HTTP/1.1 200 OK Date: Wed, 05 Nov 2003 10:46:04 GMT Server: Apache/1.3.28 (Unix) PHP/4.2.3 Content-Location: CSS2-REC.en.html Vary: negotiate,accept-language,accept-charset TCN: choice P3P: policyref=http://www.w3.org/2001/05/P3P/p3p.xml Cache-Control: max-age=21600 Expires: Wed, 05 Nov 2003 16:46:04 GMT Last-Modified: Tue, 12 May 1998 22:18:49 GMT ETag: "3558cac9;36f99e2b" Accept-Ranges: bytes Content-Length: 10734 Connection: close Content-Type: text/html; charset=utf-8 Content-Language: en
这是一个资料备份,常见的head头部

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
浏览模式: 标准 | 列表Tag:分词
备份资料:一般的header
Submitted by gouki on 2011, December 18, 11:24 PM
鸡肋一般的wps插件:PDF查看
Submitted by gouki on 2009, September 22, 4:52 PM
鸡肋者,食之无味,弃之可惜。
这是杨修被杀前说的话。
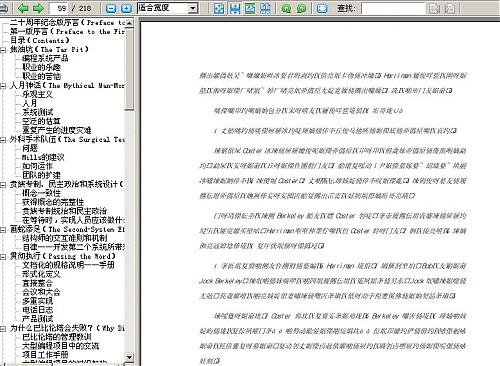
PDF查看插件是最新WPS里提供的,使用后,打开PDF,可以很完整的看到书签,然而,内容却全部变成了乱码。
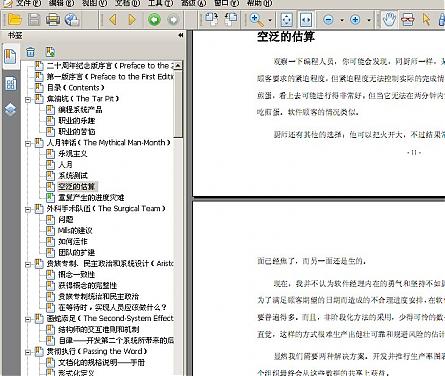
在使用福昕打开后,一切正常。并没有乱码出现。
由此可见,这个PDF查看的插件,还不如没有。
但是,WPS导出PDF的功能还是不错的。至少我挺喜欢。首先不用担心别人再修改我的文档了:其次,如果按照规范做的文档,还能够按层次自动生成书签。
可惜了这个PDF查看插件。
怎么,不相信?有图为证
WPS截图:
福昕截图:
google docs 分享害死人啊
Submitted by gouki on 2009, April 8, 10:08 AM
前段时间放了一篇张宴关于GOOGLE架构的文章,张宴文中引用了google docs分享的一个PDF,然后我就全文复制过来了。
结果N个人和我抱怨说IE打开就死了。
因为在看完文章后,我去GOOGLE docs进行一下试用,它会把pdf,ppt都会搞类类似于幻灯片的方式共享,而且引用方法是采用了iframe
当朋友们和我抱怨时,我就在猜测,是不是这个iframe导致的。
于是,把内容放到文章页后,正常了。oh yeah...
| « 2026年06月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
日志分类
- PHP [666]
- python [9]
- Go [38]
- Flutter [14]
- lua [2]
- Scala & Ruby [12]
- Javascript [307]
- PHP Framework [65]
- Linux [289]
- 苹果相关 [229]
- DataBase [161]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [981]
- Baby [92]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- 前几年 lnmp.org 被收购,搞了一波投毒之后,我对这种一键...
06-03 - imlonghao - 这是默认主题啊,怎么分享
10-18 - gouki - 请问这个主题可以分享一下么 谢谢
10-14 - NN - 大佬你好,在用dcat 遇到 怎么做无感刷新的问题,请问你有做过...
02-01 - uc5bbl8s - 好用!!
07-14 - 口水
博客信息
- 分类数量: 17
- 文章数量: 3152
- 评论数量: 1906
- 标签数量: 2283
- 附件数量: 941
- 注册用户: 56
- 今日访问: 27578
- 总访问量: 74182522
- 程序版本: 1.6
