其实gist功能早就见过了。类似功能的网站也非常多,但那些是不要注册 的。不过github这个gist嘛,注册了也有好处。自己把自己曾经写过的代码,还算好的代码,或者有想法的代码缓存下来。对自己以后 回顾的时候也有好处。
毕竟存在自己的电脑上也容易丢掉。这样多了一个碎片的管理,多少也有点好处。
比如,我就有这样一段:
PHP代码
- <?php
-
- $str = "101|1;0|4;1|0;0|0;0|0";
-
-
-
- $array = explode(';', $str);
-
- $items = array();
-
- foreach ($array as $v) {
-
- list($k, $v) = explode('|', $v);
-
- if (emptyempty($v)) {
-
- continue;
-
- }
-
- $items[$v] = $k;
-
- }
-
- echo "<pre>";
-
- print_r($items);
-
- echo "</pre>";
-
-
-
- parse_str(preg_replace(array('/\d+\|0/','/;/','/\|/'),array("","&","="),$str),$result);
-
- echo "<pre>";
-
- print_r($result);
-
- echo "</pre>";
看上去有点乱。不过。。。到:https://gist.github.com/4405542看就好很多了。。
我看看在代码里能不能引用:
这是昨天SAE分享的一篇文章,开始的时候,我看了一遍,发现好象没有什么特别的内容,但再仔细看的时候,发现居然可以这样做。。。
问题描述:
我们要访问的表是一个非常大的表,四千万条记录,id是主键,program_id上建了索引。
执行一条SQL:
select * from program_access_log where program_id between 1 and 4000
这条SQL非常慢。我们原以为处理记录太多的原因,所以加了id限制,一次只读五十万条记录
select * from program_access_log where id between 1 and 500000 and program_id between 1 and 4000
但是这条SQL仍然很慢,速度比上面一条几乎没有提升。Mysql处理50万条记录的表,条件字段还建了索引,这条语句应该是瞬间完成的。
问题分析:
这张表大约容量30G,数据库服务器内存16G,无法一次载入。就是这个造成了问题。
这条SQL有两个条件,ID一到五十万和Program_id一到四千,因为program_id范围小得多,mysql选择它做为主要索引。
先通过索引文件找出了所有program_id在1到4000范围里所有的id,这个过程非常快。
接下来要通过这些id找出表里的记录,由于这些id是离散的,所以mysql对这个表的访问不是顺序读取。
而这个表又非常大,无法一次装入内存,所以每访问一条记录mysql都要重新在磁盘上定位并把附近的记录都载入内存,大量的IO操作导致了速度的下降。
问题解决方案:
1. 以program_id为条件对表进行分区
2. 分表处理,每张表的大小不超过内存的大小
然而,服务器用的是mysql5.0,不支持分区,而且这个表是公共表,无法在不影响其它项目的条件下修改表的结构。所以我们采取了第三种办法:
select * from program_access_log where id between 1 and 500000 and program_id between 1 and 15000000
现在program_id的范围远大于id的范围,id被当做主要索引进行查找,由于id是主键,所以查找的是连续50万条记录,速度和访问一个50万条记录的表基本一样
总结:
这是一个在千万笔记录表中由于使用了索引导致了数据查找变慢的问题,有一定的典型性和大家交流下!
-----------
看我标红的那一段,原来还能够这样做,以前真的没有注意过,也从来没有想过,先利用主键做一次过滤。这样效率会好很多啊
上述内容来自:http://ourmysql.com/archives/108?f=wb,该网站还有很多技巧值得一看。
如何为自己的项目选择一份开源许可协议?
什么GPL,LGPL,APACHE,MIT,BSD,等等,你都明白吗?阮一峰在博客里这样写的:http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html,他画了一个图,比较直观:
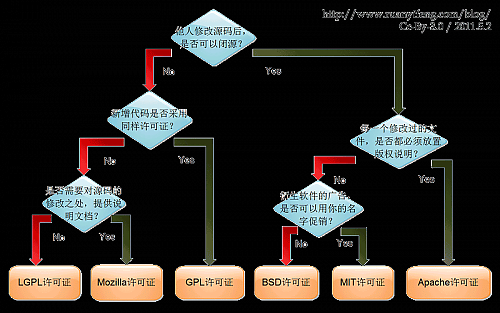
但这毕竟只是一个图片,虽然直观了,但这些协议究竟是什么 意思呢?
