
在cssrain.cn上看到很多jquery的最新插件和代码,也深为该站站长感到由衷的倾(突然就不知道这个字怎么打了,郁闷,打了个同音字,五笔也会忘字。。。汗)佩,坚持本来就是一种美德。
他的网上有很多jquery插件哦,这两天又贴了ajax大会的资料,如果是在上海,我就肯定去参加了,可惜离我太远了。
然后又看到这个PPT,入门级,我没有细看,但我想可能很多人会需要这些吧。于是下载到本地再上传了一下。
Submitted by gouki on 2009, February 10, 12:00 AM
在cssrain.cn上看到很多jquery的最新插件和代码,也深为该站站长感到由衷的倾(突然就不知道这个字怎么打了,郁闷,打了个同音字,五笔也会忘字。。。汗)佩,坚持本来就是一种美德。
他的网上有很多jquery插件哦,这两天又贴了ajax大会的资料,如果是在上海,我就肯定去参加了,可惜离我太远了。
然后又看到这个PPT,入门级,我没有细看,但我想可能很多人会需要这些吧。于是下载到本地再上传了一下。
附件: jquery入门篇.rar (245.64 K, 下载次数:11323)
Submitted by gouki on 2009, January 18, 8:07 PM
jquery 1.3刚刚出来没几天,shawphy的中文API就基本出炉了,有时候真的挺佩服他们,当我们在娱乐的时候,他们还在努力的为我们这些人造福。我没有什么其他能力,只能做到代为传播了。同时也是希望有更多的人参与,可以让我们这些使用者也能够更加方便。
网址:http://shawphy.com/2009/01/release-jquery-doc-cn-1-3.html
原文如下:
jQuery 1.3自从2008年1月14日发布后,后引来了各界的关注。我们也随即投入到翻译文档的工作中来。经过4天的努力,终于完工了。这个版本更新了不少东西
changelog:
2009-01-18 16:06:52 +0800
* triggerHandler 进一步说明
* trigger 进一步说明2009-01-17 22:37:11 +0800
* live() - 与bind()不同的是,live()一次只能绑定一个事件。
* [attribute!=value] jQuery 1.3中意义改变
* load 的data参数在jQuery 1.3中也可以接受String
+ ajax的error回调的第二个参数可能值”timeout”, “error”, “notmodified” 和 “parsererror”
+ ajax参数xhr
* animate 的duration为0的问题
* show, hide, toggle, slideDown, slideUp, slideToggle 在jQuery 1.3中,padding和margin也会有动画,效果更流畅。
* jQuery(html,[ownerDocument])等效于$(document.createElement(”span”)
* is支持复杂表达式2009-01-17 18:31:10 +0800
+ jQuery.support.scriptEval
+ 原 Dimension 插件功能(1.2.6版加入jQuery核心)2009-01-16 19:11:10 +0800
+ jQuery.fx.off
+ toggleClass( class, switch )
+ toggle( switch )
+ toggle(speed,[callback])
* 修改queue和dequeue方法的参数和说明2009-01-15 22:31:02 +0800
* jQuery(html,[ownerDocument])
+ jQuery.selector
+ jQuery.context
* 效果下的queue和dequeue搬到核心下
+ live()
+ die()
+ closest()
* stop( [clearQueue], [gotoEnd]) 增加两个参数
+ jQuery.support
+ jQuery.isArray( obj )
感谢Cloudream的热情帮忙。还要感谢一揪制作chm版。这个版本还加入了检查更新的功能。如果有需要的同学可轻松查看是否有更新的中文文档(chm版中的检查更新也将同步升级)。
在线查看 下载离线版 bug提交
Submitted by gouki on 2009, January 18, 12:21 AM
本文作者好象是写mysql proxy的,这是他写的关于order by rand的效率方面的文章。事实上我们在使用中是尽量避免采用order by rand这种的,但应该如何写,他给了我们一些其他的解决方法,并将其效率进行了分析,我觉得很有用,就留下来了。
原文网址:http://jan.kneschke.de/2007/2/15/order-by-rand
内容如下:
If you read the MySQL manual you might have seen the ORDER BY RAND() to randomize the the rows and using the LIMIT 1 to just take one of the rows.
