服务器同步,最简单的恐怕就是rsync了。如果是同一机房,如果是ubuntu,那就真的是灰常灰常简单啊。apt-get install rsync就over了。当然配置还是需要自己来的。
找的资料居然是百度百科的。好郁闷啊。不过。。。还是COPY一份了(话又说回来,现在百度百科在人肉整理+金钱攻势下,资料也真的是越来越完善了。只是不知道啥时候会把RFC也帮忙全部汉化一下吧。比如大家关心的tcp/ip,http协 议等,是不是也该整个汉化的版本之类的?【或许已经有了只是没有注意过罢了】)
原文:http://baike.baidu.com/view/1183189.htm
rsync是类unix系统下的数据镜像备份工具,从软件的命名上就可以看出来了——remote sync。它的特性如下:
- 可以镜像保存整个目录树和文件系统。
- 可以很容易做到保持原来文件的权限、时间、软硬链接等等。
- 无须特殊权限即可安装。
- 优化的流程,文件传输效率高。
- 可以使用rcp、ssh等方式来传输文件,当然也可以通过直接的socket连接。
- 支持匿名传输,以方便进行网站镜象。
软件下载
rysnc的主页地址为:http://rsync.samba.org/ ,目前最新版本为3.0.7。可以选择从原始网站下载:http://rsync.samba.org/ftp/rsync/。
安装
Ubuntu安装: sudo apt-get install rsync
RedHat: yum install rsync
编译安装
rsync的编译安装非常简单,只需要以下简单的几步:
[root@www rsync-2.4.6]# ./configure
[root@www rsync-2.4.6]# make
[root@www rsync-2.4.6]# make install
但是需要注意的是必须在服务器A和B上都安装rsync,其中A服务器上是以服务器模式运行rsync,而B上则以客户端方式运行rsync。这样在web服务器A上运行rsync守护进程,在B上定时运行客户程序来备份web服务器A上需要备份的内容。
rsyncd.conf
rsync服务器的配置文件是rsyncd.conf.
以下是一个rsyncd.conf的样本:
# Distributed under the terms ofthe GNU General Public License v2
# Minimal configuration file for rsyncdaemon
# See rsync(1) and rsyncd.conf(5) man pagesfor help
# This line is required by the/etc/init.d/rsyncd script
pid file = /var/run/rsyncd.pid
port = 873
uid = root
gid = root
use chroot = yes
read only = yes
max connections = 5
#This will give you a separate log file
#log file = /var/log/rsync.log
log format = %t %a %m %f %b
syslog facility = local3
timeout = 300
[test]
path = /home/nemo
list=yes
ignore errors
auth users = root, nemo
secrets file = /etc/rsyncd/rsyncd.secrets
comment = linuxsir home
exclude = tmp/
各个参数具体含义参见man rsyncd.conf
服务器端启动:
usr/bin/rsync --daemon --config=/etc/rsyncd/rsyncd.conf
可能需要root权限运行.
/etc/rsyncd/rsyncd.conf 是你刚才编辑的rsyncd.conf的位置.
也可以在/etc/rc.d/rc.local里加入让系统自动启动等.
客户端同步:
rsync -参数 用户名@同步服务器的IP::rsyncd.conf中那个方括号里的内容 本地存放路径 如:
rsync -avzP nemo@192.168.10.1::nemo /backup
说明:
-a 参数,相当于-rlptgoD,-r 是递归 -l 是链接文件,意思是拷贝链接文件;-p 表示保持文件原有权限;-t 保持文件原有时间;-g 保持文件原有用户组;-o 保持文件原有属主;-D 相当于块设备文件;
-z 传输时压缩;
-P 传输进度;
-v 传输时的进度等信息,和-P有点关系,自己试试。可以看文档;
- 扩展阅读:
- http://chenzhuo.blog.51cto.com/150592/269530 rsync配置实例
现在,windows下面也有rsync客户端了。。。
为了让移动设备也能用上jQuery,jQuery开发团队发布了jQuery移动设备版开发项目jQuery Mobile Project(http://jquerymobile.com)。jQuery Mobile不仅会给主流移动平台带来jQuery核心库,而且会发布一个完整统一的jQuery移动UI框架。
对于大名鼎鼎的jQuery开发团队来说,当然要让jQuery Mobile支持全球主流的移动平台,而不仅仅是北美流行的移动平台。想要知道jQuery Mobile项目将要做些什么吗?请看jQuery移动平台策略;想要知道jQuery Mobile项目将会支持哪些浏览器吗?请看Mobile Graded Browser Support。

jQuery Mobile开发团队正在紧张工作,准备那些要支持的移动设备并针对这些设备进行测试。他们争取在今年晚些时候发布jQuery Mobile。如果你想为jQuery Mobile提供帮助,请加入jQuery Mobile社区的讨论组。
jQuery Mobile项目已经得到了Palm, Mozilla等移动浏览器厂商的赞助。
jQuery Mobile开发团队说:“能开发这个项目,我们非常兴奋。移动Web太需要一个跨浏览器的框架,让开发人员开发出真正的移动Web网站。我们将尽全力去满足这样的需求。”
编者:移动互联网,挡不住的趋势...
