Submitted by gouki on 2009, October 31, 8:40 PM
由于自己也遇到过类似问题,所以,看到这篇文章的时候 就更为观注,其实文章也没写什么,只是把自己的遇到的问题列了一下,但,能够引起共鸣的就是好文章 。
先贴原文,然后再把我的事情说一下:
项目已经进入数据割接测试一轮尾声,记得刚刚进入数据割接测试的阶段,大家都很茫然,让我们想起了当时数据准备阶段,这一幕又重现了,数据准备是因为数据 及其复杂,业务复杂,大家对其他人负责的业务不熟悉,导致数据准备成为一块绊脚石,然而开发人员都很忙,没有时间一起配合准备。而数据割接测试也同样面临 着类似问题,一方面业务及其复杂,新老系统的设计逻辑和数据结构有很大的差异。而我们大部分人对老系统不熟悉,参与割接的开发人员对新系统不熟悉,导致割 接测试困难重重。
刚开始我们采用的是把老系统线上的数据割接到新系统,然后我们选择几种典型业务按一定条件准备了一些用户,在新老系统中对比这些用户的数据。发现这这些用 户的记录不熟悉,用户的数据又比较乱,不是登录不了,就是密码不对,要不就是没有用户信息,要不就是不能发布宝贝,还要去修改相应的用户信息等等,这样准 备数据一天都快过去了进度很慢。后来大家提出用自己平时用的用户计划好场景,到日常中去构造一些数据,造好后再把这些用户给割接的人,让他们把相应的用户 数据增量割接过来。然后再用这些用户在新系统中做交易,看数据是否正确。另外备用一两个用户,在新系统中做同样的数据,进行比较。有些没办法构造的场景才 选用哪些已有的用户数据去查看。即自己构造的数据和上线上的数据互相弥补
这样做有几点好处:
首先自己构造的数据自己清楚,不用再去找这些用户数据。
其次自己平时用的用户,用户信息都是全的,能登录,能发宝贝,能做交易,能订购,不用再去修修补补,那怕是要修改,修改的地方也少点。
虽然这样一来有点进展,但是还是遇到了很大的麻烦,有很多数据割接过来完全错误,因为新老系统的数据结构很大的差异的问题,很多逻辑不对。而项目中的开发 忙于项目,完全不重视数据割接,后来我们建议新老系统开发人员和测试人员一起配合测试数据割接测试,保证数据的正确性。
针对以上出现的问题,个人觉得首先要保证迁移脚本的正确性,那最好是新老系统的开发人员配合编写脚本。万一项目中开发人员没时间,审核的时候要新老系统的开发人员要一起慎重审核脚本的逻辑。否则不能保证脚本的正确性,那更谈不上保证数据的正确性。
----以上为转贴,来源于:http://rdc.taobao.com/blog/qa/?p=4515
以前在XX公司的时候也遇到过,或者说,任何一个公司在新旧系统更换的时候,估计都会遇到吧?一般在这种情况下,最重要的是保留用户数据,毕竟如果没有用户,那网站也就没有存在的必要了。其次就是用户相关的数据,比如资料信息、历史、或者各种各样的操作。或许你会认为没有什么必要,但有的用户就喜欢翻旧事。前段时间在某群内看到有人把01、02年的贴子翻出来炫耀,以证明自己在某网站的年代长远。所以说,用户是奇怪的。
如果是电子商务的话,还得保证以前的订单和订单相关资料需要完全正确,否则,对谁来说都是一个损失。就象文章最后一段话,其实很多时候都是开发新系统的人在写迁移脚本,而这些人对于老系统并不熟悉,到最后,数据其实是模凌两可的,看上去正常就是皆大欢喜的事情了。其实也不是原始开发人员不做这些事,要知道,IT公司,跳槽情况非常常见,原始开发人员说不定几年前就跳槽了,越是老的公司,在初期的代码就越乱,越往后越感觉无法整合。迷惘中的新开发人员也只能跟着感觉走了。
HOHO
Misc | 评论:0
| 阅读:20262
Submitted by gouki on 2009, October 31, 8:31 PM
一些小的琐碎。
烧掉的电源线今天拿到了,虽然晚了点,但还是拿到了。毕竟别人也是要上班的,不可能由着我们的时间来
小朋友昨天摔了一跤,嘴唇破了点皮,直到今天还是红红的。
小朋友不肯在这边睡觉,非要到外婆家去,哭着累了才睡着。可怜啊。。。。
老婆的同事邀请她去家里玩,欣欣然去,不知道晚上什么样子回来。HOHO
vampire终于回去了,是上海不适应他还是他不适应上海?又或者其实本来就很勉强?不过,人活着开心就好,无论在任何地方都应该这样。
明天就是11月了,下个月有两人结婚,其一为老婆同事,其二为我的哥们。回家是肯定要回家的喽。
最后,发现自己写代码的速度和效率越来越低下了。怎么回事呢?唉。。。
Tags: ibm
Misc | 评论:1
| 阅读:19538
Submitted by gouki on 2009, October 30, 11:46 AM
爱别摸终于咔嚓了。还好,不是电脑,是电源
先是前两天说电池需要召回,去了维修点,他说俺的电脑不属保修范围之内,郁闷,然后我告诉他,我通过软件检查下来是属于召回范围的呀。
他很潇洒说,我这块电池不是在国内经销的机器上的,所以不予保修和召回。我说我在淘宝上买的,他说,那你有保修卡没?一下子傻掉了。。。
看来,以后在淘宝买所谓的行货一定要备保修卡。否则,和买水货没区别啊
以上是一,第二呢,是我的电源线。
