今天下午借着sunx的帐号,想下载IOS7,结果发现卡的不得了。反而是在macx.cn上发现有人提供了下载,在百度的云盘上。并且google了一下怎么安装:打开itunes ,在按住option的情况下点击check update,然后选择下载包即可
安装很快,基本上15分钟不到就搞定了。
界面果然是象毛玻璃,并且在iphone4s上有点卡,真心卡的。很多时候操作起来都是一顿一顿的,
看了一下设置,拜托,不需要绑定这么多的帐号吧?
毛玻璃也太毛了。。
有点操作倒是挺舒服的,比如,手势向上的时候,可以打开控制面板。从顶部向下的时候,则仍然是以前的notifytation界面,不过这次将日历任务整合在一起了
原来的spotlight不见了,不再是单独一屏了,在主界面,手势向下则可以启动spotlight。
一切都看上去不错,只是在短短的下午五个小时左右,我自动重启了3次。有点纠结
本来也准备下载小牛安装的,但看到了网上有人说装了启动不了,所以我忍了。。等正式版吧
之所以要记录它,是因为为了这个手机,我跑了4次南京路。。。
4次啊,把我一年的份额都跑掉了
本来是乘着这次端午想出去玩的,结果手机的电源突然坏了,于是在假期的第二天去南京路看了下,谁知道苹果店说要预约,不能当场确认修理。
问了下怎么预约,说是要在网上进行预约,然后登录apple store,发现所有的预约都满了,再次问工作人员,怎么办?他说要不你每天早上8点来,到店门口登记,如果登记了预约,就可以约定时间进行维修了。
于是在端午节早上,我7点多从家里出发,到了7点55分左右到南京路,结果发现门口居然有20多号人在排队了。。赶紧冲上去排好
8点左右,有工作人员出来登记,到我的时候,已经8点1刻,预约时间约为10点50分,我一想,还要等3小时左右,我还不如回家呢,于是我花了半小时,又回了家。
然后10点40左右回到了苹果店,在咨询了一些问题后,告诉我说,这要换机器,下午5点拿。由于昨天已经逛 过南京路了,所以,乘这个机会去把车载导航又修了下(在闵行区,七宝老街附近)。前后折腾了2个小时,然后回家逛了下,又去移动厅换了个小卡(当年的卡是自己剪的)。
然后再出发去南京路,到的时候差不多5点,换了个机器。看上去像新的。但其实我知道是返修机,嗯,总比坏的好吧。
回到家,网上查了一下:
电话支持状态: 已过期 硬件保修到期: 2013-07-07 硬件保修状态: 未过期 生产工厂: 中国 生产日期: 2013-05-19 到 2013-05-25
我晶,不是说换机后保修3个月的嘛 。怎么还不如原来的机器?我原来的好歹还到7月17日 呢。
等会咨询一下他们。
不过总算是换了机器了。
记录下,如果有朋友在保修期内,是可以换的,记得去之前,在网上预约,否则就是排队了。
因为go的fmt.Printf支持的参数与c的printf(sprintf)不太一样,所以复制一下做个备份。
http://www.open-open.com/lib/view/open1352593106824.html
mport "fmt" 简介 Package fmt包含有格式化I/O函数,类似于C语言的printf和scanf。格式字符串的规则来源于C但更简单一些。 输出 格式: 一般: %v 基本格式的值。当输出结构体时,扩展标志(%+v)添加成员的名字。the value in a default format. when printing structs, the plus flag (%+v) adds field names %#v 值的Go语法表示。 %T 值的类型的Go语法表示。 %% 百分号。 布尔型: %t 值的true或false 整型: %b 二进制表示 %c 数值对应的Unicode编码字符 %d 十进制表示 %o 八进制表示 %q 单引号 %x 十六进制表示,使用a-f %X 十六进制表示,使用A-F %U Unicode格式: U+1234,等价于"U+%04X" 浮点数: %b 无小数部分、两位指数的科学计数法,和strconv.FormatFloat的'b'转换格式一致。举例:-123456p-78 %e 科学计数法,举例:-1234.456e+78 %E 科学计数法,举例:-1234.456E+78 %f 有小数部分,但无指数部分,举例:123.456 %g 根据实际情况采用%e或%f格式(以获得更简洁的输出) %G 根据实际情况采用%E或%f格式(以获得更简洁的输出) 字符串和byte切片类型: %s 直接输出字符串或者[]byte %q 双引号括起来的字符串 %x 每个字节用两字符十六进制数表示(使用小写a-f) %X 每个字节用两字符十六进制数表示(使用大写A-F) 指针: %p 0x开头的十六进制数表示 木有'u'标志。如果是无类型整数,自然会打印无类型格式。类似的,没有必要去区分操作数的大小(int8, int64)。 宽度和精度格式化控制是指的Unicode编码字符的数量(不同于C的printf,它的这两个因子指的是字节的数量。)