Submitted by gouki on 2010, June 9, 5:33 PM
MSN提示我有一封新邮件的时候,还以为又是垃圾邮件。打开后才发现,原来是微软社区过来的邮件,告诉我hotmail又有了新的features。看了一下邮件,原来最主要的是在skydriver里面把web apps也整合了。就是传说中的在线office。
试用了一下,感觉还行,只是功能嘛。与传统相比可就差太多了。不过这也没办法,毕竟一个是WEB,一个是软件。word,就别想太多了。和那些所见所得编辑器差不多。没什么好讲的。PPT我不感兴趣,excel嘛,如果不试公式,我想也没有多少用的机会。因此onenote就是我的首要测试了。
在office里面,也就一个onenote是我感兴趣的软件,可惜不支持在线数据,因此有了这个功能后,我就相对关注了一下,做了点小测试。
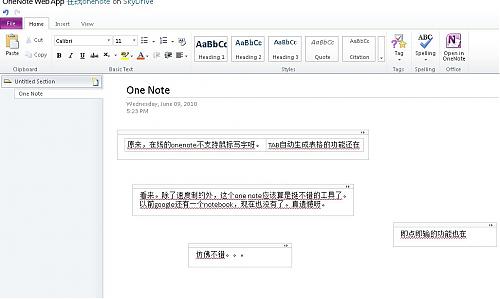
还算满意吧?毕竟是WEB版嘛,你哪能要求那么多。。。
正如我图中所说的,看来,致命的问题还是速度呀,在国内,没速度怎么行?目前onenote我已经在本地不使用了,改用wiz来管理我的一些知识库以及安排日常事项,小型软件也有小型软件的作用。
最希望的就是wiz能够开放FTP存储功能(可以直接使用第三方Ftp),这样就可以不受wiz限制了。数据啥的也会比较放心一点。现在的版本,不敢存私人数据。
Tags: microsoft, webapp, word, excel, onenote
Misc | 评论:1
| 阅读:23612
Submitted by gouki on 2010, June 9, 10:30 AM
手册中介绍PHP生成PDF用的是fpdf,网上也有一些代码其于Fpdf的看起来好象都不错,但是前提是有fpdf。。因此后来都放弃了。
这一个php class我没有试过,但是看上去好象不错,因为:1开源2原生PHP,不用组件(听说,没试过。)主要是看它可以直接把网页生成PDF,因为他支持html,xhtml,css。所以感觉不错
TCPDF is an Open Source PHP class for generating PDF documents.
TCPDF project was started in 2002 and now it is freely used all over the world by millions of people. TCPDF is a Free Libre Open Source Software (FLOSS).
官方的说明也很详细:
Main Features:
- no external libraries are required for the basic functions;(看来也只是针对基本功能,不过我想应该够了。)
- all ISO page formats, custom page formats, custom margins and units of measure;
- UTF-8 Unicode and Right-To-Left languages;
- TrueTypeUnicode, OpenTypeUnicode, TrueType, OpenType, Type1 and CID-0 fonts;
- Font subsetting;
- methods to publish some XHTML + CSS code, Javascript and Forms;
- images, graphic (geometric figures) and transformation methods;
- native support for JPEG, PNG and SVG images;
- 1D and 2D barcodes: CODE 39, ANSI MH10.8M-1983, USD-3, 3 of 9, CODE 93, USS-93, Standard 2 of 5, Interleaved 2 of 5, CODE 128 A/B/C, 2 and 5 Digits UPC-Based Extention, EAN 8, EAN 13, UPC-A, UPC-E, MSI, POSTNET, PLANET, RMS4CC (Royal Mail 4-state Customer Code), CBC (Customer Bar Code), KIX (Klant index - Customer index), Intelligent Mail Barcode, Onecode, USPS-B-3200, CODABAR, CODE 11, PHARMACODE, PHARMACODE TWO-TRACKS, QR-Code, PDF417;
- Grayscale, RGB, CMYK, Spot Colors and Transparencies;
- automatic page header and footer management;
- document encryption and digital signature certifications;
- transactions to UNDO commands;
- PDF annotations, including links, text and file attachments;
- text rendering modes (fill, stroke and clipping);
- multiple columns mode;
- bookmarks and table of content;
- text hyphenation;
- automatic page break, line break and text alignments including justification;
- automatic page numbering and page groups;
- move and delete pages;
- page compression.
