count_chars表面上是計算char出現的次數,但事實上對中文支持明顯是不好的。
所以,它還有另外一個作用,即count_chars($str,4);
看好第二個參數哦。當這個參數是4時,會返回所有的会用作计算的字符串:
XML/HTML代码
- ������������������ !"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`defghijklmnopqrstuvwxyz{|}~€‚ƒ„…†‡ˆ‰Š‹ŒŽ‘’“”•–—˜™šœžŸ ¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¹»¼¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãæçèéêëìíîïðñòóôõö÷øùúûüýþÿ
嗯,因此这也算是一个小技巧啦。
最近,紫狐浏览器可是很火呀,于是我也想感受一下,但是却发现我打开非死不可的时候,仍然是该页无法显示。怎么办?难道紫狐是骗人的?
理论上不应该呀,而且很多人也确实是可以访问的呀。于是 上网找了一些资料,找到的第一篇是:紫狐浏览器Windows Vista && Win7 帮助手册,是啊,我在win7下面当然是看这个喽。。。
于是,我复制了本文到我博客上。(最终我操作成功了,后面再说)
原文如下:(紫狐官方站打不开了。。可能是因为我不在教育网吧)
清华大学最近推出了一款紫狐浏览器,专门供IPv6上网使用。 紫狐浏览器是清华大学互联网服务与系统研究中心与Mozilla中国合作研发的一款基于Firefox内核的面向清华校内的浏览器。以下我们介绍紫狐浏览器在Windows Vista && Win7操作系统下的使用方法:
1, 查看网络连接是否正常。若能访问普通网页,则继续往下看;
2, 查看 IPv6 服务是否启动。步骤为“ 开始菜单 ” -> “ 控制面板 ” -> “ 系统和安全 ” -> “ 管理工具 ” -> “ 服务 ”中,找到 IP Helper 服务 , 启动运行 并 将启动类型设置为“自动” ,这样即使重启之后也能自启动,保证服务正常运行;
3, 设置Teredo来获取IPv6地址。
(1) 在 ” 开始 ”->” 运行 ” 中输入 cmd 打开 Windows 命令行。在命令行中输入 ipconfig /all ,会出现若干网络配置信息,找到 Tunnel adpter (隧道适配器) Teredo Tunneling Pseudo-Interface , 查看它是否有正确的 IPv6 地址 ( 以 2001:0 为前缀的 ipv6 地址 ),若有说明正确;
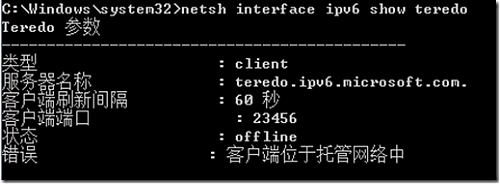
(2) 在 ” 开始 ”->” 运行 ” 中输入 cmd 打开 Windows 命令行。 在命令行中输入 netsh int teredo show state ,出现以下 Teredo 参数 :
若“ 状态 ”为 dormant / qualified ,则表示已连接服务器并获得 IPv6 地址。若不是此种情况,可能是类似如下图的状况,
若“ 状态 ”为 offline ,同时提示错误“无法访问主服务器地址”或其他错误,则表示未连接上服务器。 在命令行状态下输入 netsh int ipv6 set teredo client teredo.ipv6.microsoft.com ,此命令用于向 Teredo 服务器请求 IPv6 地址 。 之后需要稍等一阵 ,因为在请求连接 Teredo 服务器,此时输入 netsh int ipv6 show teredo 出现如下图:
即 “ 状态 ”为 probe ,表示正在请求中 。 10 秒之后(或稍长些), 输入 netsh int ipv6 show teredo 查看 Teredo 参数 ,若状态为 qualified ,则 OK ,用 ipconfig /all 查看 Teredo 适配器是否获得以 2001:0 为前缀的 IPv6 地址。若状态仍未 offline ,需要再次尝试连接服务器,即输入之前的命令。 因不能确保一次就能连上,可能出现需要多次连接的情况 。