百度百科里有介绍:http://baike.baidu.com/view/1588839.htm,但我看了一下,居然没有这个页面的全(http://univasity.iteye.com/blog/1292658)
所以我悄悄的复制了过来。做个了解,如果只是想一个协议,那么看阮一峰的图就可以了,如果你要保护自己的代码,也允许别人闭源,那么,BSD协议真的是可以选择的。如果为了代码的可靠性,那么就选 apache协议吧。
下面是http://univasity.iteye.com/blog/1292658的内容,他还对代码的contributors和recipients等 都做了一些介绍。
关于开源许可
基本概念
1.Contributors 和 Recipients
Contributors(贡献者) ——指的是对某个开源软件或项目提供了代码(包括最初的或者修改过)的人或实体(退队【这应该是团队吧】、公司、组织等)。
按照贡献的先后可分为"创始人"(an initial Contributor)和"参与者"(subsequent Contributors)。
Recipients(获取者) ——指的是开源软件或项目的使用者。
显然,subsequent Contributors也属于Recipients之列。
2.Source Code 和 Object Code
Source Code ——指的是由各种语言写成的源代码 。
Object Code ——指的是Source Code经过编译后,生成的类似“类库”一样的,提供了各种接口供他人使用的目标代码 (就如,DLL、JAR等)。
3.Derivative Module 和 Separate Module
Derivative Module(衍生模块) ——指的是,依托或包含“最初的”或者“从别人处获取的”开源代码而产生的代码,是对“源代码模块”的增强、改善和延续。
Separate Module(独立模块) ——指的是,参考或借助“源代码”开发出来的独立的,不包含、不依赖于原“源代码模块”的功能模块。
*Apache License, 2.0 (Apache-2.0)
*BSD 3-Clause "New" or "Revised" license (BSD-3-Clause)
*BSD 3-Clause "Simplified" or "FreeBSD" license (BSD-2-Clause)
*GNU General Public License (GPL)
*GNU Library or "Lesser" General Public License (LGPL)
*MIT license (MIT)
*Mozilla Public License 1.1 (MPL-1.1)
*Common Development and Distribution License (CDDL-1.0)
*Eclipse Public License (EPL-1.0)
注:原Common Public License 1.0已被Eclipse Public License (EPL-1.0)替代。
Apache Lience允许使用者修改和重新发布代码(以其他协议形式),允许闭源商业发布和销售。
Apache Lience鼓励代码共享和尊重原作者的著作权。
使用Apache Licence协议,需要遵守以下规则:
1.需要给代码的用户一份Apache Lience;
2.如果你修改了代码,需要在被修改的文件中说明;
3.在延伸的代码中(修改或衍生的代码)需要带有原来代码中的协议、商标、专利声明和其他原来作者规定需要包含的说明。
4.如果再发布的产品中包含了Notice文件,则需要在Notice文件中带有Apache Lience。你可以在Notice中增加自己的许可,但不可以表现为对Apache Lience构成更改。
* Apache Licence是对商业应用友好的许可。使用者也可以在需要的时候修改代码来满足需要并作为开源或商业产品发布/销售。
目前分为BSD 3-Clause和BSD 2-Clause。顾名思义,3-Clause包含3个条款,2-Clause只有两个。
BSD允许使用者修改和重新发布代码(以其他协议形式),允许闭源商业发布和销售。
BSD鼓励代码共享的同时,要求尊重代码作者的著作权。
使用BSD协议,需要遵守以下规则(2-Clause则不带第3条):
1.如果再发布的产品中包含源代码,则在源代码中必须带有原来代码中的BSD协议;
2.如果再发布的只是二进制类库/软件,则需要在类库/软件的文档那个和版权声明中包含原来代码中的BSD协议;
3.不可以用开源代码的“作者/机构的名字”或“原来产品的名字”做市场推广。
要点:商业软件可以使用,也可以修改使用BSD协议的代码。
GPL的出发点是代码的开源/免费使用和引用/修改/衍生代码的开源/免费使用,但不允许修改后和衍生的代码做为闭源的商业软件发布和销售。
GPL具有“传染性”,只要在一个软件中使用(“使用”指类库引用,修改后的代码或者衍生代码)GPL协议的产品,则该软件产品必须也采用 GPL协议,既必须也是开源和免费。
GPL对商业发布的限制(引自Java视线论坛的Robbin):
“GPL是针对软件源代码的版权,而不是针对软件编译后二进制版本的版权.你有权免费获得软件的源代码,但是你没有权力免费获得软件的二进制发行版本.GP对软件发行版本唯一的限制就是:你的发行版本必须把完整的源代码一同提供.”
