Submitted by gouki on 2010, December 8, 3:34 PM
这是今天中午发生的事情,有人在群里求助,比如xml中如果标记是<xx:xxxx>content</xx:xxxx>这样的情况下,取不到 xx:xxxx 为下标的值。
看了这个问题,第一个反应就是namespace的关系,但我从来没有使用simplexml操作过namespace,于是就翻开手册查了一下资料,问题并没有解决,最终是通过google解决了该问题。
提问题的朋友贴出了数据源,来自于:http://code.google.com/intl/zh-CN/apis/contacts/docs/3.0/developers_guide_protocol.html#retrieving_without_query,数据结构大致如下:
XML/HTML代码
- <feed xmlns='http://www.w3.org/2005/Atom' xmlns:openSearch='http://a9.com/-/spec/opensearch/1.1/' xmlns:gContact='http://schemas.google.com/contact/2008' xmlns:batch='http://schemas.google.com/gdata/batch' xmlns:gd='http://schemas.google.com/g/2005' gd:etag='W/"CUMBRHo_fip7ImA9WxRbGU0."'>
- <id>liz@gmail.com</id>
- <updated>2008-12-10T10:04:15.446Z</updated>
- <category scheme='http://schemas.google.com/g/2005#kind' term='http://schemas.google.com/contact/2008#contact' />
- <title>Elizabeth Bennet's Contacts</title>
- <link rel='http://schemas.google.com/g/2005#feed' type='application/atom+xml' href='https://www.google.com/m8/feeds/contacts/liz%40gmail.com/full' />
- <link rel='http://schemas.google.com/g/2005#post' type='application/atom+xml' href='https://www.google.com/m8/feeds/contacts/liz%40gmail.com/full' />
- <link rel='http://schemas.google.com/g/2005#batch' type='application/atom+xml' href='https://www.google.com/m8/feeds/contacts/liz%40gmail.com/full/batch' />
- <link rel='self' type='application/atom+xml' href='https://www.google.com/m8/feeds/contacts/liz%40gmail.com/full?max-results=25' />
- <author>
- <name>Elizabeth Bennet</name>
- <email>liz@gmail.com</email>
- </author>
- <generator version='1.0' uri='http://www.google.com/m8/feeds'> Contacts </generator>
- <openSearch:totalResults>1</openSearch:totalResults>
- <openSearch:startIndex>1</openSearch:startIndex>
- <openSearch:itemsPerPage>25</openSearch:itemsPerPage>
- <entry gd:etag='"Qn04eTVSLyp7ImA9WxRbGEUORAQ."'>
- <id> http://www.google.com/m8/feeds/contacts/liz%40gmail.com/base/c9012de </id>
- <updated>2008-12-10T04:45:03.331Z</updated>
- <app:edited xmlns:app='http://www.w3.org/2007/app'>2008-12-10T04:45:03.331Z</app:edited>
- <category scheme='http://schemas.google.com/g/2005#kind' term='http://schemas.google.com/contact/2008#contact' />
- <title>Fitzwilliam Darcy</title>
- <gd:name>
- <gd:fullName>Fitzwilliam Darcy</gd:fullName>
- </gd:name>