SELECT name
FROM random
ORDER BY RAND()
LIMIT 1;
This example works fine and is fast if you only when let's say 1000 rows. As soon as you have 10000 rows the overhead for sorting the rows becomes important. Don't forget: we only sort to throw nearly all the rows away.
I never liked it. And there are better ways to do it. Without a sorting. As long as we have a numeric primary key.
For the first examples we assume the be ID is starting at 1 and we have no holes between 1 and the maximum value of the ID.
First idea: We can simplify the whole job if we calculate the ID beforehand in the application.
SELECT MAX(id) FROM random;
## generate random id in application
SELECT name FROM random WHERE id = <random-id>
As MAX(id) == COUNT(id) we just generate random number between 1 and MAX(id) and pass it into the database to retrieve the random row.
The first SELECT is a NO-OP and is optimized away. The second is a eq_ref against a constant value and also very fast.
But is it really necessary to do it in the application ? Can't we do it in the database ?
# generating a random ID
> SELECT RAND() * MAX(id) FROM random;
+------------------+
| RAND() * MAX(id) |
+------------------+
| 689.37582507297 |
+------------------+
# oops, this is a double, we need an int
> SELECT CEIL(RAND() * MAX(id)) FROM random;
+-------------------------+
| CEIL(RAND() * MAX(id)) |
+-------------------------+
| 1000000 |
+-------------------------+
# better. But how is the performance:
> EXPLAIN
SELECT CEIL(RAND() * MAX(id)) FROM random;
+----+-------------+-------+-------+------+-------------+
| id | select_type | table | type | rows | Extra |
+----+-------------+-------+-------+------+-------------+
| 1 | SIMPLE | random | index | 1000000 | Using index |
+----+-------------+-------+-------+------+-------------+
## a index scan ? we lost our optimization for the MAX()
> EXPLAIN
SELECT CEIL(RAND() * (SELECT MAX(id) FROM random));
+----+-------------+-------+------+------+------------------------------+
| id | select_type | table | type | rows | Extra |
+----+-------------+-------+------+------+------------------------------+
| 1 | PRIMARY | NULL | NULL | NULL | No tables used |
| 2 | SUBQUERY | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+-------+------+------+------------------------------+
## a simple Sub-Query is bringing us the performance back.
Ok, now we know how to generate the random ID, but how to get the row ?
> EXPLAIN
SELECT name
FROM random
WHERE id = (SELECT CEIL(RAND() *
(SELECT MAX(id)
FROM random));
+----+-------------+--------+------+---------------+------+---------+------+---------+------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+--------+------+---------------+------+---------+------+---------+------------------------------+
| 1 | PRIMARY | random | ALL | NULL | NULL | NULL | NULL | 1000000 | Using where |
| 3 | SUBQUERY | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+--------+------+---------------+------+---------+------+---------+------------------------------+
> show warnings;
+-------+------+------------------------------------------+
| Level | Code | Message |
+-------+------+------------------------------------------+
| Note | 1249 | Select 2 was reduced during optimization |
+-------+------+------------------------------------------+
NO, NO, NO. Don't go this way. This is the most obvious, but also the most wrong way to do it. The reason: the SELECT in the WHERE clause is executed for every row the outer SELECT is fetching. This leads to 0 to 4091 rows, depending on your luck.
We need a way to make sure that the random-id is only generated once:
SELECT name
FROM random JOIN
(SELECT CEIL(RAND() *
(SELECT MAX(id)
FROM random)) AS id
) AS r2
USING (id);
+----+-------------+------------+--------+------+------------------------------+
| id | select_type | table | type | rows | Extra |
+----+-------------+------------+--------+------+------------------------------+
| 1 | PRIMARY | <derived2> | system | 1 | |
| 1 | PRIMARY | random | const | 1 | |
| 2 | DERIVED | NULL | NULL | NULL | No tables used |
| 3 | SUBQUERY | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+------------+--------+------+------------------------------+
The inner SELECT is generating a constant TEMPORARY table and the JOIN is selecting just on single row. Perfect.
No Sorting, No Application, Most parts of the query optimized away.