(3) 若以上操作之后仍不能获得以 2001:0 为前缀的 IPv6 地址,或在 ipconfig /all 命令后找不到 Microsoft Teredo Tunneling Adapter ,则需要检查是否系统禁用或卸载了 Teredo 适配器。“开始菜单” -> “控制面板” -> “管理工具” -> “计算机管理”,打开“计算机管理”后,在主界面左框中选择“系统工具”下的“设备管理器”,然后右框选择“网络适配器”,并在工具栏 -> “查看” -> “显示隐藏的设备”,看看是否有 Microsoft Tun Miniport Adapter 或 Microsoft Teredo Adapter ,右键查看其是否已启用;
(4) 有时可能不小心将 Teredo Adapter 卸载了,但又找不到如何重新安装。选中设备管理器工具栏 à 操作 à 添加过时硬件,进入“添加硬件向导”,下一步 à 搜索并自动安装硬件 ( 推荐 ) à 下一步 à 在“从以下列表,选择要安装的硬件类型”下的列表中,选择“网络适配器”,然后下一步 à 选择网络适配器,厂商选“ Microsoft ”,网络适配器选“ Microsoft Teredo Tunneling Adapter ” à 然后下一步,继续到底即可。
4, 如果系统中有多个在连接状态的网卡(包括虚拟网卡等),可尝试以下步骤:
(1) 首先设备管理器中禁用除 Internet 链接外的其他所有网卡。
(2) 然后再运行紫狐浏览器。
(3) 如果需要使用多网卡,请在紫狐浏览器能打开 ipv6 网站后再启用多网卡。
5, 若以上方法试过后仍不能连上,请与管理员联系, E-mail: admin-ciss@tsinghua.edu.cn
-----EOF----
注意,请注意。。。按照上述的内容可能仍然是打不开的,你会发现在ipconfig /all的时候还是没有2001开头的IPV6地址,原因是,你在 netsh int teredo show state时显示的状态为:客户端位于托管网络中,关于这个状态,据说google上的资料也不多,但主要是因为路由器的原因。好吧,如果显示“客户端位于托管网络”中,请看下文,文章来自:http://neolee.com/web/tedero-ipv6-internet-through-home-router/ ,或者点击Tedero穿家用路由器IPv6上网
最近一直想尝试通过IPv6上一些精彩、特别的网站,可家里是通过路由器上网的。网上大多数IPv6法必须通过直连的方式上网,对于路由器来说只能关闭DHCP、外网线插LAN口做交换机。
这点对于我家比较麻烦,毕竟和家里老人一会儿说上网只要开电脑、一会儿又变成还要点击宽带连接,对老人的接受能力是种“随残”。
而传说中的六飞也迟迟未能支持win7 X64。因此一直没能成功……
后来@felixonmars 给了我巨大提点,通过Teredo可以穿过路由器上网!醍醐灌顶!所以这两天老N潜心研究网上各类关于tedero上IPv6的文章。
可是捣鼓了半天,tedero通道状态永远如下:
ipconfig /all 中:
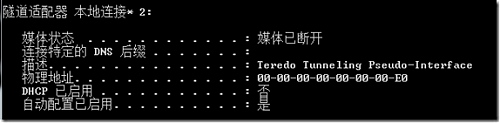
“客户端位于托管网络中”、teredo没有所谓的2001开头ipv6地址!!!
太恶心了!!!
Google+百度了我近3个小时(也许是我搜索能力问题),终于发现对于路由器用户来说还需要修改teredo的【类型】参数,内网用户类型不是client而是enterpriseclient。
If it says “Client is in a managed Network” it means teredo has detected that you are in a corperate environment. If that is the case you need to set the Teredo type to Enterprise client “Netsh int ter set state enterpriseclient”.
以上文字来自Microsoft的论坛。
因而问题解决了,在管理员权限的cmd窗口中输入:
Netsh int ter set state enterpriseclient
对于Windows XP,你可以使用这句命令:
netsh interface ipv6 set teredo enterpriseclient
然后我们再看看teredo状态:
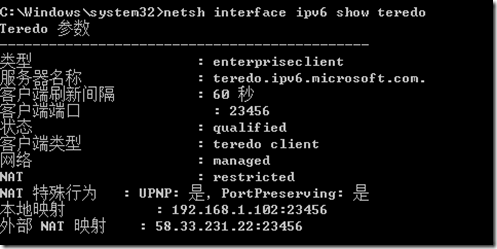
就这么简单,teredo就联通了!!
teredo对于内网用户上ipv6来说真是福音啊!
现在老N上youtube无需代理,完全不卡,哈哈哈哈哈!!!!