- <link rel='http://schemas.google.com/contacts/2008/rel#photo' type='image/*' href='https://www.google.com/m8/feeds/photos/media/liz%40gmail.com/c9012de' gd:etag='"KTlcZWs1bCp7ImBBPV43VUV4LXEZCXERZAc."' />
- <link rel='self' type='application/atom+xml' href='https://www.google.com/m8/feeds/contacts/liz%40gmail.com/full/c9012de' />
- <link rel='edit' type='application/atom+xml' href='https://www.google.com/m8/feeds/contacts/liz%40gmail.com/full/c9012de' />
- <gd:phoneNumber rel='http://schemas.google.com/g/2005#home' primary='true'> 456 </gd:phoneNumber>
- <gd:extendedProperty name='pet' value='hamster' />
- <gContact:groupMembershipInfo deleted='false' href='http://www.google.com/m8/feeds/groups/liz%40gmail.com/base/270f' />
- </entry>
- </feed>
这个结构在上面的地址里有,这个是我格式化过的XML数据,现在要取得类似于“<gd:phoneNumber rel='http://schemas.google.com/g/2005#home' primary='true'> 456 </gd:phoneNumber> ”中的值。
最终代码如下:
PHP代码
- $x = new SimpleXmlElement($str);
- foreach($x->entry as $t){
- echo $t->id . "<br >";
- echo $t->updated . "<br />";
- $namespaces = $t->getNameSpaces(true);
- $gd = $t->children($namespaces['gd']);
- echo $gd->phoneNumber;
- }
当然,如果不象上面这样写,也可以写成这样:
PHP代码
- $x = new SimpleXmlElement($str);
- foreach($x->entry as $t){
- echo $t->id . "<br >";
- echo $t->updated . "<br />";
-
-
- $gd = $t->children('http://schemas.google.com/g/2005');
- echo $gd->phoneNumber;
- }
只是象第二种写法就属于硬编码了,这样不太好,万一哪天有变化,还得再更改N多代码。
问题接踵而来,比如象下面这段:
XML/HTML代码
- <event:event>
- <event:sessionKey></event:sessionKey>
- <event:sessionName>Learn QB in Minutes</event:sessionName>
- <event:sessionType>9</event:sessionType>
- <event:hostWebExID></event:hostWebExID>
- <event:startDate>02/12/2009</event:startDate>
- <event:endDate>02/12/2009</event:endDate>
- <event:timeZoneID>11</event:timeZoneID>
- <event:duration>30</event:duration>
- <event:description></event:description>
- <event:status>NOT_INPROGRESS</event:status>
- <event:panelists></event:panelists>
- <event:listStatus>PUBLIC</event:listStatus>
- </event:event>
这种非标准的XML,没有定义命名空间,怎么办?在这种情况下,其实SimpleXmlElement就已经直接可以解决了,但是会报warnging,因为他认为event这个命名空间不存在。
解决方法是:
PHP代码
- $xml = @new SimpleXmlElement($str);
- echo "<pre>";
- print_r($xml);
目前看来,这种解决方法比较好。
Tags: php, simplexml, xml, namespace
PHP | 评论:1
| 阅读:25862
Submitted by gouki on 2010, December 7, 8:25 AM
这个玩意,纯收藏了,象QuickSand这个玩意已经被很多人转过了,每年都能在各个推荐中出现,真没劲。还有colortip,如今其实已经真不算稀奇了吧。不过还是转一下,因为对其中有两个插件非常感兴趣:Lettering.js和Masonry。
好吧,上原文【文字版】:
在前两周国外知名博客WDL先后分享了“2010最佳系列”中的“最佳免费WordPress主题”和“最佳免费字体”, 在这个星期又发布了2010年最佳jQuery插件。在2010年,JavaScript框架继续日渐普及,这使得大量的插件被开发出来。满目琳琅,难以 选择心头之好。WDL的作者从大量的优秀jQuery插件精心筛选出一些对Web Designers有帮助的和具备非常不错的视觉效果的Best of the best。
2010年最佳jQuery插件(排名不分先后):
一个加载设置拥有9种过度效果的超级smooth slider,它还支持如链接图像和键盘导航等内容。
通过一个非常不错的洗牌动画实现选项内容重新排序,只需要指定源容器和替换源的目标collection 。新元素将会以奇特缩放+阿尔法效果出现,消失的元素(non-existant in destination collection)平滑地消失或重新排位,移动到它们的目标位置。
Spritely 是一个由Artlogic开发的 jQuery插件,用于使用纯HTML和JavaScript创建动态物体和背景动画。
Lettering.js是一个轻量经的、易于使用的 jQuery插件,可创造出极具个性的网页排版。
Colortip可转换你的页面元素的标题属性为一系列色彩丰富的提示(当你的鼠标移动到不同的标题上会出现不同颜色的字体文本提示)。支持六种色彩主题,这样你可更加容易融合到你的个人网页中去。
Masonry是一个 jQuery布局插件. 你可以将它看作CSS floats的另一面。浮动元素的排列是先水平后垂直,Masonry排列内容是根据一个网格先垂直后水平的。
gvChart是一个使用Google Charts了的jQuery插件,可通过HTML table tag的数据实现交互可视化。它非常容易上手,此外它支持创建五种风格的图标。
这是一个用于创建表格的jQuery插件,所创建的表格可以根据不同的列项目进行A-Z,升序排列,切换效果非常不错。
网站图片保持完整的纵横比比什么都重要。这个jQuery插件可以完美地在slider展示你所有的图片,而不需担心产生变形。 jQuery Image Scale Carousel插件自动改变你所有图片到适合大小,一切都是那么的简单。
YoxView是一个免费的多媒体播放jQuery插件。它易于使用,功能丰富。你可以用它来展示各种媒体,如图像,视频,内嵌的内容,iframes,Flash等等。
MK编译 via WDL
原文地址:http://www.x-berry.com/best-jquery-plugins-of-2010
--EOF--
然后那个gvchart也可以,方便你调用了google chart的一些参数了
Tags: jquery, plugin
Javascript | 评论:0
| 阅读:20250
Submitted by gouki on 2010, December 6, 9:15 AM
那天,看完了王建硕的一篇博客菠萝和筷子的故事,当然我不可能上升到他这样的高度,不过我也可以针对这个说 一下我自己的想法。
或者在上海的用户都会知道有篱笆网,曾经去过该网站的用户或者都知道,它的网站有多么的丑多么的丑,但并不妨碍他们赚钱有赢利。网站只是一个提供信息的平台,王建硕说[至于用户嘛?有了菠萝,他们自然会找到筷子的替代品的。]
所以,经过我慎重的考虑,我决定在我下一个自己的项目中,页面仅支持IE 系列的正常,其他平台的不作考虑了。我不是一个成熟的商业平台,自然不用去考虑那么多东西,否则在上面花费大量的精力实在不是一件好事。
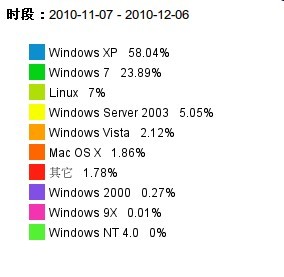
不谈别的,就谈我自己的博客吧,因为我用的是量子统计,因此对于客户端分析的搜索时间跨度只有一个月,我把我最近一个月的数据贴出来(当然我的博客的IP/PV都不算太高,而且很多可能是技术人员。但即使这样):
操作系统:
浏览器:
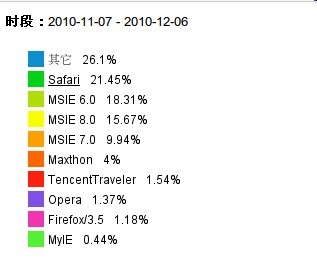
好奇怪,看我的博客的人居然是Safari浏览器居多,奇了怪了,不过,即使是这样,IE678的份额还是占了50%,既然这样,在一些新项目中,我何必在乎那50%的人呢。说白了,不是开发人员,不是有MAC,有多少人会用safari?firefox?所以嘛。。。。
一家之谈,随便发发牢骚,就象一个同事的转贴:

Misc | 评论:4
| 阅读:17750
Submitted by gouki on 2010, December 5, 8:19 PM
以后,每逢周末就乱七八槽写点东西吧。精力有限,而无限制的转载其实意义也不是特别大,除了给自己做笔记外,其他的作用也真不是太大
1、来自yhustc的:微软亚洲研究院面经,因为我不知道Qzone非好友是否能够打开,如果不行,留言给我,我全文转载吧。这里转他的最后6点所谓的心得:
XML/HTML代码
- 微软的面试虽然累,但是收获还是非常丰富的。结合整个找工作的感受,总结几点:
- 1、有疑问要问面试官,除了一面的情况,三面那个float x的问题,我实在不知道怎么做,问面试官希望考察的重点是什么,人家跟我解释的过程其实答案也告诉你了。总比自己一个人沉默的想要好,一个题目不知道,咱们可以进入下一个嘛。
- 2、学过的跟计算机相关的课程,最好都复习一下,尤其是面微软这样的公司。其他公司因为时间受限,可能主要是面试算法题。但是微软有的是时间,一天时间四面,可以非常多的方面了,如果人家想的话。当然,正如二面的面试官说的,主要还是考察你思考问题的过程,背书式的出结果也没啥意思。最好学算法啥的都学通了,为什么要这么用,什么情况下适合用,不要吃快餐。
- 3、学习算法和编程知识的时候要触类旁通,多思考一些引申性的话题。比如一面那个排序用二叉搜索树来做,如果问你搜索树能不能排序,肯定说能,反过来问排序算法有哪些,估计很多人直接忽略了搜索树。再比如多线程加锁,各种情况下如何加锁更合适呢?现有的一些数据结构是否合适在多线程下操作呢?多思考一下,不管有没有结果,总比到了面试的时候再想要好得多。
- 4、实事求是,不隐瞒,多沟通。别的不说吧,就说现在的面试官以后可能是你的同事,你说要是面试过程中不实事求是,即使侥幸进入了,同事以后相处也是问题。一面最后有一个函数发生器的题目,跟四面最后一题一样,我看过类似的。我觉得没有必要隐瞒自己解题的思路,或者说故意假装想了很久,直接说我们先来思考一个别的题目吧,有点类似。进而讨论那个题目的时候,在面试官帮助下想想,能否借用已有知识解这个题。相信面试官也希望你是一个能触类旁通,容易沟通的人,而不是一个闷着头自己干的人。
- 5、每次面试不管成功与否,都应该总结经验;对于简历上的每项内容,都要准备好扩展内容,而不是简单罗列。总结经验改进不足,相信很多人知道。而扩展简历内容说的是什么呢?很多人列了项目经历,现在给你一个问题,介绍一下XX项目。你准备怎么回答?简历上只有摘要的条目,离面试要求查远了。所以一定要提前准备,项目做了什么,有何意义,应用场景,自己的工作,问题和收获,自己对项目的思考,这些都可以提前准备一下,然后面试的时候按照一个流程娓娓道来。
-
- 6、最后一个是本次找工作过程中的一个最大感受。相信很多人都会看很多书补充知识,但是书后面的题目,尤其是思考题,不知道有多少人做。编程之美上面每一章几乎都有拓展的思考题。我遇到过三次笔试或面试题目是这个思考题类似的。盛大和百度的笔试里面有,而因为我提前思考过,所以就直接做了。比当场想要好吧?腾讯的终面问了这么一个题目,搜索引擎如何区分伪原创。这个题目的精简版是根据关键字生成网页摘要,编程之美上面有。而页面相关,是这一章的思考题。当天中午我思考了一下,当天下午面试就遇到了比思考题更进一步的扩展。比面试当场想要好吧?并不一定是要压题,而是根据思考题发散思维,自己多想想有哪些解决方案,遇到类似问题不会那么仓促。
2、博客园的棍子上的萝卜推荐几本javascript与jquery的好书。前端用户可以看,话说那本PPK谈javascript我也有,确实感觉很简单。。然后作者在书中介绍了一个网址,有一些JS的参考手册哦:http://stephen830.javaeye.com/category/57459。
然后很奇怪的是发现这个域名居然是javaeye,然后又很奇怪的发现,它居然可以打开了,好奇怪的事情啊。。。关于它不能打开,robbin说的那句程序写的太好也是错啊,网上可以搜到这条信息的。
3、前两天,有人在博客园上批评了金山安全卫士的源码写的糟糕(金山安全卫士代码批评),其中有一段就是过多的if..else,认为用表驱动会效果和效率上都会好很多,当时文中还说了,如果不知道表驱动,那么就到google里搜索一下吧。(很多玩意儿果然只是一个名词,其实一说大家都懂)。于是这里有一篇简单的介绍和学习,可以参考一下:http://www.cnblogs.com/birdshover/archive/2010/12/02/1894703.html。
4、重构,重构,这句话,被大多数人都挂在嘴边,可是有多少人真正去做了?当晚上发现代码有问题,你第二天会去重构一下吗?一般来说,如果时间上很充分,我还是会去做这样的事情的,但你如果在一小公司,每天在不停的赶任务,你会去主动重构吗?或者会乘周末想办法重构?重构的好处是什么大家都懂,还有一本书叫《重构》,还有一个人在写《重构之美》,反正,随便折腾喽。。。
Tags: 招聘, 手册, 重构, 表驱动
Misc | 评论:0
| 阅读:18118
Submitted by gouki on 2010, December 4, 11:48 AM
在转这篇文章之前,我先说一点项目中遇到的问题,公司的主页最近改版上线,但是上线后出了一点问题,是CSS方面的问题。
CSS文件很多,前端把它分的很细,每一个小的widget部位就是一个单独的CSS文件,这样确实方便了有重复内容时的工作量减轻。于是我们在上线后,对CSS文件进行了合并,用的是Yii的插件 EclientScript(@hightman开发的一个插件)。CSS和JS都顺利合并了,但结果却不太正常。经过仔细检查发现是每个文件头的@charset=utf-8导致了这个问题。合并后,所有的文件内容都被引用到一起,所以造成了合并后的文件中“@charset=utf8”有好几个,但是为了保证文件是按utf-8格式被加载于是保留了最上面的@charset=utf8,其余的都删除了。OK,这时候所有的流量器都正常了。
结果第二天,老板过来说,在IPAD下不正常,于是继续排查,最终发现还是这个@charset=utf8的原因。前面说过,我们只保留了第一个文件的UTF8的判断,其他的都清空了,那为什么还会出错呢?经过测试,发现@charset=utf-8只能在第一行才有效,在其他行时,safari不认,而EClientScript在压缩文件后,会在文件第一行加上这个文件对应实际文件的地址,于是就让@charset=utf8到了第二行。所以IPAD上面显示就不太正常了。。
接下来就转载了:CSS通用元素选择器的都市流言,原文来自:http://shawphy.com/2010/11/css-universal-selector.html
本文尚未有测试数据支持,以下结论仅是根据现有情况的一种解释。
关于 * 这个选择器,一直有个疑惑,到底是否影响效率。在先前的观念中,这由于要匹配所有的元素,让每一个元素都带上这个属性,所以会影响页面的效率。但近来的思考,觉得这应该不会影响效率。为此还特地写过一篇博文,里边提到了这点:真的还需要reset.css么?
而这篇文章中我打算着重阐述为何 * 这个选择器不会影响效率。
上周六去参加了 web标准化交流会,席间 winter 从浏览器(webkit)的角度分享了关于页面渲染的过程。其PPT也可以在前面的链接中下载到。
其中一个很重要的过程是,当页面载入过程中,CSS 和 HTML 是并行下载的。并且通常CSS是在HEAD中引入的,并且体积不如HTML大,所以CSS会先下载完。下载的过程中浏览器就已经开始对CSS中的规则进行 索引,也就是已经确定哪一个元素呈现的样式是如何的了。同时,浏览器根据HTML构建出的DOM树,其中的每一个元素会直接去CSS规则索引中去比对,构 建出渲染树。这个过程都是并行的,并且CSS规则是进行了索引的,因此速度非常的快速。
那么我们看看CSS规则的来源主要有2个,一是浏览器内置的元素样式,Firefox 3.x版是放在目录下的res文件夹内,4.0版和Chrome中没找到(这里是我的主观臆断不太可靠,大家自行辨别),另一个就是页面提供的。根据查看 放在 res 文件夹下的 CSS 文件就可以得知,就是是什么样式都不写,已经为每一个HTML元素设定好了基本样式了。
那么看看我们所忌讳的事情,不用*{margin:0;padding:0},而是使用
CSS代码
- html, body, div, span, applet, object, iframe,
- h1, h2, h3, h4, h5, h6, p, blockquote, pre,
- a, abbr, acronym, address, big, cite, code,
- del, dfn, em, font, img, ins, kbd, q, s, samp,
- small, strike, strong, sub, sup, tt, var,
- b, u, i, center,
- dl, dt, dd, ol, ul, li,
- fieldset, form, label, legend,
- table, caption, tbody, tfoot, thead, tr, th, td {
- margin: 0;
- padding: 0;
- }
看看这一大坨东西啊,难道不是跟上面的 * 选择器一个用途么?对每个元素(至少是常用元素),添加样式。其实作用是一样的,并且就算没有这一坨,浏览器内置样式也在对每个元素设置样式。之后 HTML 文件中的每一个元素,可以很容易找到自己应当呈现的样式了。
那么,对于之后添加的,会不会有性能影响呢?也不会,由于CSS规则已经确定并索引了,所以今后增加的元素也不过就是简单比对一下而已,不会多走一步的。
所以,由此得出结论,只要有需要,大胆的使用 * 吧,他不会给你从性能上增加额外的麻烦。
最后补两个前端优化小知识:
1,由于CSS规则和HTML是并行载入的,因此把CSS放在HEAD中是非常有必要的。
2,少使用 :last-child 。因为这个选择器无法索引起来,必须等DOM构件完,才能知道他是不是父元素中最后的那个 元素。这种就非常慢了,慎用。
----EOF--
注:文中@charset=utf-8我格式可能写的不对,只是表达一个意思,因为我没有dreamwaver,而所说DW在写CSS的时候,默认会在第一行加上这个玩意。。。
Tags: css, charset, eclientscript, yii
PHP | 评论:0
| 阅读:21077