两者均可以使用'*'号取代(任一个或两个都),此时它们的值将被紧接着的参数控制,这个操作数必须是整型。 对于数字,宽度设置总长度,精度设置小数部分长度。例如,格式%6.2f 输出123.45。 对于字符串,宽度是输出字符数目的最低数量,如果不足会用空格填充。精度是输出字符数目的最大数量,超过则会截断。 其它符号: + 总是输出数值的正负号;对%q(%+q)将保证纯ASCII码输出 - 用空格在右侧填充空缺而不是默认的左侧。 # 切换格式:在八进制前加0(%#o),十六进制前加0x(%#x)或0X(%#X);废除指针的0x(%#p); 对%q (%#q)如果可能的话输出一个无修饰的字符串; 对%U(%#U)如果对应数值是可打印字符输出该字符。 ' ' 对数字(% d)空格会留一个空格在数字前并忽略数字的正负号; 对切片和字符串(% x, % X)会以16进制输出。 0 用前置0代替空格填补空缺。 每一个类似Printf的函数,都会有一个同样的Print函数,此函数不需要format字符串,等价于对每一个参数设置为%v。另一个变体Println会在参数之间加上空格并在输出结束后换行。 如果参数是一个接口值,将使用内在的具体实现的值,而不是接口本身,%v参数不会被使用。如下: var i interface{} = 23 fmt.Printf("%v\n", i) 将输出23。 如果参数实现了Formatter接口,该接口可用来更好的控制格式化。 如果格式(标志对Println等是隐含的%v)是专用于字符串的(%s %q %v %x %X),还提供了如下两个规则: 1. 如果一个参数实现了error接口,Error方法会用来将目标转化为字符串,随后将被按给出的要求格式化。 2. 如果参数提供了String方法,这个方法将被用来将目标转换为字符串,然后将按给出的格式标志格式化。 为了避免有可能的递归循环,例如: type X string func (x X) String() string { return Sprintf("< %s > ", x) } 会在递归循环前转换值: func (x X) String() string { return Sprintf("< %s > ", string(x)) } 错误的格式: 如果提供了一个错误的格式标志,例如给一个字符串提供了%d标志,生成的字符串将包含对该问题的描述,如下面的例子: 错误或未知的格式标志: %!verb(type = value ) Printf("%d", hi): %!d(string = hi ) 太多参数: %!(EXTRA type = value ) Printf("hi", "guys"): hi%!(EXTRA string = guys ) 缺少参数: %!verb(MISSING) Printf("hi%d"): hi %!d(MISSING) 使用非整数提供宽度和精度: %!(BADWIDTH) or %!(BADPREC) Printf("%*s", 4.5, "hi"): %!(BADWIDTH)hi Printf("%.*s", 4.5, "hi"): %!(BADPREC)hi 所有的错误都使用"%!"起始,(紧随单字符的格式标志)以括号包围的错误描述结束。 输入 一系列类似的函数读取格式化的文本,生成值。Scan,Scanf和Scanln从os.Stdin读取;Fscan,Fscanf和Fscanln 从特定的io.Reader读取;Sscan,Sscanf和Sscanln 从字符串读取;Scanln,Fscanln和Sscanln在换行时结束读取,并要求数据连续出现;Scanf,Fscanf和Sscanf会读取一整行以匹配格式字符串;其他的函数将换行看着空格。 Scanf, Fscanf, and Sscanf根据格式字符串解析数据,类似于Printf。例如,%x将读取一个十六进制数,%v将读取值的默认表示。 格式行为类似于Printf,但有如下例外: %p没有提供 %T没有提供 %e %E %f %F %g %G是等价的,都可以读取任何浮点数或者复合数(非复数,指科学计数法表示的带指数的数) %s 和 %v字符串使用这两个格式读取时会因为空格而结束 不设格式或者使用%v读取整数时,如果前缀为0(八进制)或0x(十六进制),将按对应进制读取。 宽度在输入中被解释(%5s意思是最多从输入读取5个字符赋值给一个字符串),但输入系列函数没有解释精度的语法(木有%5.2f,只有%5f)。 输入系列函数中的格式字符串,所有非空的空白字符(除了换行符之外),无论在输入里还是格式字符串里,都等价于1个空白字符。格式字符串必须匹配输入的文本,如果不匹配将停止读取数据并返回函数已经赋值的参数的数量。 所有的scan系列函数,如果参数包含Scan方法(或者说实现了Scanner接口),该参数将使用该方法读取文本。另外,如果被填写的参数的数量少于提供的参数的数量,将返回一个错误。 所有要被输入的参数都应该是基础类型或者实现了Scanner接口的数据类型的指针。 注意:Fscan等函数可以从输入略过一些字符读取需要的字符并返回,这就意味着一个循环的读取程序可能会跳过输入的部分数据。当数据间没有空白时就会导致出现问题。如果读取这提供给Fscan系列函数ReadRune 方法,这个方法可以用来读取字符。如果读取者还提供了UnreadRune 方法,该方法将被用来保存字符以使成功的调用不会丢失数据。为了给一个没有这些功能的读取者添加这俩方法,使用bufio.NewReader。
