在看电视,滚石30年。
听滚石的歌很久很久了,想起以前看到一个节目说滚石的由来时,创始人说,我们希望滚石就象一个滚动的石头,永远不会停下来。
然后在林海的采访周华健的时候,他说在滚石25年了,现在的人恐怕想不出,在一家公司25年是什么样的概念
听着电视里在放他们的节目,每首歌都是那样耳熟能详。
看了一下网络,原来居然就是今天,怪不得电视上写的是直播两个字。我晶啊,听说5个小时。
穷人,搜了一下google,居然最便宜的票已经到380了。这是开场后的价格,开场前最便宜是580。
老婆一直在怪我,为什么明知道有这个演唱会,居然不和她说,怎么着都得去买票啊。纠结啊
---
说一句以前的故事,当时战友超喜欢听罗大佑,然后00年罗大佑开演唱会,他没去看,但后来隔几新闻周刊上的图片新闻里,发现罗大佑的歌迷都是大叔级的。。
现在,自己也变成大叔了,却仍然是怀念着老歌,每次去KTV,都是游离在点歌台外的人,点的都是老歌,和同事们有代沟了。。。。。

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
浏览模式: 标准 | 列表2026年07月的文章
滚石30年
Submitted by gouki on 2011, October 7, 9:49 PM
再见乔布斯
Submitted by gouki on 2011, October 6, 11:14 PM
今天所有的IT新闻都在说着一件事,那就是乔帮主走了。
苹果的股票当然是会下跌,竞争对手的股票会上涨,再加上昨天发布的又不是iphone5,因此对苹果的影响还是挺大的。
乔布斯在苹果的来来回回其实都算是一个传说,不谈别的就谈他的身体吧。都能够撑上10多年,这本身就已经是一个传说了。
记得好象有听说iphone是21世纪最伟大的发明之一。这主要是指iphone把智能手机带来了一个新的发展方向。想想原来的windowsCE的手机,新手拿到手根本不会用,而iphone则没有这种事情。说是最伟大的发明也不以为过。
传说中的:单反穷三代苹果毁一生,也是指苹果的产品更新换代快,但事实上大家都明白吧,每一次的更新都有新的感受,那些工业设计上的东西,普通人不懂那么多,但是用起来爽的感觉却是实实在在真的。
不知道乔帮主走后,是否还会继承现在的思路,天知道呢。我不是乔帮主的粉丝,我只是做为一个IT从业人员,来纪念一下乔帮主而已。
走好,乔布斯。
用官方的话来说:If you would like to share your thoughts, memories, and condolences, please email rememberingsteve@apple.com
如果你有想法,确实是可以投递邮件了。
乔帮主走的太突然了,但又不是那么突然,坚挺了这么久,也该累了
上VPS了,用的是virpus的服务
Submitted by gouki on 2011, October 5, 11:56 PM
上VPS了,本来准备用burst.net的服务的。但是没有优惠码,而myvirpus的VPS只要3刀一个月,一年也只有36刀,所以我就直接换这个服务了。
不过,好象有时候会PING不通,但还是将就着可以的。先将就着用了。准备短时间内利用广告费把这36刀赚回来。然后上burst的服务。
我相信应该是没有问题的啦 ,嗯,如果有兴趣,你也可以点击这个链接 来进行尝试。这样是会给我带来一点利润啦。
512M的内存其实还是可以用的了。不过,如果希望用的更好,好象还是burst会更稳定一点。
现在的这个服务,还是相对不太稳定的。但能将就着用用。
准备用来做垃圾站,把我的广告费先赚回来。HOHO
people mountain people sea
Submitted by gouki on 2011, October 2, 1:52 PM
本来昨天去车站买车票的,结果刚出四号线,就发现,外面是“people mountain people sea”,天啊,根本挤不进去,最近折腾了大约20分钟,发现能力有欠缺,所以我就直接回家,不买票了
今天买票的时候,速度那是刚刚的。到车站10分钟就买到票了。施施然回家。。。
本来带小朋友回家的,但是小朋友咳嗽的厉害,没办法了。怕转肺炎,只能先呆在上海,万一有什么事情,还能直接去医院。在乡下的话,去医院就没有这么方便了
刚才,群里还有人在叫嚣,加班加班,果然有点悲催,不过想想自己在国庆后可能也会有频繁的加班情况,一下子也就无法蛋定了。
这两天乘着在家里,把一些基础代码再准备准备,到时候可能会轻松一点。嗯,只能先这样想了
关于Basename取中文文件名
Submitted by gouki on 2011, September 30, 10:16 PM
之前在博客里有提过basename的事情,蜘蛛也说过这个函数处理中文有问题。我也在测试的过程中遇到过各种各样的问题,但总体来说,我现在在处理中文文件名的时候是直接 array_pop(explode("/",$filename));
今天在群里,echo也说了这个问题,他居然还贴了SVN中PHP的源码关于basename的一段,并指出问题在php_mblen 这个函数上:他说mblen发现全中文的时候会返回负数。
于是他说有个临时的解决方案是:
XML/HTML代码
- echo 22:00:11
- ltrim(basename(' ' . $filename))
- 骗过mblen() ,mblen全中文的时候,返回的是负数。
- 有一个空格就好 了
没有试过,希望能够解决问题。
然后日哥说,可以用exif_read来解决这个问题,可以取得图片的title,但echo直接无视,因为不是每个上传的文件都是图片,可以通过 Exif_read解决这个问题。
echo也说了,别妄想用pathinfo解决这个问题,因为源码里显示,这个函数最 后还是调用了php_basename,所以他们的问题其实是一样的。。。。
=------纯记录----
图片附件(缩略图):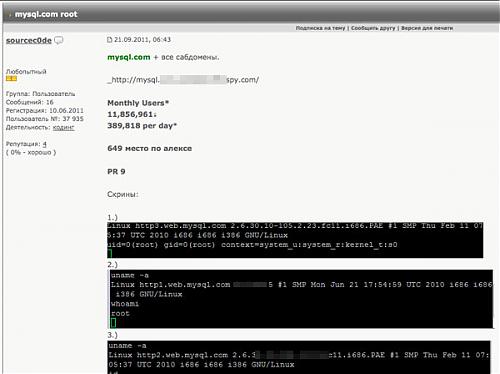
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [669]
- python [0]
- Go [9]
- Flutter [227]
- lua [0]
- Scala & Ruby [92]
- Javascript [307]
- PHP Framework [65]
- Linux [5]
- 苹果相关 [286]
- DataBase [0]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [982]
- Baby [161]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- It's going to be ending of...
07-05 - url - 好老的博客系统,当年用过。竟然还有人在用。
06-28 - im2828 - 你好,这个现在不能下载了,请重新提供一下吧
06-18 - 海东青 - 你这博客皮肤都20年了吧,该换了
05-27 - 月票的进哥 - 不用感觉,就是死了,停服公告都发出来了
05-27 - imlonghao
博客信息
- 分类数量: 17
- 文章数量: 3154
- 评论数量: 1911
- 标签数量: 2284
- 附件数量: 940
- 注册用户: 56
- 今日访问: 57846
- 总访问量: 76097571
- 程序版本: 1.6