这里也还有一些例子,有61个之多:
- Simple PDF with default Header and Footer: [PHP] [PDF]
- Simple PDF without Header and Footer: [PHP] [PDF]
- Custom Header and Footer: [PHP] [PDF]
- Cell stretching: [PHP] [PDF]
- Multicell: [PHP] [PDF]
- WriteHTML and RTL support: [PHP] [PDF]
- Independent columns with WriteHTMLCell: [PHP] [PDF]
- External UTF-8 text file: [PHP] [PDF]
- Image: [PHP] [PDF]
- Multiple columns: [PHP] [PDF]
- Colored Tables: [PHP] [PDF]
- Graphic Functions: [PHP] [PDF]
- Graphic Transformations: [PHP] [PDF]
- Javascript and Forms: [PHP] [PDF]
- Bookmarks (Table of Content): [PHP] [PDF]
- Document Encryption: [PHP] [PDF]
- Independent columns with MultiCell: [PHP] [PDF]
- Persian and Arabic language on RTL document: [PHP] [PDF]
- Non unicode / Alternative config file: [PHP] [PDF]
- Multicell complex alignment: [PHP] [PDF]
- writeHTML alignment: [PHP] [PDF]
- CMYK colors: [PHP] [PDF]
- Page Groups: [PHP] [PDF]
- Object Visibility: [PHP] [PDF]
- Object Transparency: [PHP] [PDF]
- Text Clipping: [PHP] [PDF]
- Barcodes: [PHP] [PDF]
- Multiple page formats: [PHP] [PDF]
- Set PDF viewer display preferences: [PHP] [PDF]
- Colour gradients: [PHP] [PDF]
- Pie Chart Graphic: [PHP] [PDF]
- EPS/AI vectorial image: [PHP] [PDF]
- Mixed font types (TrueType Unicode, core, CID-0): [PHP] [PDF]
- Clipping masks: [PHP] [PDF]
- Line styles with cells and multicells: [PHP] [PDF]
- Text Annotations: [PHP] [PDF]
- Spot Colors: [PHP] [PDF]
- NON-embedded CID-0 CJK font: [PHP] [PDF]
- HTML Justification: [PHP] [PDF]
- Booklet (double-sided pages): [PHP] [PDF]
- File attachment: [PHP] [PDF]
- Image with Alpha Channel Transparency: [PHP] [PDF]
- Disk caching: [PHP] [PDF]
- Move, Copy and delete page: [PHP] [PDF]
- Table Of Content with Bookmarks: [PHP] [PDF]
- Text hyphenation: [PHP] [PDF]
- Transactions and UNDO: [PHP] [PDF]
- Table header and rowspan: [PHP] [PDF]
- TCPDF methods in HTML: [PHP] [PDF]
- 2D Barcode (QR Code): [PHP] [PDF]
- Full page background: [PHP] [PDF]
- Digital Signature Certification: [PHP] [PDF]
- Javascript functions: [PHP] [PDF]
- XHTML Form: [PHP] [PDF]
- Font Dump: [PHP] [PDF]
- Crop Marks and Registration Marks: [PHP] [PDF]
- Cell vertical alignments: [PHP] [PDF]
- SVG Image: [PHP] [PDF]
- Table Of Content with HTML templates: [PHP] [PDF]
- Advanced page settings: [PHP] [PDF]
- XHTML + CSS: [PHP] [PDF]
可以尝试试用一下吧。
