Submitted by gouki on 2010, June 15, 8:43 AM
说实话,我不知道这是BUG还是新功能。【最后鉴定是浏览器的一个小BUG,不是typecho的BUG,但对于附件,我还是提出了我个人想法】
在0.8版本中,如果你选择新建一篇文章,同时选择添加一个附件。然后提交表单新增文章,重新打开后,你会发现文章并没有附件。打开数据库,发现文件已经上传,而且ID还在文件ID前面,只是parent_id就是0了。
然后再选择新建一篇文章,这个没有归档的附件就显示在新文章的附件列表里。不管是是否选择插入,反正这个附件已是属于这篇 新文章了。
在此,我猜测这应该算是一个BUG,程序开发人员考虑到了附件上传的不可靠性,所以选择了先上传图片,但是其实对于博客来说,文章应该是更重要的。所以,完全是可以等文章写完再上图片。而不是直接就把图片插入数据库,然后在更新的时候无法插入(wordpress对于未归档的图片,都可以通过插入媒体来进行重插入,而typecho没有插入媒体这个选项,因此,图片就处于永远无法插入的情况了)。
当然,这只是纯理论研究(通过查看数据库ID的顺序得知),真相需要查看代码方可了解。
------鉴定----
说明:上述过程在Firefox下产生(开启flash block情况,将本地路径加入whitelist后一切恢复正常),IE下一切正常。搜狗浏览器选择高速模式无法登录(兼容模式方可登录,不过兼容模式就是IE核心,因此未做测试)
因此最终结论为:程序插入附件的流程操作一切正常,只是偶尔在一些插件启用时造成未知错误而已。出现我这种情况,应该是flash的关系,是它没有返回正确值,导致表单在提交时,调用$this->attach($cid)方法时没有获取到附件情况。而新建文章的时候,对于parent为0的附件,好象程序会强制插入新文章,这一点不敢芶同。
在file_upload.php中就是这样写的:
PHP代码
- if ($cid) {
- Typecho_Widget::widget('Widget_Contents_Attachment_Related', 'parentId=' . $cid)->to($attachment);
- } else {
- Typecho_Widget::widget('Widget_Contents_Attachment_Unattached')->to($attachment);
- }
我还是觉得这种事情应该交由用户处理,而不是在新建文章的时候被强制插入。这种情况如果出现在多人协作的时候就会让人受不了了吧?因为他在执行Unattached的execute方法时,where条件中并没有userid。所以A上传的图片,极有可能会被B强制使用。(虽然机率不大,但,难保会出现这种情况。)
Tags: typecho, bug, 文章, attachment
PHP | 评论:1
| 阅读:28774
Submitted by gouki on 2010, June 13, 1:42 PM
typecho 插件之:内容分页SplitArchivePage
当你的文章内容很长时,可以考虑用此插件来给文章进行简单的分页
//原本考虑主动在post和page页插入分页符的,经友情提示,这些可以去除。
//因为如果不这样,我要考虑很多东西,比如richEdit编辑器,但这种编辑器太多了。所以直接根据友情提示而放弃主动插入
//如果你不用richEdit,这两行注释可以打开。
// Typecho_Plugin::factory('admin/write-post.php')->content = array('SplitArchivePage_Plugin', 'render');
// Typecho_Plugin::factory('admin/write-page.php')->content = array('SplitArchivePage_Plugin', 'render');
0.1.5 原有的程序只支持一个GET变量,现在已修正,只要是GET变量都支持【如果使用了typecho 插件:搜索来源关键字高亮0.1.2版本,请务必更新到此版本】
0.1.4 修正了Rewrite规则下,还会自动加上index.php的BUG,目前在Rewrite规则下去除了index.php
0.1.3 修正了内容页中如果没有插入分页符内容不能显示的BUG(疏忽)
0.1.2 基本功能实现
下载地址为:
【0.1.5】splitarchivepage.rar
【0.1.4】splitarchivepage.rar
【0.1.3】splitarchivepage.rar
Tags: typecho, splitarchive
PHP | 评论:14
| 阅读:49792
Submitted by gouki on 2010, June 13, 10:16 AM
看typecho第二天了,不过我还是没有仔细查看源码,只是根据一些其他插件的应用来写自己的应用。
比如,看了Akismet插件后,知道了 Typecho_Widget_Helper_Form 对象还有一个 addRule 方法,用来对数据进行验证。
昨天看了一下源码,并对应我昨天的方法了解Typecho页面中可以被注入对象的地方,在插件的activate中写了两个方法,可以让插件在全局被应用。
Typecho_Plugin::factory('index.php')->begin = array('DbBackup_Plugin', 'backup');
Typecho_Plugin::factory('admin/common.php')->begin = array('DbBackup_Plugin', 'backup');
嗯。是准备考虑备份的。前后台都有。正在尝试。如果并未按照我预想的情况运行的话,可能只考虑前台触发了。
加了三个参数:
$rate = new Typecho_Widget_Helper_Form_Element_Text('rate', NULL, '1', _t('备份频率'),_t('备份数据的频率(最小单位为天,请使用整数)'));
$form->addInput($rate->addRule('isInteger',_t('请输入整数')));
$email = new Typecho_Widget_Helper_Form_Element_Text('email', NULL, '', _t('备份发送到'),_t('发送邮件地址。'));
$form->addInput($email->addRule('email',_t('请输入正确的邮箱地址')));