使用GPL协议,需要遵守以下规则:
1、确保软件自始至终都以开放源代码形式发布,保护开发成果不被窃取用作商业发售。任何一套软 件,只要其中使用了受 GPL 协议保护的第三方软件的源程序,并向非开发人员发布时,软件本身也就自动成为受 GPL 保护并且约束的实体。也就是说,此时它必须开放源代码。
2、GPL 大致就是一个左侧版权(Copyleft,或译为“反版权”、“版权属左”、“版权所无”、“版责”等)的体现。你可以去掉所有原作的版权 信息,只要你保持开源,并且随源代码、二进制版附上 GPL 的许可证就行,让后人可以很明确地得知此软件的授权信息。GPL 精髓就是,只要使软件在完整开源 的情况下,尽可能使使用者得到自由发挥的空间,使软件得到更快更好的发展。
3、无论软件以何种形式发布,都必须同时附上源代码。例如在 Web 上提供下载,就必须在二进制版本(如果有的话)下载的同一个页面,清楚地提供源代码下载的链接。如果以光盘形式发布,就必须同时附上源文件的光盘。
4、开发或维护遵循 GPL 协议开发的软件的公司或个人,可以对使用者收取一定的服务费用。但还是一句老话——必须无偿提供软件的完整源代码,不得将源代码与服务做捆绑或任何变相捆绑销售。
由于GPL严格要求使用了GPL类库的软件产品必须使用GPL协议,所以商业软件就不适合采用使用GPL协议的开源代码。
要点:商业软件不能使用GPL协议的代码。
与GPL的强制性开源不同的是,LGPL允许商业软件通过类库引用(link)的方式使用LGPL类库而不需要开源商业软件的代码。
但是如果修改LGPL协议的代码或者衍生,则所有修改的代码,涉及修改部分的额外代码和衍生的代码都必须采用LGPL协议。因此LGPL协议的 开源代码很适合作为第三方类库被商业软件引用,但不适合希望以LGPL协议代码为基础,通过修改和衍生的方式做二次开发的商业软件采用。
要点:商业软件可以使用,但不能修改LGPL协议的代码。
[MIT许可证之名源自麻省理工学院(Massachusetts Institute of Technology, MIT),又称「X条款」(X License)或「X11条款」(X11 License)]
MIT是和BSD一样宽范的许可协议,作者只想保留版权,而无任何其他了限制.也就是说,你必须在你的发行版里包含原许可协议的声明,无论你是以二进制发布的还是以源代码发布的。
要点:商业软件可以使用,也可以修改MIT协议的代码,甚至可以出售MIT协议的代码。
MPL ( Mozilla Public License 1.1 )
MPL协议允许免费重发布、免费修改,但要求修改后的代码版权归软件的发起者 。这种授权维护了商业软件的利益,它要求基于这种软件的修改无偿贡献版权给该软件。这样,围绕该软件的所有代码的版权都集中在发起开发人的手中。但MPL是允许修改,无偿使用得。MPL软件对链接没有要求。
要点:商业软件可以使用,也可以修改MPL协议的代码,但修改后的代码版权归软件的发起者。
CDDL (Common Development and Distribution License )
CDDL(Common Development and Distribution License,通用开发与销售许可)开源协议,是MPL(Mozilla Public License)的扩展协议,它允许公共版权使用,无专利费,并提供专利保护,可集成于商业软件中,允许自行发布许可。
要点:商业软件可以使用,也可以修改CDDL协议的代码。
Common Public License 1.0 (CPL-1.0 )(已废弃)
CPL是IBM提出的开源协议,主要用于IBM或跟IBM相关的开源软件/项目中(例如,Eclipse、Open Laszlo等)。
EPL (Eclipse Public License 1.0 )
EPL允许Recipients任意使用、复制、分发、传播、展示、修改以及改后闭源的二次商业发布。
使用EPL协议,需要遵守以下规则:
1. 当一个Contributors将源码的整体或部分再次开源发布的时候,必须继续遵循EPL开源协议来发布,而不能改用其他协议发布.除非你得到了原“源码”Owner 的授权;
2. EPL协议下,你可以将源码不做任何修改来商业发布.但如果你要发布修改后的源码,或者当你再发布的是Object Code的时候,你必须声明它的Source Code是可以获取的,而且要告知获取方法;
3. 当你需要将EPL下的源码作为一部分跟其他私有的源码混和着成为一个Project发布的时候,你可以将整个Project/Product以私人的协议发布,但要声明哪一部分代码是EPL下的,而且声明那部分代码继续遵循EPL;
4. 独立的模块(Separate Module),不需要开源。