Tags: tcpdf, fpdf, pdf
PHP | 评论:0
| 阅读:22905
Submitted by gouki on 2010, June 8, 8:49 PM
晚上对博客模版进行了细微调整,把顶部的百度广告换成了google的图片广告。因为百度的广告,文字性的看上去很难看,不如google图片看起来漂亮。
对代码框的宽度进行了微调,原来的宽度是98%,现在是78%,这样,在文章内容右侧有图片的时候,代码框仍然可以显示在主体中,而不是象以前,因为文章内容右侧有图片,代码框又太宽,而导致大量的内容沉到下边去。
文章底部的百度广告和淘宝客全部去掉。同时把页面底部的阿里妈妈广告提到上面来。原来内容页广告太多了。影响美观。(虽然我正在用YII重新尝试,但适当的美化页面还是需要的)
至此,页面上就没有百度广告了,由于百度广告我已经有了80块钱,如果全部撤掉,就太可惜了。因此在左侧栏的tag上方,放置了百度广告。希望可以早日满100元就可以撤下来了。
其实还有部分的模版中嵌有广告,有些我都不记得了,也不想再重新折腾,随便吧。。。最近下载了fvzone的reborn模版。正在尝试用yii嵌套,因为他的代码里全是wp的函数,所以改起来有点累。。
Tags: 博客, 调整
Misc | 评论:1
| 阅读:20213
Submitted by gouki on 2010, June 8, 10:11 AM
前段时间我推荐了zen coding,并为此用上了notepad++,感觉在作网页的时候还行。而且,我的同事用dreamweaver的,也用上了它,感觉同样很爽。比如他输入:
XML/HTML代码
- div#page>(div#header>ul#nav>li*4>a)+(div#page>(h1>span)+p*2)+div#footer
生成如下页面:
XML/HTML代码
- <div id="page">
- <div id="header">
- <ul id="nav">
- <li><a href=""></a></li>
- <li><a href=""></a></li>
- <li><a href=""></a></li>
- <li><a href=""></a></li>
- </ul>
- </div>
- <div id="page">
- <h1><span></span></h1>
- <p></p>
- <p></p>
- </div>
- <div id="footer"></div>
- </div>
早上推荐给
小茗时,他说,Zen coding有for editplus的了。欣欣下载下来。运行后却发现,生成后的代码与官方不一样,看来还是有待改进啊,zen coding for editplus生成的代码是:
XML/HTML代码
- <div id="page"></div>
- <div id="header">
- <ul id="nav">
- <li>
- <a href=""></a><div id="page"></div>
- <h1>
- <span></span><p></p>
- <p></p>
- <div id="footer"></div>
- </h1>
- </li>
- <li>
- <a href=""></a><div id="page"></div>
- <h1>
- <span></span><p></p>
- <p></p>
- <div id="footer"></div>
- </h1>
- </li>
- <li>
- <a href=""></a><div id="page"></div>
- <h1>
- <span></span><p></p>
- <p></p>
- <div id="footer"></div>
- </h1>
- </li>
- <li>
- <a href=""></a><div id="page"></div>
- <h1>
- <span></span><p></p>
- <p></p>
- <div id="footer"></div>
- </h1>
- </li>
- </ul>
- </div>
这个与标准的偏 差实在是太大了。。。不过。在简单的情况下,还是可以使用的。将就着喽。总比没有的好。
下载地址为:http://www.vfresh.org/w3c/914
图片附件(缩略图):
Tags: zencoding, editplus, notepad++
PHP | 评论:0
| 阅读:24067
Submitted by gouki on 2010, June 7, 4:01 PM
为了测试phprpc_client for SAE,到小菜鸟的app网站上把他的API全部复制到SAE的空间里,做了一点测试。有不少功能呢。每个例子最后我都用highlight_file把当前文件全部打印出来。可以,写的时候就可以做参考了。
事实上也没有什么 好参考的,小菜鸟的网上有的是代码,还有演示,我这里只是仅仅作了COPY而己。
对于最后的页面显示时间,这个就涉及到网络关系了,和实际执行时间并没有太大的联系,纯粹一看。
很多例子都在:
小菜鸟的APP网站是:MYWS,对了。小菜鸟还做了一个Ecshop的皮肤,仿凡客,也不错,演示在:http://shop.17kaixin8.com/,如果觉得好,也可以向他购买哦。
Tags: phprpc, 17kaixin8, ecshop
PHP | 评论:3
| 阅读:22240


