浏览模式: 标准 | 列表Tag:javascript
Submitted by gouki on 2010, April 27, 10:48 PM
本文来自PHP5研究室,里面用【】包含的内容是我的个人见解,并非一定就是正确,如果有不同意见,或者忽略,或者请给我点建议。
原文地址是http://www.phpv.net/html/1710.html
在我们公司ChinaNetCloud,见 过多种不同类型的网站和系统,有好也有差。其中有些系统拥有良好的服务器/网络架构,并且进行了合理的调整和监控 ;然而一般的系统都会有安全和性能上的问题,不能良好运行,也无法变得更流行。
在中国,开源的LAMP栈是最流行的网络架构,它使用PHP开发,运行在Apache服务器上,以MySQL作为数据库,所有这些都运行在Linux上。它是个可靠的平台,运行良好,是现在全球最流行的Internet系统架构。然而,我们很难对其规模进行正确的扩展并保持安全性,因为每个应用层都有其自身的问题、缺陷和最佳实践。我们的工作就是帮助企业用最低的操作成本来创建并运行高性能的、可伸缩的、安全的系统,因此对于这类问题我们有很丰富的经验。
当前的实际情况是,很多网站都是由开发人员快速而廉价地创建【说实话还真没有办法,上面催下面逼,还能怎么做?】,通常没有任何IT人员或者经理,只是由程序员来管理系统。造成的结果是,虽然花费很低的成本网站就可以开始运行,但是当拥有大量用户、需要扩展规模的时候,通常就会面临真正的问题。毕竟,中国拥有三亿八千万的Internet用户,如果其中的0.01%访问这个站点,就很容易引发25 万~50万的页面访问量。这些问题在各个级别上都会产生,下面总结的规则是对最一般的问题进行概述,并且说明为什么这些规则如此重要,以及最好采用什么方法来修正它们。遵循这些建议的站点会提高它的可伸缩性、安全性以及操作上的稳定性。
1、使用合适的会话管理
第一个想到的扩展系统的方法就是添加更多硬件。例如,使用两台服务器而不是一台。这听着合理,但会产生潜在问题:会话管理。这对Java程序来说是很严重的问题,在PHP中也会产生可延展性问题, 对于数据库的负载尤其如此。
会话被定义为单独的最终用户登录或者连接一段时间,其中通常会包含多个TCP/IP的HTTP连接、几个Web页面,通常还包括几十个甚至上百个页面元素,如框架、菜单、Ajax更新等。所有这些 HTTP请求都需要知道用户是谁,才能满足安全的要求,并向用户传送适当的内容,因为这些都是会话的组成部分。通常每个会话都会包括相互关联的会话数据,如用户名、用户ID、历史、购物车、统计资料等等信息。
问题在于,在有两台Web服务器和多个HTTP连接的情况下,用户流量会在两台服务器之间分配和移动,服务器很难知道用户是谁,并对所有数据进行跟踪,因为每个页面或者页面的组成部分都可能来自不同的服务器。在PHP中,通常是这样解决的,在第一次连接或登录的时候就创建一个会话ID并将其放在Cookie中,然后这个Cookie会和每个 HTTP请求一起发送。
这样做带来一个问题,接下来每段PHP脚本都需要基于ID来查找会话数据。由于PHP无法在执行过程之间保持状态(这与Java不同),这个会话数据需要存储在某个地方,通常是在数据库中。但是,如果复杂的页面需要在每个页面载入过程中对其进行十次查找(这是经常要做的),那就意味着每个页面都要执行10次SQL查询,这会导致数据库上很大的负载。
在前面所举的中国 Internet用户 0.01%的例子中,可能很容易在每秒内仅仅为了管理会话就生成上百个查询。解决方法是一直使用位于Cookie中的会话ID,并且使用像 Memcached之类的服务来缓存会话数据以获得高性能。
还要注意其中存在安全性的问题,因为黑客可以伪造另一个用户的会话ID,这是很容易找到或看到的,特别是在公用的Wi-Fi中。解决方法是对会话ID进行恰当的加密或者签名,并将其与时间区间、 IP地址以及其他关键信息 像浏览器或者其他细节相绑定。在Internet上有很多不错的关于良好的会话管理的例子,你可以根据需要找到最适合的。
2、总是要考虑安全性
尽管编写像防止SQL注入和登录安全之类的代码涉及很多安全问题,但不幸的是,几乎没有人考虑过安全性,而那些考虑到的人也没有对其进行很好地理解。而本文要关注的是操作性的系统安全。对于这类安全,我们的焦点集中在三个安全领域:防火墙、运行的用户以及文件访问权限。
除了配置专门的硬件防火墙(像Cisco的ASA)之外,所有服务器都还应该运行像Iptables之类的防火墙,它会保护服务器免受其他威胁和攻击。这些威胁和攻击可能来自公共的 Internet、其他服务器或本地服务器,也包括使用VPN或者SSH通道的开发和操作人员。我们仅对指定的IP开放确实需要的端口。Iptables 可能会很复杂,但是有很多不错的模板,我们通常可以使用它们来帮助客户创建Iptables。例如,默认的RedHat或者CentOS防火墙的配置说明只有10行,显然并不实用。我们最佳实践的Iptables配置大概有5页,这其中包含了Linux所能提供的最高级的安全防范。
所有公用的服务,都应该运行在专门的用户下,如Apache。切记永远都不要使用Root用户运行,因为这会让任何闯入到Apache的用户接管整个服务器。如果Apache只是运行在 Apache用户下或者运行在Nobody下,那么闯入Apache就不是一件容易的事情了。
Web服务器运行或者服务的文件(像.php和.html文件)对于Web服务器的用户应该是不可写的。这意味着Apache或者Nginx用户不应该拥有Web目录的写权限。有很多方法都可以做到这一点,而最简单的就是将这些文件为其他用户所有,然后让Apache/Nginx等用户归属于能够使用640权限读取文件的组中。这会防范几乎所有的黑客和针对页面的攻击。
此外,永远不要使用Ftp来上传文件,特别是在公用的Wi-Fi环境中,因为在其中黑客很容易盗取用户名和密码。取而代之的是使用Sftp会更加安全。另外,每个雇员都应该拥有自己的用户ID和随机密码。【其实并非是所谓的SFTP安全,我倒是认为,多开通一个功能,相应的就会多一个漏洞】
3、使用标准的路径和安装配置
一个令人讨厌的部署问题是,开发者很少考虑他们的软件会被部署到生产Web服务器的什么位置,以及如何部署。我们看到过许多大型的系统将它们的PHP代码部署在/home/xiaofeng或者 /web/code路径下。事实上,这两个路径都是非常不标准的,并且会带来操作和安全性的问题。当这些系统从开发环境转移到测试环境再到生产环境中时,因为每个安装配置都是非标准的,所以经常会出现问题,这时就需要开发者调整才能够正常工作。
你应该总是使用标准的安装包和二进制文件来 安装像Apache之类的服务器。不要从源代码编译或者安装Tarball,因为这会导致长期稳定性和管理上的问题,另外在服务器上安装多个不同的版本也 会造成混淆。
Web站点应该总是在指定的平台和 Linux发布的标准路径下进行测试和部署,像RedHat 或者CentOS下的/var/www/html路径。这有助于对系统进行有效的权限管理、备份、配置、监控以及其他操作。
Web 服务器的日志应该存放在/var/logs或者/var/logs/app_name下,而不应该位于主代码区域。这样做的原因不仅仅是因为这些标准的路径很重要,更应该关注的是,恰当地配置服务器会将/var配置为分离的文件系统。如果应用程序突然写入了大量日志并占用所有磁盘空间,由于我们做了以上的配置就不会导致系统崩溃,或者其他严重的问题。如果日志位于其他位置,就可能会产生问题。【分区真的很重要,不管是因为网站还是因为日志,单独的分区真的很有用,哪怕是重装系统还不会影响这个分区】
4、总是使用日志
在Web系统中做多少日志都不为过。所有系统都应该将重要的数据写入到日志中,不管是它们自己的日志还是系统的Syslog。Cron的Job以及其他Shell脚本或者C语言的程序,对日志都有相应标准以及简单的函数。在Shell脚本中,只需要使用 Logger命令就可以实现日志的写入。在脚本启动/停止、重要的脚本执行以及实时数据产生的情况下都要执行写入日志操作。这样出现问题的时候,查看主要的系统日志就可以很容易地看到发生了什么。
大型系统经常会使用专门的工具如 Local5来记录日志,并配置Syslog或者Syslog-ng来将其存放在单独的文件中,这样会更容易使用。需要注意的是,Syslog工具和 Logger(以及任何Syslog调用)默认优先使用user.notice,如有必要,你可以对其进行调整。
一个好的系统会对程序进行配置,用来打开或者关闭日志,并可以选择在每模块或者功能的级别上应用不同级别的日志。这使得我们可以记录非常详细和强大的日志,用来分析和调试在生产操作中所发生的问题。【日志这玩意让人爱让人恨,爱是因为他可以让我们查出很多潜在问题,恨是因为,访问量过大的网站LOG几天就可以把磁盘撑满】
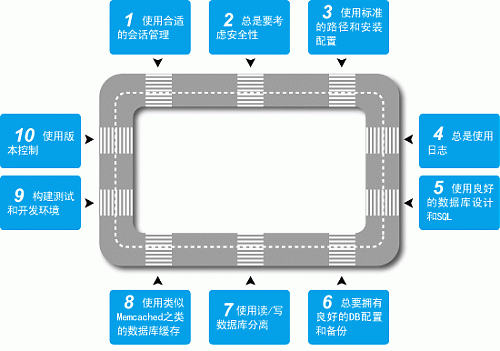 大型高性能网站的十项规则
大型高性能网站的十项规则
5、使用良好的数据库设计和SQL
在任何系统中,数据库通常是最大的性能瓶颈。而影响数据库性能的最大两个问题是数据库设计和SQL代码质量。很多系统都拥有良好的或者至少是可用的数据库设计,但由于没有经过适当的性能测试,SQL代码质量通常都会很差。这样的SQL代码在开发环境中可能运行很快,因为其中只有小数据集和最小的负载。但是当成千上万的用户同时读取数据库中上百万条记录的时候,它就很可能会崩溃。
不幸的是,这些问题一开始并不明显,直到系统增大、突然开始崩溃的时候才会显现出来。在增大的过程中,数据库系统看起来运行得很快(因为数据都位于内存中,而且很少有并发的查询),并且对用户的响应也很快,但实际上它的内部运行效率很低。这并不重要,我们关注的是在系统增大并遇到性能问题之前找到这些问题并加以解决。
关于这个问题有很多不错的书和站点进行了解析,其中的关键工具包括慢查询日志、INNODB状态系统,以及描述当前性能的MySQL统计信息。我们见到过很多系统每秒会读取500,000条数据,这是出现SQL问题的明显预兆,但公司往往对其一无所知直到服务器开始崩溃。
MySQL系统应该对所有数据使用 INNODB存储引擎,因为INNODB与之前的MyISAM相比,运行得更快、更稳定,并且管理性能和备份工作也更加容易和快捷。在主配置文件中,INNODB应该被设置为默认的数据库引擎,并且系统应该不时地进行检查,看是否意外创建了MyISAM的表。【这点好象和很多人的想法是相反的吧?很多人都认为应该是创建MYISAM表,而不是INNODB,妖了。。。】
6、总要拥有良好的DB配置和备份
很多公司都没有良好的备份机制,也不知道如何恰当地完成这项工作。MySQL的Dump是不够的,因为最好的备份方法是使用LVM快照和INNODB对系统进行热备份,从而得到超快的速度和超高的可靠性。
另外,在将所有备份文件从服务器上转移出来之前要进行压缩和加密。另外还要确保拥有设计合理的MySQL配置。MySQL默认安装使用说明中只有5~10行关于配置的说明,这根本不适合开发使用。而我们提供给客户的最佳实践文档足足有10页那么长。文档中大约有100种有用的关于安全、性能和稳定性问题的设定,包括防止数据败坏,其中很多设定都是非常重要的。【很验难配,真的,想配置的好真的很难】
7、使用读/写数据库分离
随着系统变得越来越庞大,特别是当它们拥有很差的SQL时,一台数据库服务器通常不足以处理负载。但是多个数据库意味着重复,除非你对数据进行了分离。更一般地,这意味着建立主/从副本系统,其中程序会对主库编写所有的Update、Insert和Delete变更语句,而所有Select的数据都读取自从数据库(或者多个从数据库)。
尽管概念上很简单,但是想要合理、精确地实现并不容易,这可能需要大量的代码工作。因此,即便在开始时使用同一台数据库服务器,也要尽早计划在PHP中使用分离的DB连接来进行读写操作。如果正确地完成该项工作,那么系统就可以扩展到2台、3台甚至12台服务器,并具备高可用性和稳定性。【我不知道这篇文章是几年前的,我相信,目前所谓的读写分离好象用的不多了,更多的会采用前置处理,然后由数据库自动分发,以及采用更好的缓存功能。读写其实并不能增强多少性能。当然如果是电子商务网站,或许可以。但对于PHP来说,真的没多大意义 ,因为PHP没有连接池功能,读和写发生交互的时候,相当于连接了两个数据库,还不能互相同时使用】
8、使用类似Memcached之类的数据库缓存
即便有了好的数据库设计、SQL和读写分离,大型的系统仍然需要更快的性能,特别是对会话状态、好友列表以及BBS文字之类的东西。为了达到这个目的,我们可以使用像MemCached之类的数据缓存,它是一个高性能的简单数据缓存,已经被所有最大型的站点使用。但是要小心的是,不要100%依赖于一台Memcache服务器来提高性能,因为如果那台服务器崩溃了,就会破坏整个系统的性能。在这种情况下,应该使用2~3台Memcache服务器形成簇集架构,并且有选择地包含一个缓存准备过程,如果缓存服务器重启,需要重新载入数据,它能够快速地载入缓存。【推荐】
9、构建测试和开发环境
很多公司只有开发者的桌面系统和他们的生产服务器。当系统变得越来越大、越来越复杂时,测试和管理代码就会导致严重的问题。最佳的实践是拥有两个测试系统,一个用于开发者的代码和功能的整合测试,另一个要与生产环境完全一致,从而更容易向生产环境平滑地过渡。幸运的是,现在使用云计算(或者私有云)可以轻松达到这一点。一个5~10台服务器的生产环境,可以很容易地在办公室或者IDC中使用一台服务器来复制,从而用于测试,而这台服务器我们可以用于多个客户的项目。【正如文章开头所说的,哪有空来做这事啊。。。】
10、使用版本控制
最后,要对一切使用版本控制,包括测试和生产环境的部署。很多开发者都使用SVN或者类似的方法。在理想状态下,这些方法可以被用于所有代码、脚本、HTML、图片、配置、文档和测试。版本控制应该是代码转移到测试环境的必经之路,而不是简单地复制或者使用tar文件,因为这二者都是不可靠的。开发者应该将所有一切都签入,打上标签,然后将它们签出到测试系统。如果所有都没问题,那么它们会将该版本签出到生产环境。【多人开发的时候非常有必要。从最初CVS到SVN到现在的GIT,经历了很多了,好象linus推荐是采用GIT,好象是可以直接在本地就可以创建版本库】
总 结:
不管是在开发还是在运营过程中,创建可靠的 高性能Web系统都有很多应该注意的事项。本文试图从可操作性和可靠性的角度讨论最重要的几点。当你构建和管理站点的时候,请不要忘了这些重要的问题。遵 循这些规则会有助于确保系统长久、良好地运行。
作者简介:
Steve Mushero,ChinaNetCloud 公司联合创始人、CEO兼CTO,拥有全球20多年的技术管理经验。曾担任土豆网、Intermind和 Advanced Management Systems等多家企业CTO
译者简介:
侯伯薇,生于凤城,学在春城,做过国内和对 日项目,现在大连某保险公司工作。乐于钻研技术,同时注重业务知识,勤于思考,愿意与人交流和分享。
Tags: 高性能, 架构, 设计
PHP | 评论:1
| 阅读:27532
Submitted by gouki on 2009, July 15, 9:23 PM
买回ipod classic 120G也有两个多月了吧。昨天晚上听完歌后,就直接睡眠了。
今天早上乘公车发现黑屏。以为是昨天晚上误按导致启动后电全部用完。
因为身边没带数据线,所以无法操作。
晚上回到家中,插上机器,发现仍然是黑屏(上次没电的时候,还是可以点亮,并提示不要拔机器的。)这回,全黑了,一点反应没有。。。
紧张啊。itunes打开一看,发现quicktime被我删除,无法启动。。。
只能先google了。找到相应的提示:按住MENU+当中的按钮。长按,过了好久,终于出现一个暗暗的苹果标志。
然后打开移动硬盘(也就是苹果的磁盘),数据还在。。。
激动啊。看来苹果的东西也是会经常死机的嘛。。
看到网上很多人都说无法激活,然后送修,花了N多钱后,还是很安慰。省下一笔开销了。虽然可能在保修期内是免费的,但要跑到售后点,太累了。天又热。
解决了。安心了。睡觉了。
Tags: ipod, classic, 黑屏
Misc | 评论:0
| 阅读:22258
Submitted by gouki on 2009, January 19, 2:23 PM
一大早流年就在群里说发布了Lite版本,但是我还没有欣赏一下具体的代码,好象这个版本的想法是用Yhustc那里冒出来的,因为他的Yblog就自行对ThinkPHP 1.5进行了简化只保留了常用的功能,比如:数据库只支持MYSQL(也是,这个博客程序只用MYSQL,其他的一些驱动就可有可无了)。于是流年在这个想法的基础上,花了几天时间进行了Lite的构造。(估计几天的休息时间就这么没有了吧)
官方原文:http://www.thinkphp.cn/Blog/25
发布该版本的原因是很多应用开发要求较高的性能并且不需要很多特殊的功能
Lite版本提供网站开发最需要的功能,优化性能,更适合大型项目!
