Submitted by gouki on 2009, March 29, 8:12 PM
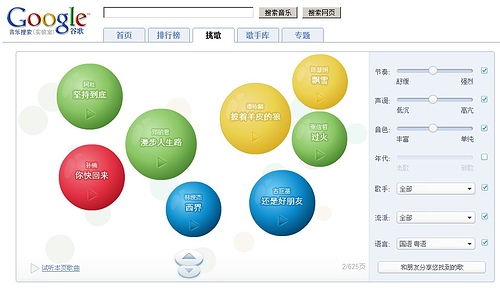
在google reader里闲逛的时候,看到了这个介绍,看界面,如果加上连线的话,就有点象微软那个“人立方”网站了。去了谷歌的网站,并尝试着根据上面的条件搜索了一下,发觉使用起来还是很方便的.
点击试听后会去一个top100.cn的网站,同样是采用了flash,估计是为了播放器可以兼容任何浏览器吧?还可以下载,只是不知道这些歌的版权如何处理(搞得象自己是FQ一样,装的很清高的样子,哈哈),下载的时候,提示来源是:file1.top100.cn,所以,黑黑。。。。
以下内容来自作者的介绍:http://www.awflasher.com/
我有幸在这个项目中扮演了主力ActionScript开发者和部分交互设计师的角色。
这个项目的交互创意、UI设计主要来自于Eicostudio(2004 年我大三的时候曾经膜拜过工作室创始人之一Rokey大牛的作品,他们都是国内最专业的UI设计师)和Google中国的UX团队。Google中国的 UX团队给予了我极大的帮助,在同Google UX团队的合作中,我能非常清楚地感受到他们每一个人对细节的执着追求和对中文搜索事业的敬业精神,每一个颜色,每一个字体样式,每一个UI组件的使用模 式和位置,都经过反复的斟酌才最终敲定。
同时,项目质量控制上面也要感谢J、M、B、T等谷歌Music团队的工程师的帮助。老实说,我从来没有在一个ActionScript项目中被内存回收折磨得不得不重写一个几千行的类 - 感谢诸位工程师的支持和建议。
具体如何使用我觉得就没必要具体介绍了吧,根据右侧的几个筛选条件进行选择,可以找到你想要的一种特定类型的音乐,十分方便,大家使用起来有什么意见和建议也欢迎在我的Blog留言。
本文来自:http://www.awflasher.com/blog/archives/1738
Tags: 谷歌, 挑歌
Misc | 评论:0
| 阅读:20107
Submitted by gouki on 2009, March 28, 10:17 AM
以下内容来自于淘宝QA的博客,看到的时候自己也很惊讶,感悟于以前的同事,在发现BUG的时候是多么的冷静自若(非并QA,而是某些开发人员),就差再对比一下淘宝的QA,发现差距是多大。
企业越大,就越是会遇到一些问题,当企业还在扩张和发展的时候,部分会员对一些BUG还能够容忍,但是当企业发展到一定规模的时候,会员对于自身所应该拥有的权利就会提到台面上来了。毕竟我花了钱,当然应该享受一些权利,而并不是一直在尽义务。如何能更好的为用户服务才是以后互联网公司要走的路啊。
当然下面的内容我也不知道是否是事实,但我还是很感动。
内容如下:
http://rdc.taobao.com/blog/qa/?p=1187
- 一次系统刚上线,一个卖家旺旺迅速反馈:部分宝贝图片显示不出来了,是不是系统升级的原因?
-
- 我们的开发和测试人员在忙碌的搜集问题,找问题,解决问题…
-
- 这位会员很着急说:310*310的不能显示….不对,是ps处理过的不能显示……
-
- 过了一会,又说道:我们一天更新几百张图片的,今天的工作计划泡汤了…
-
- 听到会员这么说,我感觉很难过,一个bug影响了一个卖家一天的工作…
-
-
-
- 我开始思索,平时自己工作过程中,如果电脑出了什么问题,自己也会急的像热锅的蚂蚁的.我想这位会员的感觉也是一样的.