To generalize the last solution we add the possibility of holes, like when you DELETE rows.
SELECT name
FROM random AS r1 JOIN
(SELECT (RAND() *
(SELECT MAX(id)
FROM random)) AS id)
AS r2
WHERE r1.id >= r2.id
ORDER BY r1.id ASC
LIMIT 1;
+----+-------------+------------+--------+------+------------------------------+
| id | select_type | table | type | rows | Extra |
+----+-------------+------------+--------+------+------------------------------+
| 1 | PRIMARY | <derived2> | system | 1 | |
| 1 | PRIMARY | r1 | range | 689 | Using where |
| 2 | DERIVED | NULL | NULL | NULL | No tables used |
| 3 | SUBQUERY | NULL | NULL | NULL | Select tables optimized away |
+----+-------------+------------+--------+------+------------------------------+
The JOIN now adds all the IDs which are greater or equal than our random value and selects only the direct neighboor if a direct match is not possible. BUT as soon as one row is found, we stop (the LIMIT 1). And we read the rows according to the index (ORDER BY id ASC). As we are using >= instead of a = we can get rid of a the CEIL and get the same result with a little less work.
As soon as the distribution of the IDs is not equal anymore our selection of rows isn't really random either.
> select * from holes;
+----+----------------------------------+----------+
| id | name | accesses |
+----+----------------------------------+----------+
| 1 | d12b2551c6cb7d7a64e40221569a8571 | 107 |
| 2 | f82ad6f29c9a680d7873d1bef822e3e9 | 50 |
| 4 | 9da1ed7dbbdcc6ec90d6cb139521f14a | 132 |
| 8 | 677a196206d93cdf18c3744905b94f73 | 230 |
| 16 | b7556d8ed40587a33dc5c449ae0345aa | 481 |
+----+----------------------------------+----------+
The RAND function is generating IDs like 9 to 15 which all lead to the id 16 to be selected as the next higher number.
There is no real solution for this problem, but your data is mostly constant you can add a mapping table which maps the row-number to the id:
> create table holes_map ( row_id int not NULL primary key, random_id int not null);
> SET @id = 0;
> INSERT INTO holes_map SELECT @id := @id + 1, id FROM holes;
> select * from holes_map;
+--------+-----------+
| row_id | random_id |
+--------+-----------+
| 1 | 1 |
| 2 | 2 |
| 3 | 4 |
| 4 | 8 |
| 5 | 16 |
+--------+-----------+
The row_id is now free of holes again and we can run our random query again:
SELECT name FROM holes
JOIN (SELECT r1.random_id
FROM holes_map AS r1
JOIN (SELECT (RAND() *
(SELECT MAX(row_id)
FROM holes_map)) AS row_id)
AS r2
WHERE r1.row_id >= r2.row_id
ORDER BY r1.row_id ASC
LIMIT 1) as rows ON (id = random_id);
After 1000 fetches we see a equal distribution again:
> select * from holes;
+----+----------------------------------+----------+
| id | name | accesses |
+----+----------------------------------+----------+
| 1 | d12b2551c6cb7d7a64e40221569a8571 | 222 |
| 2 | f82ad6f29c9a680d7873d1bef822e3e9 | 187 |
| 4 | 9da1ed7dbbdcc6ec90d6cb139521f14a | 195 |
| 8 | 677a196206d93cdf18c3744905b94f73 | 207 |
| 16 | b7556d8ed40587a33dc5c449ae0345aa | 189 |
+----+----------------------------------+----------+
If you want to get more than one row returned, you can:
Now let's see what happends to our performance. We have 3 different queries for solving our problems.
Q1 is expected to cost N * log2(N), Q2 and Q3 are nearly constant.
The get real values we filled the table with N rows ( one thousand to one million) and executed each query 1000 times.
100 1.000 10.000 100.000 1.000.000
Q1 0:00.718s 0:02.092s 0:18.684s 2:59.081s 58:20.000s
Q2 0:00.519s 0:00.607s 0:00.614s 0:00.628s 0:00.637s
Q3 0:00.570s 0:00.607s 0:00.614s 0:00.628s 0:00.637s
As you can see the plain ORDER BY RAND() is already behind the optimized query at only 100 rows in the table.