英文原文:Announcing the jQuery Mobile Project
博客园编译
做网页开发的时候不可避免会用到JS,当然更不可避免的就会遇到JS错误。当你打开网页时,IE左下角的感叹号是不是让你很郁闷?怎么调试就成了必修课了。
一般来说,IE的出错信息还是能够基本定位到代码中,FF的相对定位的就更准确一些。只是有时候IE报错为0行或者N行(这个N超出了页面行数)时,就比较让人郁闷。而更头疼的是,如果这个代码在FF完全正常,那真是想死的心都有了。
IE下面,可能更多的时候还是利用微软自己提供的工具来进行查错:ms script debugger,只是知道的人很少,用的人更少。现在firebug lite已经登录IE平台(其实也不算是登录,只是加载firebug lite类库而已。不过,这已经能解决大部分问题了)。FF下面嘛,那就主推firebug,随着firebug的流行,一些附加的东西都有了,如firephp,firecookie,eventbug等插件也越来越让人离不开它。safari和chrome这些基于webkit的浏览器。也都有着自带的js调试工具,可用性我就不太清楚了。没用过,更多的时候只保证IE和FF正常就OK了。webkit虽然份额随着国内所谓双核浏览器的开发而增长的较快,但真正的使用者还仅限于那一小撮人群而已。
于是,这,又成了firebug等的天下(IE8已经自带调试工具,快捷键与firebug一样,界面差不多)。
不废话,下面是我转贴的文章,介绍了一些常见的调试方法,其实也不能算是调试,也可以说是代码的一些写法罢了。【略做整理】
A 使用alert() 和document.write() 方法监视变量值
如果要中断代码的运行,监视变量的值,则使用alert() 方法;
如果需要查看的值很多,则使用document.write() 方法,避免反复单击“确定”按钮;
B 使用window.onerror 事件
当页面出现异常时,onerror 事件会在window 对象上触发。它能在一定程度上告诉开发者相关的错误信息。
示例:
JavaScript代码
- <script type="text/javascript">
- function myerror(_message,_url,_line)
- {
- alert("错误信息:" + _message
- +"\n错误的URI:" + _url
- +"\n错误的行数:" + _line
- );
-
- return true;
- }
-
- window.onerror = myerror;
-
-
- window,onload = test;
- </script>
注意:在IE 中,触发error 事件后,正常的代码会继续运行,所有的变量和数据都会保存下来,在其onerror 事件处理方法中可以正常访问到;而在Firefox 中,触发error 事件后,一切都结束,所有的变量和数据都将被销毁。
C 使用 try...catch 语句找错误
示例:
JavaScript代码
- <script type="text/javascript">
- try
- {
- alert(触发异常);
- }
- catch (_ex)
- {
- var err = "错误信息";
- for (var i in _ex)
- {
- err += "\n参数名:" + i
- + "\t参数值:" + _ex[i];
- }
- alert(err);
- }
- finally
- {
- alert("finally 总是会运行");
- }
- </script>
注意:try...catch 并不能很好的处理JavaScript 的语法错误。
示例:
JavaScript代码
- <script type="text/javascript">
- try
- {
- alert("触发语法错误"));
- }
- catch (_ex)
- {
- var err = "错误信息";
- for (var i in _ex)
- {
- err += "\n参数名:" + i