要点:商业软件可以使用,也可以修改EPL协议的代码,但要承担代码产生的侵权责任。
----------------------------------------------------------------------
pack和unpack在一般的程序中还真的不容易见到,但是如果你用过很久以前的php生成excel你就会知道了。他的excel的头就是pack出来的
最近在尝试与C交互的时候又用上了这玩意,所以不得不再看看。其实就是C要求我一定要有包头。。。其实纯字符串也不错嘛。干嘛非得搞个包头呢?真纠结 .。
手册上有pack与unpack的介绍,但都是英文的。。。
任何一款拥有socket操作能力的语言都有一个专门用于组包的函数,php也不例外!
用了很久php了却很少有机会用php进行一些二进制操作。 最近用php写一个socket客户端连接一个用C++语言开发的游戏服务端。 服务器端开发人员使用了二进制的形式来定义协议的格式。协议格式如下:
包头(2bytes)+加密(1byte)+命令码(2bytes)+帧内容
1.包头的内容是记录帧内容的长度;
2. 加密:0表示不加密,1表示加密;
3. 命令码为服务端命令识别符号;
一开始不了解php原来有pack可以来组装二进制包, 走了弯路,让服务端开发人员用C语言帮忙开发了的几个内存操作函数,按照协议规则返回二进制包,然后我将这几个方法编译成一组扩展函数供php使用。
话归正题,本文是介绍如何使用pack和unpack这两个方法的。php官方手册举例太少,不能很容易理解,特别是那些格式化参数的使用。
转摘的参数中文说明:
pack/unpack 的摸板字符字符 含义
a 一个填充空的字节串
A 一个填充空格的字节串
b 一个位串,在每个字节里位的顺序都是升序
B 一个位串,在每个字节里位的顺序都是降序
c 一个有符号 char(8位整数)值
C 一个无符号 char(8位整数)值;关于 Unicode 参阅 U
d 本机格式的双精度浮点数
f 本机格式的单精度浮点数
h 一个十六进制串,低四位在前
H 一个十六进制串,高四位在前
i 一个有符号整数值,本机格式
I 一个无符号整数值,本机格式
l 一个有符号长整形,总是 32 位
L 一个无符号长整形,总是 32 位
n 一个 16位短整形,“网络”字节序(大头在前)
N 一个 32 位短整形,“网络”字节序(大头在前)
p 一个指向空结尾的字串的指针
P 一个指向定长字串的指针
q 一个有符号四倍(64位整数)值
Q 一个无符号四倍(64位整数)值
s 一个有符号短整数值,总是 16 位
S 一个无符号短整数值,总是 16 位,
字节序跟机器芯片有关
u 一个无编码的字串
U 一个 Unicode 字符数字
v 一个“VAX”字节序(小头在前)的 16 位短整数
V 一个“VAX”字节序(小头在前)的 32 位短整数
w 一个 BER 压缩的整数
x 一个空字节(向前忽略一个字节)
X 备份一个字节
Z 一个空结束的(和空填充的)字节串
@ 用空字节填充绝对位置
string pack ( string $format [, mixed $args [, mixed $...]] )
一些规则:
1.每个字母后面都可以跟着一个数字,表示 count(计数),如果 count 是一个 * 表示剩下的所有东西。
2.如果你提供的参数比 $format 要求的少,pack 假设缺的都是空值。如果你提供的参数比 $format 要求的多,那么多余的参数被忽略。
下面还是用例子来说明用法会容易理解一点:
PHP代码
- 关于Pack:
-
- 下面的第一部分把数字值包装成字节:
- $out = pack("CCCC", 65, 66, 67, 68); # $out 等于"ABCD"
- $out = pack("C4", 65, 66, 67, 68); # 一样的东西
-
- 下面的对 Unicode 的循环字母做同样的事情:
- $foo = pack("U4", 0x24b6, 0x24b7, 0x24b8, 0x24b9);
-
- 下面的做类似的事情,增加了一些空:
- $out = pack("CCxxCC", 65, 66, 67, 68); # $out 等于 "AB\0\0CD"
-
- 打包你的短整数并不意味着你就可移植了:
- $out = pack("s2", 1, 2);
- # 在小头在前的机器上是 "\1\0\2\0"
- # 在大头在前的机器上是 "\0\1\0\2"
-
- 在二进制和十六进制包装上,count 指的是位或者半字节的数量,而不是生成的字节数量:
- $out = pack("B32", "...");
- $out = pack("H8", "5065726c"); # 都生成“Perl”