===备注====
1. 设置teredo请参见此文:开启 Teredo 通道, 提前感受 IPv6 (for 非教育网用户)【如何打开teredo,请看此文】
2. 一些ipv6的hosts,请看此文档。(请先越墙)
3. 客户端位于托管网络中=Client is in a managed Network ,如需搜索更多关于这点的内容,老N建议你搜英文的。。。。中文关于teredo这点的信息真的太少了。google中仅有几条,完全没有帮助。。。
4. 再来做个记录:如果teredo状态为dormant的话,你可以尝试关闭(或者打开=。=)系统防火墙试试看,dormant和防火墙有关……
---EOF---
OK,打开紫狐,我们已经可以上网了(我想,以后应该会有ipv6的firefox插件的吧。。。。而不应该自己转换。)
关于使用GUID和INT做主键,性能差异的文章历来很多,不过。大多都是从理论上来说明,这次难得看到某人用PC机做测试,所以贴上来看看。但我不贴全文,毕竟。。。大量的代码贴上来,也没有太大的意义 。所以仅贴上主体内容和测试结果,当然还会有一些用户的评论。。
原文网址为:http://www.cnblogs.com/jackhuclan/archive/2010/01/04/1639005.html
内容大致如下,【如想看全文,请使用上面的链接】
在数据库的设计中我们常常用Guid或int来做主键,根据所学的知识一直感觉int做主键效率要高,但没有做仔细的测试无法说明道理。碰巧今天在数据库的优化过程中,遇到此问题,于是做了一下测试。
测试环境:
台式电脑 Pentiun(R) 4 Cpu 3.06GHz
Win XP professional
1.5G DDR RAM
SQL Server 2005 个人版
测试过程:
首先创建测试数据库Test
1.创建Test_Guid表,创建Test_Int表
2.创建Test_Guid子表:Test_Guid_Detail和创建Test_Int子表:Test_Int_Detail,用来做连接查询
3、然后进行一些CRUD的操作【这是我写的,因为原文中写插入N行数据,删除N行数据之类的太复杂,也太多,简化为一句话了】
测试结果如下:
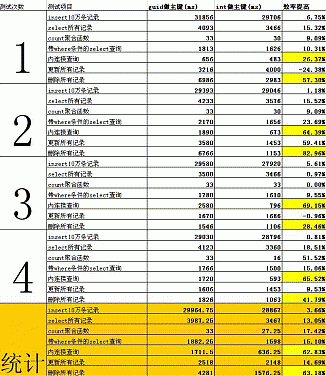
综上所述,使用int做主键比用guid做主键各中情况下效率均有提高,特别是在有连接查询和删除记录效率提升明显。
而且本人今日在guid做主键的数据查询中因为嵌套几个子查询结果屡屡出现查询超时。因此本人赞同用int做主键,不赞同guid做主键。
以上观点代表个人观点,欢迎大家各抒己见,说明guid和int各自做主键的优劣所在。
----EOF---
本来到这里就可以结束了,但有一个用户的评论还算不错:
徐少侠
- 首先
- 10万行不算大数据量
- 我测试插入操作的时候是1600万行。性能约有10-20%的差异
- 当然,10万行也能说明一些问题了
-
- 其次,请在所有的where和on条件中使用到的列身上增加一个索引
- 也就是说所有的外键都要有索引,非唯一索引
- 具体说,就是主表的TestId以及子表对应的外键列
-
- 然后再重新执行一下上述测试
- 主要对带where和inner join的测试表示疑问
-
- 最后,int在多数情况下一定比Guid快,这是不用怀疑的。
- 同时,查询优化主要靠索引,以及对索引树的优化以及查询顺序的安排
- 主键的数据类型一般只影响到插入操作的速度
- 对于查询操作的影响是比较小的
- 不至于出现50%左右的性能差异
更多的人认为GUID在做数据迁移的时候很方便,而如果使用INT则会有意料不到的问题。而GUID遇到的问题会少很多。。。
相对于以上的观点我还是比较认同的,但我认为性能相差这么大是有可能有以下的原因:
1、作者用的是PC机
2、操作系统是XP
3、sql server 是个人版【我没有试用服务器版性能如何,但我想,一定比个人版性能更优,当然这是猜测】
说归说,对于MYSQL来说,基本上还是只能使用INT做主键。毕竟MYSQL没有自带的生成GUID的方法【我不是指手动生成,我是说自动生成。。。UUID()函数是可以生成GUID的,但不能象INT那样自动插入,也没有办法设置default为UUID()方法】
这是cssrain站长翻译的一篇文章,事实上,在PHP中,已经不太建议使用switch-case了。
特别是在面向OO的代码中,你几乎也看不到这样的代码出现
不是说这个方式不好。而是,它的可扩展性不强。所以在大多数情况下,都放弃采用这种方式。
以下是翻译内容,来源于:http://www.cssrain.cn/article.asp?id=1384:
我很年轻,还没有做过很长的编程。所以我对使用switch-case 语法没有什么很深刻的印象,至少在我的记忆中是这样。或许你认为这是一件坏事情。你甚至会怀疑我为什么不使用它们。我真的不知道为什么,似乎我天生就不喜欢使用它,如下所示:
JavaScript代码
- switch (something) {
- case 1:
- doX();
- break;
- case 2:
- doY();
- break;
- case 3:
- doN();
- break;
-
- }
显然,虚构此代码的作者不够了解使用其他JavaScript方法来构建此功能。其实有很多种方式更适合这种情况,而不是一个丑陋的switch. 有许多许多更轻松,更优雅的方式来实现这种功能。
switch-case组合肯定是非常有用的,当你有一个变量并且依靠它的值的不同来做不同的事情。使用多个if-else不太恰当,所以人们通常使用switch-case来代替多个if-else.我敢肯定你也是.