这样就看起来方便多了,而且。速度也快。。。。
http://www.cnblogs.com/ztiandan/category/436475.html
http://www.dotcoo.com/?tag=golang
http://www.diandian.com/tag/golang
http://code.google.com/p/golang-china/
http://www.zhaokunyao.com/archives/category/go-lang
还有一些知名的和不知名的就不贴了。比如astaxie的GITHUB上的教程。大家都知道。。
司徒正美在看到老赵的博客鄙视IE6用户时,不甘寂寞,放出了一段残忍的代码,可以对IE6、7进行封杀处理。。
代码如下:
XML/HTML代码
<!doctype html > < html > < head > < meta charset = "utf-8" /> < meta content = "IE=8" http-equiv = "X-UA-Compatible" /> < meta name = "keywords" content = "IE6与IE7封杀器 by 司徒正美" /> < meta name = "description" content = "IE6与IE7封杀器 by 司徒正美" /> < script type = "text/javascript" > //使用setAttribute也行,值好像是固定,为1(读作"日",日得好!) document.createElement("li").value = 1 ; </ script > < title > IE6与IE7封杀器 by 司徒正美 </ title > </ head > < body > < h1 > 杀!杀!杀! </ h1 > < h2 > 不行请刷新页面(这是运行框的问题) </ h2 > </ body > </ html >
还有一段是可以关闭当前窗口的:
XML/HTML代码
window.opener = null ;window.open('','_self');window.close();
我的博客不能执行代码,如果你想测试,你可以到http://www.cnblogs.com/rubylouvre/archive/2010/05/18/1738370.html进行享受。
原文作者:yizhu2000
链接:http://www.phpv.net/html/1663.html
本人作为一位web工程师,着眼最多之处莫过于性能与架构,本次幸得参与sd2.0大会,得以与同行广泛交流,于此二方面,有些架构设计的心得,不敢独享,与众友分享,本文是这次参会与众同撩交流的心得.
架构设计的几个心得:
ebay的工程师说过,他们的架构设计从来都不能满足系统的增长,所以他们的系统永远都在推翻重做。请注意,不是ebay架构师的能力有问题,他们 设计的架构总是建立旧版本的瓶颈上,希望通过新的架构带来突破,然而新架构带来的突破总是在很短的时间内就被新增需求淹没,于是他们不得不又使用新的架构
二,web架构生命周期:web architecture‘s life cycle
所设计的架构需要在1-10倍的增长下,通过简单的增加硬件容量就能够胜任,而在5-10倍的增长期间,请着手下一个版本的架构设计,使之能承受下一个10倍间的增长
google之所以能够称霸,不完全是因为搜索技术和排序技术有多先进,其实包括baidu和yahoo,所使用的技术现在也已经大同小异,然而,google能在一个月内通过增加上万台服务器来达到足够系统容量的能力确是很难被复制的
缓存带来的问题是什么?是程序的复杂度上升,因为数据散布在多个进程,所以同步就是一个麻烦的问题,加上集群,复杂度会进一步提高,在实际运用中,采用怎样的同步策略常常需要和业务绑定
老钱为搜狐设计的帖子设计了链表缓存,这样既可以满足灵活插入的需要,又能够快速阅读,而其他一些大型社区也经常采用类此的结构来优化帖子列表,memcache也是一个常常用到的工具
链接:钱宏武谈架构设计视频 http://211.100.26.82/CSDN_Live/140/qhw.flv
Cache的常用的策略是:让数据在内存中,而不是在比较耗时的磁盘上。从这个角度讲,mysql提供的heap引擎(存储方式)也是一个值得思考的方法,这种存储方法可以把数据存储在内存中,并且保留sql强大的查询能力,是不是一举两得呢?
