小家伙今天理了个小光头,不过还不算是太光,外婆不让。唉。胎毛还是留了点在头上。
上张照片。。。

 膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
膘叔的简单人生 , 腾讯云RDS购买 | 超便宜的Vultr , 免费部署 N8N 的 Zeabur
注册 | 登陆
Submitted by gouki on 2008, October 7, 11:46 AM. Scala & Ruby
小家伙今天理了个小光头,不过还不算是太光,外婆不让。唉。胎毛还是留了点在头上。
上张照片。。。
图片附件(缩略图):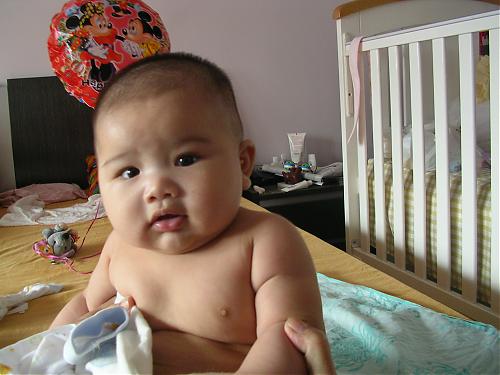
| « 2026年06月 » | ||||||
| 日 | 一 | 二 | 三 | 四 | 五 | 六 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | ||||
[666] [9] [38] [14] [2] [12] [307] [65] [289] [229] [161] [236] [9] [27] [14] [981] [92]