A more detailed analysis of those queries is at analyzing-complex-queries.
Submitted by gouki on 2009, January 11, 10:15 PM
原文作者:yizhu2000
链接:http://www.phpv.net/html/1663.html
本人作为一位web工程师,着眼最多之处莫过于性能与架构,本次幸得参与sd2.0大会,得以与同行广泛交流,于此二方面,有些架构设计的心得,不敢独享,与众友分享,本文是这次参会与众同撩交流的心得.
架构设计的几个心得:
一,不要过设计:never over design
这是一个常常被提及的话题,但是只要想想你的架构里有多少功能是根本没有用到,或者最后废弃的,就能明白其重要性了,初涉架构设计,往往倾向于设计大而化 一的架构,希望设计出具有无比扩展性,能适应一切需求的增加架构,web开发领域是个非常动态的过程,我们很难预测下个星期的变化,而又需要对变化做出最 快最有效的响应。。
ebay的工程师说过,他们的架构设计从来都不能满足系统的增长,所以他们的系统永远都在推翻重做。请注意,不是ebay架构师的能力有问题,他们 设计的架构总是建立旧版本的瓶颈上,希望通过新的架构带来突破,然而新架构带来的突破总是在很短的时间内就被新增需求淹没,于是他们不得不又使用新的架构
web开发,是个非常敏捷的过程,变化随时都在产生,用户需求千变万化,许多方面偶然性非常高,较之软件开发,希望用一个架构规划以后的所有设计,是不现实的
二,web架构生命周期:web architecture‘s life cycle
既然要杜绝过设计,又要保证一定的前瞻性,那么怎么才能找到其中的平衡呢?希望下面的web架构生命周期能够帮到你

所设计的架构需要在1-10倍的增长下,通过简单的增加硬件容量就能够胜任,而在5-10倍的增长期间,请着手下一个版本的架构设计,使之能承受下一个10倍间的增长
google之所以能够称霸,不完全是因为搜索技术和排序技术有多先进,其实包括baidu和yahoo,所使用的技术现在也已经大同小异,然而,google能在一个月内通过增加上万台服务器来达到足够系统容量的能力确是很难被复制的
三,缓存:Cache
空间换取时间,缓存永远计算机设计的重中之重,从cpu到io,到处都可以看到缓存的身影,web架构设计重,缓存设计必不可少,关于怎样设计合理的缓 存,jbosscache的创始人,淘宝的创始人是这样说的:其实设计web缓存和企业级缓存是非常不同的,企业级缓存偏重于逻辑,而web缓存,简单快 速为好。。
缓存带来的问题是什么?是程序的复杂度上升,因为数据散布在多个进程,所以同步就是一个麻烦的问题,加上集群,复杂度会进一步提高,在实际运用中,采用怎样的同步策略常常需要和业务绑定
老钱为搜狐设计的帖子设计了链表缓存,这样既可以满足灵活插入的需要,又能够快速阅读,而其他一些大型社区也经常采用类此的结构来优化帖子列表,memcache也是一个常常用到的工具
链接:钱宏武谈架构设计视频 http://211.100.26.82/CSDN_Live/140/qhw.flv
Cache的常用的策略是:让数据在内存中,而不是在比较耗时的磁盘上。从这个角度讲,mysql提供的heap引擎(存储方式)也是一个值得思考的方法,这种存储方法可以把数据存储在内存中,并且保留sql强大的查询能力,是不是一举两得呢?
我们这里只说到了读缓存,其实还有一种写缓存,在以内容为主的社区里比较少用到,因为这样的社区最主要需要解决的问题是读问题,但是在处理能力低于 请求能力时,或者单个希望请求先被缓存形成块,然后批量处理时,写缓存就出现了,在交互性很强的社区设计里我们很容易找到这样的缓存
四,核心模块一定要自己开发:DIY your core module
这点我们是深有体会,钱宏武和云风也都有谈到,我们经常倾向于使用一些开源模块,如果不涉及核心模块,确实是可以的,如果涉及,那么就要小心了,因为当访 问量达到一定的程度,这些模块往往都有这样那样的问题,当然我们可以把问题归结为对开源的模块不熟悉,但是不管怎样,核心出现问题的时候,不能完全掌握其 代码是非常可怕的
五,合理选择数据存储方式:reasonable data storage
我们一定要使用数据库吗,不一定,雷鸣告诉我们搜索不一定需要数据库,云风告诉我们,游戏不一定需要数据库,那么什么时候我们才需要数据库呢,为什么不干脆用文件来代替他呢?
