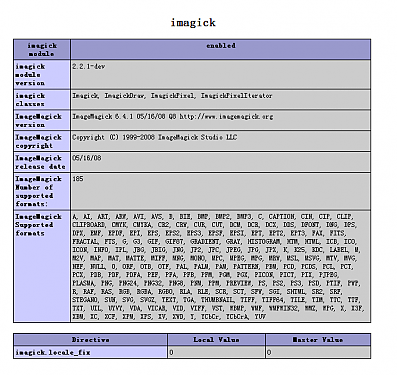
Imagick的DLL在windows上本来无法装上,前面一篇博客里介绍说团队好友hihiyou帮忙找了一个DLL,可以用在PHP 5.2.X上面的,今天一大早COPY到服务器上,并扩展出来。。
看图说话,OH YEAH。可惜。。。sablog不支持Imagick,它还是用GD的,不知道新版本会不会采用。
好象小图看不太清楚。还是点击一下看大图吧。。。

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
Submitted by gouki on 2008, September 24, 9:42 AM. PHP
Imagick的DLL在windows上本来无法装上,前面一篇博客里介绍说团队好友hihiyou帮忙找了一个DLL,可以用在PHP 5.2.X上面的,今天一大早COPY到服务器上,并扩展出来。。
看图说话,OH YEAH。可惜。。。sablog不支持Imagick,它还是用GD的,不知道新版本会不会采用。
好象小图看不太清楚。还是点击一下看大图吧。。。
很实用,我收下了,谢谢喽
Post by vetements on 2009, October 19, 4:26 PM  #1
#1
Post by gouki on 2008, December 19, 9:48 AM #2
我认为,mysql>4.1 and <5.02,varchar(n) 存储255个utf8码汉字是没有问题的.
Post by 单单 on 2008, December 18, 10:52 PM #3
| « 2026年07月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | |
[669] [0] [9] [227] [0] [92] [307] [65] [5] [286] [0] [236] [9] [27] [14] [982] [161]