上面的例子依赖于 something 判断 ,然后根据条件运行doX , doY或doN 。在JavaScript中,同样的逻辑可以表示一个简单的查找表的形式————对象,如下所示:
JavaScript代码
- var cases = {
- 1: doX,
- 2: doY,
- 3: doN
- };
- if (cases[something]) {
- cases[something]();
- }
这不仅简洁,而且也可以重复使用和修改条件。所有条件都是对象的一部分,因此,如果您需要改变某些条件那就非常简单了。
所以,我想说的是:请不要使用switch-case,除非绝对必要的。 为什么? 因为有更好的替代品,比它更简单!
关于“ switch-case”的语法,请浏览:http://en.wikipedia.org/wiki/Switch_statement
如果想阅读原文,请点击这里:http://james.padolsey.com/javascript/how-to-avoid-switch-case-syndrome/
提示:译文跟原文有出入,请看原文。
原文来自:http://www.mikespook.com/index.php/archives/352
不过,我感兴趣的也就两个:
1、延迟绑定
2、匿名函数
原文如下:
6月19日发布的PHP 5.3 RC4 同之前的RC版本并无很大出入,仅仅是修复bug和稳定性的改进。
新的一些特性,大家都讨论过了。不过我觉得还是有必要再罗嗦一下。
关于命名空间
namespaces 多少人期待了多少年,时间长到我以为 php 不会有命名空间了。突然有消息说 5.3 含有 namespaces,并且使用很有争议的“\”作为分隔符号。
其实,没有命名空间,大家都想出了各种各样的替代方法。比如经典的“_”对应子目录之类的。在大家屡试不爽的时候,突然在一个小版本号升级中引入了 namespaces,实在让人摸不着头脑。不过看一下从 php4 -> php5 的升级周期,或许真正的 namespaces 只有在 php6 的时候才能稳定和成熟。php 5.3 的namespaces 或许只是 perview 而已。
这些大家应该都是知道的,不多说了。总之 namespaces 很好用,又总之,真正用到 namespaces 的那天还很遥远。
关于推迟静态绑定
叫这个名字,不一定准确,我只是隐约记得 Late Static Bindings 是这个叫法吧。这个东西能带来一个好处,就是代码的动态性更强,越晚的绑定,越低的耦合。我遇到过这种情况,在项目中有一个类要重写其中的一些方法,但是 由于过早的绑定机制,导致不重写其中的大部分代码就不可能完成类似的任务。最后的结果是出现了种种丑陋的,难以维护的代码编写方式来实现这个本不复杂的问 题。
例如在php网站上提供的这个代码中:
class A {
public static function who() {
echo __CLASS__;
}
public static function test() {
self::who();
}
}
class B extends A {
public static function who() {
echo __CLASS__;
}
}
B::test();
在之前的php版本中,为了让 B::test() 输出 B 这个结果,唯一的方法是在 B 类中重写 test 方法(这个时候粘贴-复制-修改是好办法)。如果这样的方法有很多,那么工作量还是很大的,特别是在维护的时候……至少我是经常会忘记有哪些类似的代码需 要修改。
有了 Last Static Bindings:
class A {
public static function who() {
echo __CLASS__;
}
public static function test() {
static::who(); // Here comes Late Static Bindings
}
}
class B extends A {
public static function who() {
echo __CLASS__;
}
}
B::test();
如我所愿,现在的输出是 B 了,使用 static 关键字,让 who 方法的调用延迟到最后才绑定到真正的调用上。这样,就可以让代码变得简介并且容易理解。
关于匿名函数
匿名函数,也就是 Anonymous functions 其实并不是个完全陌生的家伙。create_function 这个函数已经给无数的程序员带来了甜蜜的感觉。只是 create_function 使用起来一点也不友好,同时字符串化的功能代码混乱难读。尤其是需要编写大段的匿名函数时,用 create_function 绝对是噩梦。现在真正意义上的匿名函数的出现,会给 php 带来什么影响呢?我觉得至少,在一些时髦的框架中会很快引入并应用这种特性,用这个语法糖去更简洁的实现一些功能。比如插件,再比如 DI……
$helloWorld = function ($name) {
return "Hello world! Hello {$name}";
};
很像 javascript?也许吧!
在不断的升级中 php 引入了很多新的功能,也提供了各种不同的体验。同时越来越庞大,学习也越来越困难。它,还能保持它的本色吗?
关于命名空间,我实在是不能忍受,反斜杠本来就是转义的,现在变成命名空间了。。。
可是有什么办法呢? .被用掉了,::也被用掉了
唉。。。
匿名函数的使用往往多用于插件中,避免与原来的函数(命名)产生冲突,这是最好的方法了。
延迟绑定,可以让PHP对于一些模式的使用变得更加优雅?或许这么说比较好吧


