态网址。在这种情况下,网站提供的内容基本上是基于模板形式的。通常情况下,一个动态网址看起来像这样:http://code.google.com/p/google-checkout-php-sample-code/issues/detail?id=31。 您可以通过寻找像? = & 这样的符号识别出动态网址。动态网址有一个缺陷是不同的网址可以拥有相同的内容。这样导致不同的用户可能链向含有不同参数的网址,但是这些网址却都含有相 同的内容。这也是为什么网络管理员有时候想要将这些动态网址重写成静态网址的原因之一。
我是不是应该让我的动态网址看起来是静态的呢?
在处理动态网址时,希望您能了解以下几点事实:
静态和动态网址,Googlebot对于哪一个识别得更好呢?
我 们碰到过很多网站管理员,像我们的朋友那样,认为静态或者看起来是静态的网址对于网站的索引和排名是有优势的。这种看法是基于这样一个假设,即认为搜索引 擎在抓取和分析含有会话标识(session ID)和来源追踪器(source tracker)的网址时是有问题的。然而,事实是,谷歌在这两个方面都有了相当的进展。就点击率来说,静态网址可能略微有些优势,因为用户可以很容易地 读懂这个网址。但是,就索引和排名来说,使用数据库驱动网站并不意味着明显的劣势。相比较将参数隐藏以使他们看起来是静态的网址来说,我们更希望网站将动 态的网址直接提供给搜索引擎。
现在,让我们来看一些有关动态网址的广为传播的看法,并且来纠正一些蒙蔽网站管理员的假说。:)
传说:“动态网址不能被抓取。”
事实:我们可以抓取动态网址并且解释不同的参数。如果您为了让网址看起来像是静态的,而隐藏那些可以给谷歌提供有价值信息的参数,这样做反而会给该网址的抓取和排名带来麻烦。我们的建议是:请不要将一个动态网址改换格式以使其看起来是静态的。尽可能地使用静态网址来显示静态内容是可取的,但在您决定展示动态内容的情况下,请不要将参数隐藏起来从而使他们看起来像是静态的,因为这样做会删除掉那些有助于我们分析网址的有用信息。
传说:“动态网址的参数要少于3个。”
事实:对于参数的数量是没有限制的。但是,一个好的经验是不要让您的网址太长(这 个适用于所有的网址,不论是静态的还是动态的)。您可以去掉一些对于Googlebot来说不重要的参数,给用户一个好看一点的动态网址。如果您不能确定 可以去掉哪些参数,我们建议您将动态网址中所有的参数都提供给我们,我们的系统会弄明白哪一些是不重要的。将参数隐藏起来会影响我们正确地分析您的网址, 我们也就不能识别这些参数,一些重要信息可能也因此丢失了。
下面一些是我们认为您可能会存在疑问的一些问题。
这是否意味着我应该完全避免重写动态网址?
这 是我们的建议,除非您能确保您只是去掉多余的参数,或能够把所有有可能有不良影响的参数完整地删除。如果您把自己的动态网址任意修改使其看起来像是静态 的,您要清楚这样做是有风险的,有可能会导致有些信息不能被正常地编译和识别。如果您想给您的网站再增加一个静态的版本,请您一定要提供一个真正意义上的 静态的内容,比如生成那些可以通过网站相应路径而获取的文件。如果您仅仅是修改了动态网址的表现形式,而没有真正提供静态的内容,那么您有可能适得其反。 请直接把标准的动态URL提供给我们,我们会自动找出那些冗余的参数。
你能给我举一个例子么?
如 果您有一个像下面这样标准格式的动态网址:foo?key1=value&key2=value2,我们建议您不用改动它,谷歌会决定哪些参数可 以去掉;或者您可以为用户去掉那些不必要的参数。不过要慎重,仅仅去掉那些不重要的参数。这里有一个含有多个参数的动态网址的例子:
www.example.com/article/bin/answer.foo?language=en&answer=3&sid=98971298178906&query=URL
并不是所有的参数都提供额外的信息。所以将这个网址重写为www.example.com/article/bin/answer.foo?language=en&answer=3 可能不会引起任何问题,因为所有不相关的参数都去掉了。
下面是一些经过认为修改而看起来像是静态网址的例子。相比较没有重写、直接提供动态网址来说,这些网址可能会引起更多抓取方面的问题。
如 果您将动态网址重写成如上所述的示例的话,可能会导致我们很多不必要的抓取,因为这些网址中都含有会话标识(sid)和查询(query)参数的可变值, 这无形中生成了很多看起来不同的URL,而他们包含的内容却是相同的。这些格式让我们很难理解通过这个网址返回的实际内容和参数URL以及 98971298178906是无关的。不过,下面这个重写的例子却将所有无关的参数都去掉了:
尽 管我们可以正确地处理这个网址,我们还是不鼓励您使用这样的重写。因为它很难维护,而且一旦一个新的参数被加到原始的动态网址,那么这个网址就需要马上更 新。不这样做的话就会再次导致生成一个隐藏了参数的貌似静态网址的URL。所以最好的解决方法是通常将动态网址保持他们原来的样子。或者,如果您去掉不相 关的参数,请记住一定要保持这个网址是动态的:
本文来自:http://adsense.googlechinablog.com/2008/11/blog-post_18.html
Submitted by gouki on 2008, November 16, 8:48 PM
经过一个多月的开发,最新版本的Ubuntu Tweak正式发布了。 Ubuntu Tweak 0.4.2修正并改善了许多方面,并引入了“源编辑器”这个新特性。 —- 为了方便用户更方法的编辑和设定源,Ubuntu Tweak 0.4.2版加入了“源编辑器”。 什么是“源编辑器”呢?我来通过下面几张图片来展示它的相关功能。
基本功能:方便编辑源
首先,“源编辑器”提供一个巨大的文本框来让用户方便地编辑源。
只要点击“应用程序”->“源编辑器”,并解锁后,就可以马上可以开始自由地编辑源了。这个编辑区域支持语法高亮,使源更容易辨认。
通过这个,用户不再需要打开终端,执行:sudo gedit /etc/apt/sources.list等命令。
编辑完毕,保存后,可以点击“刷新”立即更新系统。