首先我们需要先承认,数据库也是对文件进行操作。我们需要数据库,主要是使用下面这几个功能,一个是数据存储,一个是数据检索,在关系数据库中,我们其实非常在乎数据库的复杂搜索的能力,看看一个统计用的tsql就知道了(不用仔细读,扫一眼就可以了)
select c.Class_name,d.Class_name_2,a.Creativity_Title,b.User_name,(select count(Id) from review where Reviewid=a.Id) as countNum from Creativity as a,User_info as b,class as c,class2 as d where a.user_id=b.id and a.Creativity_Class=c.Id and a.Creativity_Class_2=d.Id
select a.Id,max(c.Class_name),(max(d.Class_name_2),max(a.Creativity_Title),max(b.User_name),count(e.Id) as countNum from Creativity as a,User_info as b,class as c,class2 as d,review as e where a.user_id=b.id and a.Creativity_Class=c.Id and a.Creativity_Class_2=d.Id and a.Id=e.Reviewid group by a.Id ..............................................
我们可以看出需要数据库关联,排序的能力,这个能力在某些情况下非常重要,但是如果你的网站的常规操作,全是这样复杂的逻辑,那效率一定是非常低 的,所以我们常常在数据库里加入许多冗余字段,来减小简单查询时关联等操作带来的压力,我们看看下面这张图,可以看到数据库的设计重心,和网站(指内容型 社区)需要面对的问题实际是有一些偏差的
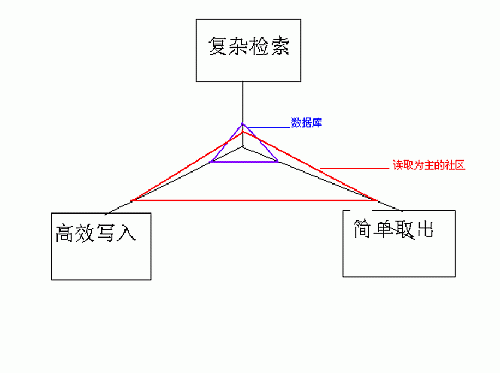
同样其他一些软件产品也遇到同样的问题所以具我了解,有许多特殊的运用都有自己设计的特殊数据存储结构与方法,比如有的大型服务程序采取树形数据存储结构,lucene使用文件来存储索引和文件
从另外一个角度上看,使用数据库,意味着数据和表现是完全分离的(这当然是经典的设计思路),也就是说当需要展示数据时,不得不需要一个转换的过 程,也可以说是绑定的过程,当网站具备一定规模的时候,数据库往往成为效率的瓶颈,所以许多网站也采用直接书写静态文件的方法来避免读取操作时的绑定
这并不是说我们从今天起就可以把我们亲爱的数据库打入冷宫,而是我们在设计数据的持久化时,需要根据实际情况来选择存储方式,而数据库不过是其中一个选项
六,搞清楚谁是最重要的人:who's the most important guy
在用例需求分析的时候常常讲到涉众,就是和你的设计息息相关的人,在web中我们一定以为最重要的涉众莫过于用户了。,在一个传统的互动社 区开发中,最重要的东西是内容,用户产生内容,所以用户就是上帝,至于内容挑选工具,不就是给坐我后面三排的妹妹们用的吗?凑或行了,实在有问题我就在数 据里手动帮你加得了。。这大概是眼下许多小型甚至中型网站技术人员的普遍想法。钱宏武在他的讲座里谈到了这个问题:实际上网站每天产生的内容非常的多,普 通人是不可能看完的,而编辑负责把精华的内容推荐到首页上,所以很多用户读到的内容其实都依赖于编辑的推荐,所以设计让编辑工作方便的工具也是非常重要, 有时甚至是最重要的。
七,不要执着于文档:don't be crazy about document
web开发的文档重要吗?什么文档最重要?我的看法是web开发中交流>文档,
现在大的软件公司比较流行的做法是:
注重产品设计文档,在这种方法里,产品文档非常详尽,并且没有歧义,开发人员基于设计文档开发,测试人员基于设计文档制定测试方案,任何新人都可以通过阅读产品设计文档来了解项目的概况