-
- 当我们的系统越做越大,复杂度越来越高,对我们的要求也越来越高.我们应该跟会员一样,把系统看作我们赖以生存的工具,不能一次又一次把这种伤痛留给会员.
-
- 期待哪一天,我们系统升级后,会员只有快乐,没有阵痛……我们还需要继续做出很大的努力~~~
Tags: 淘宝, qa, 感悟
Misc | 评论:0
| 阅读:21496
Submitted by gouki on 2009, March 27, 3:06 PM
本内容来自群聊天记录,开花石头吐出来的。。。
取字段注释
SQL代码
- SELECT COLUMN_NAME 列名, DATA_TYPE 字段类型, COLUMN_COMMENT 字段注释
- FROM INFORMATION_SCHEMA.COLUMNS
- WHERE table_name = 'companies'##表名
- AND table_schema = 'testhuicard'##数据库名
- AND column_name LIKE 'c_name'##字段名
-
- SELECT table_name 表名,TABLE_COMMENT 表注释 FROM INFORMATION_SCHEMA.TABLES WHERE table_schema = 'testhuicard' ##数据库名
-
- AND table_name LIKE 'companies'##表名
参考http://dev.mysql.com/doc/refman/5.1/zh/ 今天找到了取mysql表和字段注释的语句
Tags: mysql, 字段注释
Baby | 评论:1
| 阅读:24153
Submitted by gouki on 2009, March 27, 3:04 PM
下午上班,收到一条短信,一看,哇,189发来的,天翼用户啊。
激动不己的打开短信,发现内容为:上海XXXX大酒店现诚聘男女公关,需体健貌端思想开放,18至48岁,月薪三万,当天结算,咨询XXXXX李经理。
第一个XXXX是酒店名称,第二个XXXX是联系电话
一下子心情都没有了。唉。原来189的优惠已经被沦为干这种活的工具了。
突然间对189失去了热情。
Tags: 天翼, 189
Misc | 评论:2
| 阅读:20098
Submitted by gouki on 2009, March 26, 9:43 AM
phpED算是老牌PHPIDE了,几年前用过,这几天重拾起来又是一翻风味。
几年前,PHPED最大的垢病就是不支持中文,每次删中文时,都是不见了一半字符,从那时候起我就基本放弃了。
这两天又有人推荐他,于是我重新下载进行安装。说一下简单的用后感吧。
界面啥的也就不提了,反正几乎所有的IDE都那样,有点不同的是PHPED多了一点HTML控件的快速插入,屏幕右侧的快捷工具栏中有一些比较常用的DB连接、SSH连接、MANUAL手册等,这些还是相对比较方便的。
编辑代码时,如果是PHP和HTML混编,两种代码的颜色还是很分明的。
DEBUG的时候还是需要使用它的dbg listener,并且需要在服务器上使用它自己的dbg的组件,并加入PHP.ini,才可以进行调试。
启动速度的话,不能算快,但是ZS比起来,速度还是有明显优势的。
自动提示功能的响应速度可以忍受,对中文的支持没有什么大的问题。
自动模版完成,是按ctrl+J,定义模版变量有点郁闷,因为他的编辑PHP4和PHP5分别用了不同的模版,如果你起初没有选定为PHP5,他就会默认调用PHP4的模版
缺点当然也有:
1、自动提示(自动完成)有时候会突然出不来,必须再重新刷新一下workspace就出来了。妖
2、注释代码没有快捷键,当然可以自定义,但ctrl+/却无法定义,很多IDE里都是使用它为注释的快捷键,上手一下子不习惯了。最后我定义成CTRL+M,但,不习惯
3、所有国外IDE的通病,部分快捷键与切换中文输入有冲突
4、对于project的管理不如其他IDE
5、我个人最不舒服的是,对于使用了rewrite功能做dispatch的框架,无法进行调试,例如ZF,或许是我不会调试吧?
其他情况下的应用基本没什么大问题。函数定义的跳转还是比较准确的,选中函数按F1可以跳到函数说明(手册好象有点老)
图片附件:

Tags: php, ide
Software | 评论:0
| 阅读:29916