可怜的电源线,终于又坏了,为什么要说又呢?那是因为在今年3月份左右,电源线烧了一次,如今刚过半年又烧了。每半年一次啊。
可能是因为我电源线经常折叠弯曲导致的吧,但是,笔记本电源线总要是折叠弯曲的吧,如果这样都不行,那还叫个毛笔记本啊。
等候换线+电源
附件: x1pur2oslo3xwjeyhispau7c9tkbqn3atajux0-oor4qsj4al_2jz-ijnzo46t95o7tve8iwswrtrmtav_d7hxv61cxjuuz0ix75 (8.42 K, 下载次数:1667)
Tags: ibm
Misc | 评论:0
| 阅读:20045
Submitted by gouki on 2009, October 29, 10:43 AM
Nio在http://www.nioxiao.com/archives/949里说到,php的CURL库生成cookie文件时,应当及时清除,否则会发生意料不到的事情
对于php的curl,我想,在我的博客上有一篇介绍校内狗狗的文章,是yhustc写的。他就用到了这个cookie文件。主要是phpcurl在访问时,会把当前的cookie全部写到这个文件里。如果是个人使用,当然是没问题。如果要提供服务给别人,估计就会发现cookie文件不停的写,而且内容都不一样【估计这就是nio遇到的问题吧】
bopo则改进了yhustc的http类,他用的是tmpnam函数,生成一个唯一的,不同的文件。只要在进程内。文件都不会变啦。呵呵
我当初是判断用户登录,每个用户分配一个cookie文件,保证不会和其他人产生冲突。。。HOHO
但看看Nio说的最后一句话,又不太像,他说:
http://www.nioxiao.com/archives/949
- 特别需要注意的是,在完成抓取之后,需要把 cookie 文件删除,否则下次抓取时会自动使用原有的 cookie 数据,从而导致一些预想不到的错误(我们今天就被这个问题折腾了很久 :( )。
但,好象每次访问都会生成新的cookie内容的吧?除非确实需要清空?这个问题,我是没有遇到过,暂时先记录一下。。
PHP | 评论:1
| 阅读:27699
Submitted by gouki on 2009, October 28, 11:38 AM
有些东西是我们在做网页的时候需要注意的,虽然,不太常用到,但稍注意一下,可能会减轻服务器很多压力 ,以下就是一篇小技巧的文章,了解了这些知识,会给你的WEB网站减轻一些IO的消耗吧。
内容如下:
网页的缓存是由HTTP消息头中的“Cache-control”来控制的,常见的取值有private、no-cache、max-age、must-revalidate等,默认为private。其作用根据不同的重新浏览方式分为以下几种情况:
(1) 打开新窗口
如果指定cache-control的值为private、no-cache、must-revalidate,那么打开新窗口访问时都会重新访问服务器。而如果指定了max-age值,那么在此值内的时间里就不会重新访问服务器,例如:
Cache-control: max-age=5
表示当访问此网页后的5秒内再次访问不会去服务器
(2) 在地址栏回车
如果值为private或must-revalidate(和网上说的不一样),则只有第一次访问时会访问服务器,以后就不再访问。如果值为no-cache,那么每次都会访问。如果值为max-age,则在过期之前不会重复访问。
(3) 按后退按扭
如果值为private、must-revalidate、max-age,则不会重访问,而如果为no-cache,则每次都重复访问
(4) 按刷新按扭
无论为何值,都会重复访问
当指定Cache-control值为“no-cache”时,访问此页面不会在Internet临时文章夹留下页面备份。
另外,通过指定“Expires”值也会影响到缓存。例如,指定Expires值为一个早已过去的时间,那么访问此网时若重复在地址栏按回车,那么每次都会重复访问:
Expires: Fri, 31 Dec 1999 16:00:00 GMT
在ASP中,可以通过Response对象的Expires、ExpiresAbsolute属性控制Expires值;通过Response对象的CacheControl属性控制Cache-control的值,例如:
Response.ExpiresAbsolute = #2000-1-1# ' 指定绝对的过期时间,这个时间用的是服务器当地时间,会被自动转换为GMT时间
Response.Expires = 20 ' 指定相对的过期时间,以分钟为单位,表示从当前时间起过多少分钟过期。
Response.CacheControl = "no-cache"
Expires值是可以通过在Internet临时文件夹中查看临时文件的属性看到的,如:
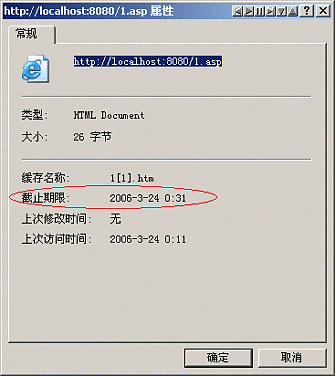
- 出处:http://kaima.cnblogs.com
- 作者:kai.ma
Javascript | 评论:0
| 阅读:21625