更新为预设的源
首次安装,或重装了Ubuntu后第一件事情就是要更改源。
现在通过Ubuntu Tweak来简单地完成这些吧!点击“更新源”,Ubuntu Tweak将会从网上更新下来一些常用、好用的源,根据自己的网络环境,确定并保存以后,就可以完成源的更改并马上更新系统了。
没有打开浏览器查询,没有打开终端的过程,没有复制和粘贴,一切用Ubuntu Tweak为你搞定!

上传新鲜的源
如果有更好的源了,但是服务器上没有收录,你就可以尝试将其上传。首先保证你使用了该用,然后点击“提交源”,简单地填上标题和相关注释,就可以上传了。
当然上传后的结果将经过审核才会开放出给他人使用,如果你有什么好的源而且默认的列表没有收录的话,赶快提交并与大家一块分享吧!

增加第三方源
这个版本继续完善了第三方源,加入了OpenOffice 3.0、Amarok等第三方源。其中还为特别为中文用户加入了Ubuntu中文源。
中文用户只要启用这个源,就可以立马享受到免费的永中Office2009,Ubuntu Tweak和好用的iBus输入法等好东西!

确保启用了中文源,你就可以在“添加/删除”中方便地安装“永中Office 2009 个人版”和iBus输入了!

除了以上新鲜玩意,Ubuntu Tweak 0.4.2还改善并修正了一些Bug,并重新制定了压缩包依赖,这样使用8.04以前的Ubuntu用户也能再次使用Ubuntu Tweak了。
还等什么,下载或从源里更新吧!
源代码:
ubuntu-tweak_0.4.2.orig.tar.gz
Deb包:
ubuntu-tweak_0.4.2-1~intrepid1_all.deb
消息来源:Linux桌面中文网
| « 2008年11月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | ||||||
[668] [0] [9] [227] [0] [92] [307] [65] [5] [286] [0] [236] [9] [27] [14] [982] [161]