- + "\t参数值:" + _ex[i];
- }
- alert(err);
- }
- </script>
该示例并没有进入catch 块中。
D 使用相关调试器
在IE 和Firefox 浏览器中,可以使用相关的调试器或插件对JavaScript 进行调试。
● 在Firefox 浏览器中,可以使用其自带的“错误控制台”。操作步骤如下:
打开Firefox 浏览器 → 在菜单条“工具”中 → 选择“错误控制台”即可。
在没有其他插件的情况下,其自带的“错误控制台”是一个非常不错的选择。
另外,在Firefox 浏览器中,还有一些很不错的调试器,如:Venkman、Firebug 等。
Venkman 调试器安装后,可以在Firefox 浏览器 → 在菜单条“工具”中 → 选择“JavaScript Debugger ”命令启用;
Firebug 调试器安装后,可以在Firefox 浏览器 → 在菜单条“工具”中 → 选择“Firebug”→ 选择“打开 Firebug”即可;
● 在IE 浏览器中,可以使用 Microsoft Script Debugger 调试器
Microsoft Script Debugger 是微软随IE 4 一同发布的一个IE插件,可以从微软的官方网站上免费下载。
下载安装以后,必须将IE 浏览器的调试选项打开才能使用。操作步骤如下:
1> 打开IE 浏览器 → 选择菜单栏的“工具”→ “Internet 选项”命令 → “高级”选项卡 → 将“禁用脚本调试(Internet Explorer )”复选框中的勾去掉即可。
2> 当IE 浏览器正在浏览页面时,运行Microsoft Script Debugger 调试器工具即可进行调试。
在Microsoft Script Debugger 调试器的 Running Document 面板中选择开启的页面文件(只读),然后按F9 可以设置断点调试。另外,其Command Window 面板也是一个很有用的功能,它能在代码断点停止时,在其中输入变量名并回车,便可看到此时变量的值;Command Window 面板甚至可以接受简单的JavaScript 命令。但Microsoft Script Debugger 调试器自身还存在一个bug 问题。
原文出自:http://www.cnblogs.com/xugang/archive/2010/08/05/1793392.html
感谢同机柜内ARP攻击者的放手,使得我的网站可能、好象、大概正常了吧。
事实上我很郁闷,当我查出来中毒后,我告机了edong,结果他们给我的答复就是没有查到ARP攻击源,我很奇怪。
半年前,我的域名IP是另外一个,也是因为ARP攻击,导致网站经常打不开。开始以为硬件有问题,后来換到另一个内置网卡上,结果还是会断,网线也換了好几根,他们还说是我的机器有问题,让我重装系统,结果还是不正常。最后,然后怀疑是ARP。结果又是告知我没有ARP。于是申请換IP。
換了一个机柜后,一切正常,你说,是不是ARP呢?如今,这类事情又来了,你让我怎么办?今天我报上去,他又回复我:
XML/HTML代码
- 您好,目前监控都没有arp
- 请检查是否是您本地网络的问题。
不过,值得欣慰的是。。。刚才我上去回复后,他们终于说:
XML/HTML代码
- 您好,今天上午9点左右同机柜是有arp欺骗,我们马上就处理了
总算是完了一桩心事。
鸡肋者,食之无味,弃之可惜。
这是杨修被杀前说的话。
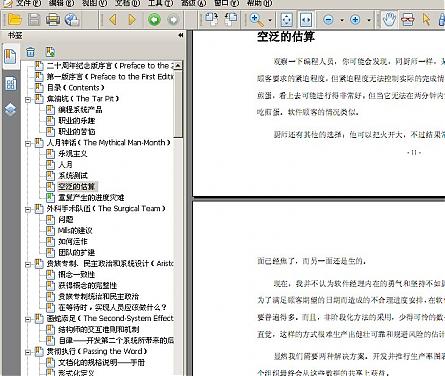
PDF查看插件是最新WPS里提供的,使用后,打开PDF,可以很完整的看到书签,然而,内容却全部变成了乱码。
在使用福昕打开后,一切正常。并没有乱码出现。
由此可见,这个PDF查看的插件,还不如没有。
但是,WPS导出PDF的功能还是不错的。至少我挺喜欢。首先不用担心别人再修改我的文档了:其次,如果按照规范做的文档,还能够按层次自动生成书签。
可惜了这个PDF查看插件。
怎么,不相信?有图为证
WPS截图:
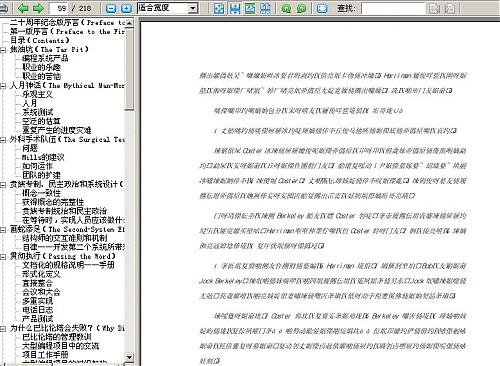
福昕截图: