前两天刚刚转载完老王的Linux杂记 ,结果淘宝QA团队也来了一个Linux查看系统配置常用命令,当然,对于这些命令来说我是多多益善。
虽然不一定记得住,但,作为我的参考还是有用的。
系统 # uname -a # 查看内核/操作系统/CPU信息
# head -n 1 /etc/issue # 查看操作系统版本
# cat /proc/cpuinfo # 查看CPU信息
# hostname # 查看计算机名
# lspci -tv # 列出所有PCI设备
# lsusb -tv # 列出所有USB设备
# lsmod # 列出加载的内核模块
# env # 查看环境变量 资源
# free -m # 查看内存使用量和交换区使用量
# df -h # 查看各分区使用情况
# du -sh # 查看指定目录的大小
# grep MemTotal /proc/meminfo # 查看内存总量
# grep MemFree /proc/meminfo # 查看空闲内存量
# uptime # 查看系统运行时间、用户数、负载
# cat /proc/loadavg # 查看系统负载 磁盘和分区
# mount | column -t # 查看挂接的分区状态
# fdisk -l # 查看所有分区
# swapon -s # 查看所有交换分区
# hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备)
# dmesg | grep IDE # 查看启动时IDE设备检测状况 网络
# ifconfig # 查看所有网络接口的属性
# iptables -L # 查看防火墙设置
# route -n # 查看路由表
# netstat -lntp # 查看所有监听端口
# netstat -antp # 查看所有已经建立的连接
# netstat -s # 查看网络统计信息 进程
# ps -ef # 查看所有进程
# top # 实时显示进程状态 用户
# w # 查看活动用户
# id # 查看指定用户信息
# last # 查看用户登录日志
# cut -d: -f1 /etc/passwd # 查看系统所有用户 # cut -d: -f1 /etc/group # 查看系统所有组
# crontab -l # 查看当前用户的计划任务 服务
# chkconfig –list # 列出所有系统服务
# chkconfig –list | grep on # 列出所有启动的系统服务 程序
# rpm -qa # 查看所有安装的软件包
看到最后的rpm,估计淘宝QA们用的是redhat系列的产品线了,什么RH、fedora,centos吧?
估计是,哈哈

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
Linux查看系统配置常用命令
Submitted by gouki on 2009, June 30, 8:43 PM
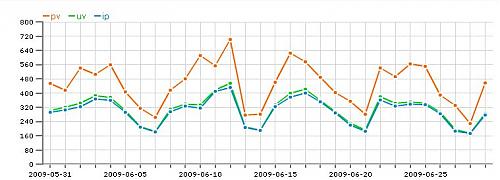
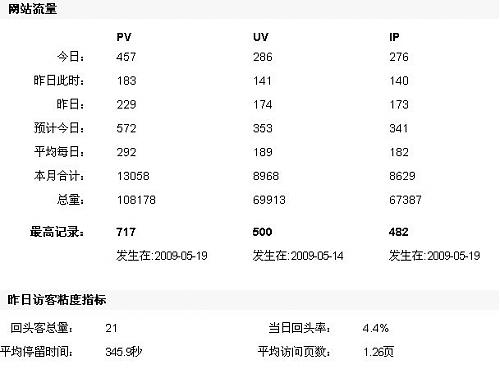
统计一年了
Submitted by gouki on 2009, June 29, 9:34 PM
时间过的真快啊。
一转眼,网站过了一年多了,用上统计也一年了。
本来想在365天的时候,截个屏做个纪念的。结果也忘了
今天已经370天了。
在这里再套用一下至尊宝的话:以前你叫雅虎统计,现在你叫量子统计了(原话:以前你叫人家小甜甜,现在你叫人家牛夫人。。。)
不过,还是做个纪念吧。。
三张图。。。

老王的Linux杂记
Submitted by gouki on 2009, June 29, 7:29 AM
作者:老王
命令ps aux中的TIME是指什么时间。
经验主义会让我们惯性的认为这个时间是程序运行的时间,实际上如果你通过man ps查看一下手册,就会发现这个时间时间上时程序累计占用的CPU时间。
如何判断64位CPU装了32位的操作系统。
总有一些运维人员这么干,所以不得不防。判断操作系统的位数很简单,只要使用uname -i即可,如果是32位的话,则一般显示i386,如果是64位的话,则一般显示x86_64。问题的重点在于判断CPU的位数,查看CPU的信息很简 单,无非就是cat /proc/cpuinfo,但这里哪些信息能表明位数呢?高人可以通过model name来判断,不过对多数人来说,这样的方法缺少可操作性,更好的方法是查看flags里是否有lm选项,lm选项的意思是Long Mode. (64bit Extensions, AMD’s AMD64 or Intel’s EM64T).,有的话就说明是64位,没有就是32位。
CPU feature flags and their meanings
玩转TOP命令
top命令有很多方便的操作,比如执行top命令后按1键就可以展开CPU列表,按c键就可以查看命令完整路径。还可以通过shift+f或者shift+o把进程排序,更多参数通过按键h或者?查询。
管道符中变量范围的问题
先看一个例子,先用read命令给变量赋值,再分别打印:
echo "a b c" | read x y
echo $x
echo $y
结果你会发现$x, $y都没有设置。
echo "a b c" | (read x y; echo $x; echo $y)
这样就OK了,这是因为管道符后面产生的变量仅在子SHELL中有效,类似的还可以采用这样的方式:
echo "a b c" | while read x y; do
echo $x; echo $y
done
watch监控程序
例如用watch监控mysql:watch -n 1 mysqladmin processlist
更方便的history功能
需要历史操作记录的时候,大家基本上都是采用history | grep ...的操作方式,实际上还有更方便的history功能,在man bash里的reverse-search-history部分能查看到相关介绍,操作方式就是Ctrl+r,然后键入部分命令就会自动查找,找到后直接 回车即可。比如说每次重启动nginx都要不厌其烦的kill -HUP `cat /path/to/nginx.pid`,通过使用reverse-search-history技巧,操作会方便快捷很多。
原文地址为:http://hi.baidu.com/thinkinginlamp/blog/item/39734f4ae8346e2a09f7ef8f.html
但有人对于老王验证CPU是否为64位持不同意见,认为他自己的32位CPU中也有lm,我的是xeon,也有lm,我不知道是否同样为64位CPU。。
一切等某个更牛的人来解释一下吧
IE和FF下JS的不同点(更详细)
Submitted by gouki on 2009, June 28, 9:29 PM
在这里,http://www.neatstudio.com/show-52-1.shtml,我也曾转载过关于IE和Firefox下event的处理,只是今天的内容会更全一些 一、document.formName.item("itemName") 问题 九、event.x与event.y问题 十四、body载入问题 虽然我对knowsky网站上的广告颇有微词,但这并不妨碍他上面的文章。原文如下:http://www.knowsky.com/536615.html,估计也是转载来的,因为我看到里面有一些排版内容有变化。
问题说明:IE下,可以使用 document.formName.item("itemName") 或 document.formName.elements ["elementName"];Firefox 下,只能使用document.formName.elements["elementName"]。
解决方法:统一使用document.formName.elements["elementName"]。
二、集合类对象问题
问题说明:IE下,可以使用 () 或 [] 获取集合类对象;Firefox下,只能使用 [ ]获取集合类对象。
解决方法:统一使用 [] 获取集合类对象。
三、自定义属性问题
问题说明:IE下,可以使用获取常规属性的方法来获取自定义属性,也可以使用 getAttribute() 获取自定义属性;Firefox下,只能使用 getAttribute() 获取自定义属性。
解决方法:统一通过 getAttribute() 获取自定义属性。
四、eval("idName")问题
问 题说明:IE下,可以使用 eval("idName") 或 getElementById("idName") 来取得 id 为 idName 的HTML对象;Firefox下,只能使用 getElementById("idName") 来取得 id 为 idName 的HTML对象。
解决方法:统一用 getElementById("idName") 来取得 id 为 idName 的HTML对象。
五、变量名与某HTML对象ID相同的问题
问题说明:IE下,HTML对象的ID可以作为 document 的下属对象变量名直接使用,Firefox下则不能;Firefox下,可以使用与HTML对象ID相同的变量名,IE下则不能。
解决方法:使用 document.getElementById("idName") 代替 document.idName。最好不要取HTML对象ID相同的变量名,以减少错误;在声明变量时,一律加上var关键字,以避免歧义。
六、const问题
问题说明:Firefox下,可以使用const关键字或var关键字来定义常量;IE下,只能使用var关键字来定义常量。
解决方法:统一使用var关键字来定义常量。
七、input.type属性问题
问题说明:IE下 input.type 属性为只读;但是Firefox下 input.type 属性为读写。
解决办法:不修改 input.type 属性。如果必须要修改,可以先隐藏原来的input,然后在同样的位置再插入一个新的input元素。
八、window.event问题
问题说明:window.event 只能在IE下运行,而不能在Firefox下运行,这是因为Firefox的event只能在事件发生的现场使用。
解决方法:在事件发生的函数上加上event参数,在函数体内(假设形参为evt)使用 var myEvent = evt?evt:(window.event?window.event:null)
示例: <input type="button" onclick="doSomething(event)"/>
<script language="javascript">
function doSomething(evt) {
var myEvent = evt?evt:(window.event?window.event:null)
…
}
问题说明:IE下,even对象有x、y属性,但是没有pageX、pageY属性;Firefox下,even对象有pageX、pageY属性,但是没有x、y属性。
解决方法:var myX = event.x ? event.x : event.pageX; var myY = event.y ? event.y:event.pageY;
如果考虑第8条问题,就改用myEvent代替event即可。
十、event.srcElement问题
问题说明:IE下,even对象有srcElement属性,但是没有target属性;Firefox下,even对象有target属性,但是没有srcElement属性。
解决方法:使用srcObj = event.srcElement ? event.srcElement : event.target;
如果考虑第8条问题,就改用myEvent代替event即可。
十一、window.location.href问题
问题说明:IE或者Firefox2.0.x下,可以使用window.location或window.location.href;Firefox1.5.x下,只能使用window.location。
解决方法:使用 window.location 来代替 window.location.href。当然也可以考虑使用 location.replace()方法。
十二、模态和非模态窗口问题
问题说明:IE下,可以通过showModalDialog和showModelessDialog打开模态和非模态窗口;Firefox下则不能。
解决方法:直接使用 window.open(pageURL,name,parameters) 方式打开新窗口。
如 果需要将子窗口中的参数传递回父窗口,可以在子窗口中使用window.opener来访问父窗口。如果需要父窗口控制子窗口的话,使用 var subWindow = window.open(pageURL,name,parameters); 来获得新开的窗口对象。
十三、frame和iframe问题
以下面的frame为例:
<frame src="http://www.devdao.com/123.html" id="frameId" name="frameName" />
(1)访问frame对象
IE:使用window.frameId或者window.frameName来访问这个frame对象;
Firefox:使用window.frameName来访问这个frame对象;
解决方法:统一使用 window.document.getElementById("frameId") 来访问这个frame对象;
(2)切换frame内容
在 IE和Firefox中都可以使用 window.document.getElementById("frameId").src = "devdao.com.html"或 window.frameName.location = "devdao.com.html"来切换frame的内容;
如果需要将frame中的参数传回父窗口,可以在frame中使用parent关键字来访问父窗口。
问题说明:Firefox的body对象在body标签没有被浏览器完全读入之前就存在;而IE的body对象则必须在body标签被浏览器完全读入之后才存在。
[注] 这个问题尚未实际验证,待验证后再来修改。
[注] 经验证,IE6、Opera9以及FireFox2中不存在上述问题,单纯的JS脚本可以访问在脚本之前已经载入的所有对象和元素,即使这个元素还没有载入完成。
十五、事件委托方法
问题说明:IE下,使用 document.body.onload = inject; 其中function inject()在这之前已被实现;在Firefox下,使用 document.body.onload = inject();
解决方法:统一使用 document.body.onload=new Function(’inject()’); 或者 document.body.onload = function(){/* 这里是代码 */}
[注意] Function和function的区别
十六、访问的父元素的区别
问题说明:在IE下,使用 obj.parentElement 或 obj.parentNode 访问obj的父结点;在firefox下,使用 obj.parentNode 访问obj的父结点。
解决方法:因为firefox与IE都支持DOM,因此统一使用obj.parentNode 来访问obj的父结点。
十七、cursor:hand VS cursor:pointer
问题说明:firefox不支持hand,但ie支持pointer ,两者都是手形指示。
解决方法:统一使用pointer。
十八、innerText的问题.
问题说明:innerText在IE中能正常工作,但是innerText在FireFox中却不行。
解决方法:在非IE浏览器中使用textContent代替innerText。
示例: if(navigator.appName.indexOf("Explorer") >-1){
document.getElementById(’element’).innerText = "my text";
} else{
document.getElementById(’element’).textContent = "my text";
}
[注] innerHTML 同时被ie、firefox等浏览器支持,其他的,如outerHTML等只被ie支持,最好不用。
十九、对象宽高赋值问题
问题说明:FireFox中类似 obj.style.height = imgObj.height 的语句无效。
解决方法:统一使用 obj.style.height = imgObj.height + ‘px’;
二十、Table操作问题
问题说明:ie、firefox以及其它浏览器对于 table 标签的操作都各不相同,在ie中不允许对table和tr的innerHTML赋值,使用js增加一个tr时,使用appendChild方法也不管用。
解决方法: //向table追加一个空行:
var row = otable.insertRow(-1);
var cell = document.createElement("td");
cell.innerHTML = "";
cell.className = "XXXX";
row.appendChild(cell); [注] 由于俺很少使用JS直接操作表格,这个问题没有遇见过。建议使用JS框架集来操作table,如JQuery。
二一、ul和ol列表缩进问题
消除ul、ol等列表的缩进时,样式应写成:list-style:none;margin:0px;padding:0px;
其中margin属性对IE有效,padding属性对FireFox有效。← 此句表述有误,详细见↓
[注] 这个问题尚未实际验证,待验证后再来修改。
[注] 经验证,在IE中,设置margin:0px可以去除列表的上下左右缩进、空白以及列表编号或圆点,设置padding对样式没有影响;在 Firefox 中,设置margin:0px仅仅可以去除上下的空白,设置padding:0px后仅仅可以去掉左右缩进,还必须设置list- style:none才 能去除列表编号或圆点。也就是说,在IE中仅仅设置margin:0px即可达到最终效果,而在Firefox中必须同时设置 margin:0px、 padding:0px以及list-style:none三项才能达到最终效果。
二二、CSS透明问题
IE:filter:progid:DXImageTransform.Microsoft.Alpha(style=0,opacity=60)。
FF:opacity:0.6。
[注] 最好两个都写,并将opacity属性放在下面。
二三、CSS圆角问题
IE:ie7以下版本不支持圆角。
FF: -moz-border-radius:4px,或者-moz-border-radius-topleft:4px;-moz- border- radius-topright:4px;-moz-border-radius-bottomleft:4px;-moz- border- radius- bottomright:4px;。
[注] 圆角问题是CSS中的经典问题,建议使用JQuery框架集来设置圆角,让这些复杂的问题留给别人去想吧。
关于CSS中的问题实在太多了,甚至同样的CSS定义在不同的页面标准中的显示效果都是不一样的。更多的知识请参考devdao.com的文章。一个合乎发展的建议是,页面采用标准DHTML标准 编写,较少使用table,CSS定义尽量依照标准DOM,同时兼顾IE、Firefox、Opera等主流浏览器。BTW,很多情况下,FF和 Opera的CSS解释标准更贴近CSS标准,也更具有规范性。
PHP编辑器&IDE简单评测之:NuSphere PhpED
Submitted by gouki on 2009, June 28, 4:44 PM
PHPED是一款很老的PHP编辑器了。在N久以前他就存在,只是4.x以前的版本对中文的支持并不好,当你在删除中文时,往往会发现删除了一半。
PHPED的优点
1、debug功能挺强,自带的dbglistener被很多编辑器所使用过
2、Project和workspace也分开了
3、函数的定位、跳转都比较方便
4、Search in files和replace in files,更是让查找替换方便了许多
5、自定义代码片段
6、常用小工具:ssh,dbmanager,ftp等
7、函数自动完成、提示时,会同时显示该函数所在的文件、行数。
8、作为一款PHPIDE,也并没有忘记HTML,在工具栏中有一些HTML常用标记的快捷按钮
9、帮助手册很多。查询很方便
10、分割屏幕:在代码页很长的时候,并且需要和上文进行对比时,分割屏幕太重要了
PHPED的缺点
1、代码提示、自动完成有时候会失效(特别是在同一个页面里,函数定义在最底部的时候,调用此函数时,不能自动完成和提示)
2、虚拟空格(鼠标点到哪里,就可以在哪里直接输入,或许很多人喜欢这个功能,但我非常不喜欢,让我想起了delphi,好象也是有这个功能,开始怀疑,PHPED是采用delphi编写的)
3、Debug功能对于采用rewrite方式的程序好象无法测试(不知道ZS等是否能够测试)
4、不能根据文件编码自动认出文件(程序只能设定一个编码,然后打开任何文件都是以此编码来打开,打不开就建议你转,这个太烦了)
总体来说,如果不介意上面这些缺点,phped还算是一个比较完美的编辑器。
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
日志分类
- PHP [669]
- python [0]
- Go [9]
- Flutter [227]
- lua [0]
- Scala & Ruby [92]
- Javascript [307]
- PHP Framework [65]
- Linux [5]
- 苹果相关 [286]
- DataBase [0]
- Software [236]
- Literature [9]
- Ideas [27]
- 產品 [14]
- Misc [982]
- Baby [161]
热门标签
-
mysql
php
jquery
yii
ubuntu
google
linux
javascript
firefox
肖佑阳
framework
phpstorm
database
mac
thinkphp
svn
apache
zend
typecho
wordpress
qq
连载
seo
chrome
优化
ipad
netbeans
ios
css
架构
日志归档
搜索文章
最新评论
- It's going to be ending of...
07-05 - url - 好老的博客系统,当年用过。竟然还有人在用。
06-28 - im2828 - 你好,这个现在不能下载了,请重新提供一下吧
06-18 - 海东青 - 你这博客皮肤都20年了吧,该换了
05-27 - 月票的进哥 - 不用感觉,就是死了,停服公告都发出来了
05-27 - imlonghao
博客信息
- 分类数量: 17
- 文章数量: 3154
- 评论数量: 1911
- 标签数量: 2284
- 附件数量: 940
- 注册用户: 56
- 今日访问: 4302
- 总访问量: 75928487
- 程序版本: 1.6