-
- a 域里的长度只应用于一个字串:
- $out = pack("a4", "abcd", "x", "y", "z"); # "abcd"
-
- 要绕开这个限制,使用多倍声明:
- $out = pack("aaaa", "abcd", "x", "y", "z"); # "axyz"
- $out = pack("a" x 4, "abcd", "x", "y", "z"); # "axyz"
-
- a 格式做空填充:
- $out = pack("a14", "abcdefg"); # " abcdefg\0\0\0\0\0\0"
-
- 关于unpack:
-
- array unpack ( string $format, string $data )
-
- $data = "010000020007";
- unpack("Sint1/Cchar1/Sint2/Cchar2",$data);
-
- ## array('int1'=>1, 'char1'=>'0','int2'=>2,'char2'=>7);
-
- 最后本文开头讲到的协议使用pack/unpack 举例程序代码为 :
-
- $lastact = pack('SCSa32a32',0x0040, 0x00, 0x0006, $username, $passwd );
-
- unpack('Sint1/Cchar1/Sint2/Cchar2/',$lastmessage);
学习资料:
http://blog.csdn.net/jojobb3138688/archive/2007/05/07/1598609.aspx
我上面的内容来自于:http://blog.sina.com.cn/s/blog_3eba8f1c0100nq9r.html,我现在已经顺利的使用完了。黑黑
还有的参考资料:
http://bbs.phpchina.com/thread-104492-1-1.html
http://hi.baidu.com/chinetman/item/f78a71d847e7d638e2108fda
其实,这是一个EAP的splash screen,不知道新版是不是真的会变。所以我贴出来了
更新内容其实很正常,但LOGO就不正常了。。有兴趣就看看,并去下载吧,文中有链接。原文来自:http://blog.jetbrains.com/webide/2012/12/phpstorm-6-eap-build-124-295/
This holiday’s EAP brings a traditional set of improvements. Some highlights are:
- PHP type inference for ’$var->prop’ and ‘$var['key']‘ expressions (assignments tracking, instanceof and ‘is_bool’-like functions)
- Code folding in Twig templates for blocks and control structures
- Textmate bundle support included
- More details on PHP and Platform changes available in tracker
We are working on improved type inference, composer support and framework integration, although features will take some time to show up.
As usual, bear in mind that you are getting a snapshot of work in progress and product will undergo series of technical and cosmetic changes.
Download PhpStorm 6.0 EAP build 124.295 for your platform from project EAP page. Patch-update is also available.
This is a last build.. of 2012. We are closed for holidays and wish you a happy apocalypse.
Spent your time with pleasure!
-JetBrains Web IDE Team
LOGO在此:

看看评论里,好象也有人喜欢这个新的splash screen