我们这里只说到了读缓存,其实还有一种写缓存,在以内容为主的社区里比较少用到,因为这样的社区最主要需要解决的问题是读问题,但是在处理能力低于 请求能力时,或者单个希望请求先被缓存形成块,然后批量处理时,写缓存就出现了,在交互性很强的社区设计里我们很容易找到这样的缓存
四,核心模块一定要自己开发:DIY your core module
select c.Class_name,d.Class_name_2,a.Creativity_Title,b.User_name,(select count(Id) from review where Reviewid=a.Id) as countNum from Creativity as a,User_info as b,class as c,class2 as d where a.user_id=b.id and a.Creativity_Class=c.Id and a.Creativity_Class_2=d.Id
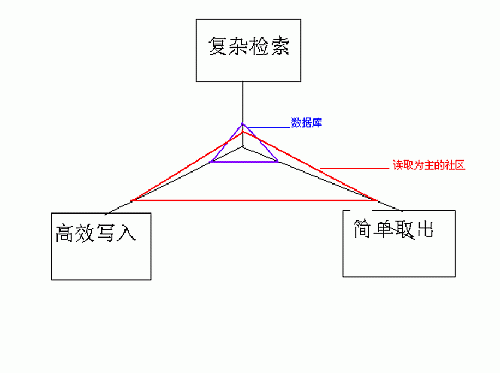
我们可以看出需要数据库关联,排序的能力,这个能力在某些情况下非常重要,但是如果你的网站的常规操作,全是这样复杂的逻辑,那效率一定是非常低 的,所以我们常常在数据库里加入许多冗余字段,来减小简单查询时关联等操作带来的压力,我们看看下面这张图,可以看到数据库的设计重心,和网站(指内容型 社区)需要面对的问题实际是有一些偏差的
同样其他一些软件产品也遇到同样的问题所以具我了解,有许多特殊的运用都有自己设计的特殊数据存储结构与方法,比如有的大型服务程序采取树形数据存储结构,lucene使用文件来存储索引和文件
从另外一个角度上看,使用数据库,意味着数据和表现是完全分离的(这当然是经典的设计思路),也就是说当需要展示数据时,不得不需要一个转换的过 程,也可以说是绑定的过程,当网站具备一定规模的时候,数据库往往成为效率的瓶颈,所以许多网站也采用直接书写静态文件的方法来避免读取操作时的绑定
这并不是说我们从今天起就可以把我们亲爱的数据库打入冷宫,而是我们在设计数据的持久化时,需要根据实际情况来选择存储方式,而数据库不过是其中一个选项
> 文档,
现在大的软件公司比较流行的做法是:
而web项目从概念到实现的时间是非常短的,而且越短越好,并且由于变化迅速,要想写出完整的产品和需求文档是几乎不可能的,大多数情况是等你写出 完备的文档,项目早就是另外一个样子,但是没有文档的问题是,如果团队发生变化,添加新成员怎样才能了解软件的结构和概念呢,一种是每个人都了解软件的整 个结构,除非你的团队整体消失,否则任何一个人都能够担当培养新人的责任,这种face2face交流比文档有效率很多。
于是就有了前office开发者,现任yahoo中国某产品开发负责人的刘振飞所感觉到的落差,他说,我们的项目是吵出来的 ,我听完会心一笑
总结:
架构是一种权衡
web开发的特点是是:没有太复杂的技术难点,一切在于迅速的把握需求,其实这正式敏捷开发的要旨所在,一切都可以非常快速的建立,非常快速的重构,我们的开发工具,底层库和框架,包括搜索引擎和web文档提供的帮助,都提我们供给了敏捷的能力。
此外,相应的,最有效率的交流方式必须留给web开发,那就是face2face(面对面),不要太担心你的设计不能被完备的文档所保留下来,他们会以交流,代码和小卡片的方式保存下来
人的因素会更加重要,无论是对用户的需求,还是开发人员的素质。