$lastbackup = new Typecho_Widget_Helper_Form_Element_Text('lastbackup', NULL, '', _t('上次备份时间'),_t('无需设置,由程序自动生成'));
$form->addInput($lastbackup);
但是isInteger,这个验证方法是验证is_numeric,其实我是希望是一个正整数。现在,先将就一下下喽。离完成还早,顺便附上两个昨天写的垃圾插件,敬请测试(主要是官方论坛我注册后收不到邮件,所以无法登录。过会我再换个邮箱试试)
文章分页:已经删除,请移步typecho 插件:内容分页SplitArchivePage 进行下载 【演示地址】
高亮搜索引擎来源关键字:highlightsearchkeywords.rar 【这个,在这现在这个博客上测试成功,但是在typecho上没有办法测试,因为没有数据,google搜索不到。。。】
Tags: typecho, 笔记, 插件
PHP | 评论:6
| 阅读:32704
Submitted by gouki on 2010, June 12, 11:14 AM
关于插件这个问题,可以查看这篇JianHua Zhang的Typecho阅读笔记三:插件机制,我想说的就是链接文章里的最后一句。
在Typecho_Plugin的__call魔术方法里把当前设置到的component全部打印在页面上,对于插件开发人员来说是一件非常好的事情,因为这样,你可以了解到,有哪些地方是你可以注入你的插件对象的。
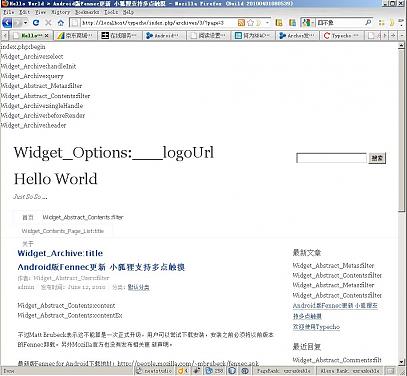
看左上角(看不清的话,请点击看大图)。
Widget_Archive:select
Widget_Archive:handleInit
象这两个,代表了你在插件中就可以写上以下代码来进行注入。
Typecho_Plugin::factory("Widget_Archive")->select = array("插件类名","该类中的方法");
是不是很方便 ?打开每一个页面,你都可以看到类似的代码,有logo,有content,contentEx之类的。了解了这些,在相应的位置上写上你想要的效果,是不是很爽?
顺便,你需要查看一下http://docs.typecho.org/develop/widget。也可以了解一些代码是如何被调用(文中有一点点错误,在看的时候Typecho::widget,应该是Typecho_Widget::widget("xxx"))
Tags: typecho, 笔记, 插件注入
PHP | 评论:4
| 阅读:30307
Submitted by gouki on 2010, June 12, 10:57 AM
文章来自:http://blog.csdn.net/jh_zzz/archive/2010/01/11/5173876.aspx
由于我也正在看 typecho这个玩意所以,就记录下来。虽然我一天下来,也看了不少代码,但毕竟没有深读过。对于流程啥的,还没有开始关心,只是为了写而写。
第三篇:插件机制
以 index.php 为例:
/** 初始化组件 */
Typecho_Widget:: widget('Widget_Init' );
Init 的 execute 中会初始化 Typecho_Plugin ,这里 $options -> plugins 是从数据库读出来后反序列化的:
Typecho_Plugin:: init($options -> plugins);
init 中分别将 plugins 中的 activated 和 handles
PHP代码
- $component = $this -> _handle . ':' . $component ;
- $last = count($args );
- $args [$last ] = $last > 0 ? $args [0 ] : false ;
-
- if (isset (self:: $_plugins ['handles' ][$component ])) {
- $args [$last ] = NULL ;
- $this -> _signal = true ;
- foreach (self:: $_plugins ['handles' ][$component ] as $callback ) {
- $args [$last ] = call_user_func_array($callback , $args );
- }
- }
__call 查找对应 index.php:begin 的 Typecho_Plugin ,如果找到的话,就会调用相应的方法。例如如果找到的是 HelloWorld_Plugin ,则 HelloWorld_Plugin.render() 会被执行。
(
[0] => HelloWorld_Plugin
[1] => render
)
简单说一下 Plugin 是如何加载的,在 config.inc.php 中首先设置了包含路径,插件路径也在其中:
/** 设置包含路径 */
@ set_include_path(get_include_path() . PATH_SEPARATOR .
__TYPECHO_ROOT_DIR__ . '/var' . PATH_SEPARATOR .
__TYPECHO_ROOT_DIR__ . __TYPECHO_PLUGIN_DIR__ );
HelloWorld_Plugin 此时尚未被加载,所以当执行到 HelloWorld_Plugin.render() 时 , Typecho_Common::__autoLoad 函数被执行,这里会自动加载指定的插件文件:
@ include_once str_replace('_' , '/' , $className ) . '.php' ;
例如对于 HelloWorld_Plugin ,文件就是 HelloWorld\Plugin.php ,因为 usr/plugin 目录已经在包含的路径中,所以这个文件可以正常加 载。
当初我学习 php 的时候还是 php3 ,现在一些新特性我都不知道,这一段我看了半天才搞 清楚,这次读这些代码了解了不少 php 的新特性:)
---EOF---
至此,JianHua Zhang的三篇博客都已经转载完毕,但是对于最后这个插件,我是建议在开发的时候,Typecho_Plugin类的__call方法里加上一行:
echo $component . '<br>';
这样可以在显示页面的时候让你了解你每块区域加载了哪些插件,也就是说,这些插件位置,是可以被你注入代码的。OK。了解了这一点,你可以根据你想要的效果为各个地方加上你的代码。
Tags: typecho, 笔记
PHP | 评论:0
| 阅读:23516