而web项目从概念到实现的时间是非常短的,而且越短越好,并且由于变化迅速,要想写出完整的产品和需求文档是几乎不可能的,大多数情况是等你写出 完备的文档,项目早就是另外一个样子,但是没有文档的问题是,如果团队发生变化,添加新成员怎样才能了解软件的结构和概念呢,一种是每个人都了解软件的整 个结构,除非你的团队整体消失,否则任何一个人都能够担当培养新人的责任,这种face2face交流比文档有效率很多。
于是就有了前office开发者,现任yahoo中国某产品开发负责人的刘振飞所感觉到的落差,他说,我们的项目是吵出来的,我听完会心一笑
八,团队:team
不要专家团队,而要外科手术式的团队,你的团队里一定要有清道夫,需要有弓箭手,让他们和项目一起成长,才是项目负责人的最大成就
总结:
架构是一种权衡

web开发的特点是是:没有太复杂的技术难点,一切在于迅速的把握需求,其实这正式敏捷开发的要旨所在,一切都可以非常快速的建立,非常快速的重构,我们的开发工具,底层库和框架,包括搜索引擎和web文档提供的帮助,都提我们供给了敏捷的能力。
此外,相应的,最有效率的交流方式必须留给web开发,那就是face2face(面对面),不要太担心你的设计不能被完备的文档所保留下来,他们会以交流,代码和小卡片的方式保存下来
人的因素会更加重要,无论是对用户的需求,还是开发人员的素质。
Submitted by gouki on 2009, January 8, 9:22 PM
从TP1.5开始,对于其他的模版引擎有了原生支持(不再是以前那种插件机制了)。
本文以使用smarty模版为例作点简单介绍,其他的,可以参考一下View.class.php中的fetch方法可知。
TP的SVN中已经含有smarty模版库,因此当你要使用的时候,只需要在项目的config.php里作一点简单的配置:
从2009-01-07下午的SVN版本里,流年为又增加了一个TMPL_ENGINE_CONFIG这个数组,即:
备注:如果按照我这样的写法,请到cache目录里手动创建tplCompile和tplCache两个目录,否则程序会报错。
报错信息大致为:
如果出现这样的报错信息,请先检查这两个目录是否存在
在项目开发的时候,caching 最好设为false,否则你根本看不到效果。
如此设定完毕后,你就可以直接在项目中使用了,下面以Index模块的index方法进行举例:在IndexAction.class.php的index的方法里
然后到模版里:
就可以看到输出了。不过,这里需要注意的是,如果你$this->display()没有指定文件名,那么默认的模版文件就是default/Index/index.html,这点和原先使用TP默认的模版引擎没有什么区别。
出现问题最大的应该是在include方法里,include的使用方法是:{include file="Public/header.html"},就象我前面所说,smarty的模版路径只指到了tpl目录,但实际上,我们是在默认的default目录下操作,因此正确的写法应该是{include file="default/Public/header.html"}
如果我们写的程序要对应多模版,那么,上面那种直接写死default的方法是不行的,还好,TP为我们留了一个常量:TEMPLATE_NAME,于是我们的写法就可以是现在这样:
现在试一下,是否公用目录里的header.html被加载了?
最后再报一个warning。如果是在WINDOWS下面开发并且开启了DEBUG_MODE,那么你在读取模版的时候,页面的Trace信息里,偶尔会出现一个注意:
这些信息,可以被忽略掉。模版文件还是会正常的生成和编译的。它只会在第一次生成模版编译文件的时候出现
| « 2025年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | ||
 [649] [9] [38] [14] [2] [12] [307] [65] [284] [227] [161] [235] [9] [25] [12] [966] [92]
[649] [9] [38] [14] [2] [12] [307] [65] [284] [227] [161] [235] [9] [25] [12] [966] [92]