[ 功能列表 ]
编译缓存
自动生成
异常处理
URL模式
语言包支持
模板主题支持
空模块和空操作
前置和后置操作
智能数据表识别
自动加载
标签库
类库导入
Vendor支持
ADSL方法
跨库操作
字段映射
URL组装
URL伪静态
原生SQL操作
多数据库连接和切换
分布式数据库支持
支持MySql和PDO
惯例配置
项目配置
动态配置
模块配置
静态缓存
动态缓存
模板引擎和扩展支持
日志处理
SQL日志
调试模式
运行时间显示
页面Trace
类库扩展
自动验证
自动完成
CURD基本
AR模式基本
连贯操作
[ 注意事项 ]
去掉了ORG类库包(自己可以增加扩展)
保留文件缓存驱动
保留内置模板引擎和PHP模板引擎驱动
查询条件只支持字符串
CURD接口和数据库接口已经更改(和标准版不兼容)
视图模型和关联操作已经去掉
模型的数据操作保留了 add save delete find query execute 增加了select方法 并做了参数的调整
去掉了自动获取数据表字段信息 改由模型自己定义或者不定义
保留运行信息和页面Trace显示
去掉了URL路由功能(该部分功能可以用空模块和空操作取代)
[ 下载Lite版本 ]
Lite版本适合对TP有一定了解的开发人员,并且有PHP开发经验和足够的扩展能力。
Tags: thinkphp, lite
PHP Framework | 评论:0
| 阅读:26705
Submitted by gouki on 2009, January 17, 9:26 PM
对于my.cnf,我一向是懒得看的,因为在windows下面mysql默认有四个ini文件,只要拿其中的一个改为my.ini就行了。一般是拿最大的那个改,而且因为很少用innodb之类的,所以真正改的也就是第一个区块的内容。
看到冰山上的播客上面有翻译,于是COPY过来,与大家分享一下,毕竟即使不是你自己配置数据库,但了解一下也好。
XML/HTML代码
- #BEGIN CONFIG INFO
- #DESCR: 4GB RAM, 只使用InnoDB, ACID, 少量的连接, 队列负载大
- #TYPE: SYSTEM
- #END CONFIG INFO
- #
- # 此mysql配置文件例子针对4G内存,并在www.bt285.cn bt下载与 www.5a520.cn 小说520,这两个日ip 2w ,pv 20w 测试过的。
- # 主要使用INNODB
- #处理复杂队列并且连接数量较少的mysql服务器
- #
- # 将此文件复制到/etc/my.cnf 作为全局设置,
- # mysql-data-dir/my.cnf 作为服务器指定设置
- # (@localstatedir@ for this installation) 或者放入
- # ~/.my.cnf 作为用户设置.
- #
- # 在此配置文件中, 你可以使用所有程序支持的长选项.
- # 如果想获悉程序支持的所有选项
- # 请在程序后加上”–help”参数运行程序.
- #
- # 关于独立选项更多的细节信息可以在手册内找到
- #
- #
- # 以下选项会被MySQL客户端应用读取.
- # 注意只有MySQL附带的客户端应用程序保证可以读取这段内容.
- # 如果你想你自己的MySQL应用程序获取这些值
- # 需要在MySQL客户端库初始化的时候指定这些选项
- #
- [client]
- #password = [your_password]
- port = @MYSQL_TCP_PORT@
- socket = @MYSQL_UNIX_ADDR@
- # *** 应用定制选项 ***
- #
- # MySQL 服务端
- #
- [mysqld]
- # 一般配置选项
- port = @MYSQL_TCP_PORT@
- socket = @MYSQL_UNIX_ADDR@
- # back_log 是操作系统在监听队列中所能保持的连接数,
- # 队列保存了在MySQL连接管理器线程处理之前的连接.
- # 如果你有非常高的连接率并且出现”connection refused” 报错,
- # 你就应该增加此处的值.
- # 检查你的操作系统文档来获取这个变量的最大值.
- # 如果将back_log设定到比你操作系统限制更高的值,将会没有效果
- back_log = 50
- # 不在TCP/IP端口上进行监听.
- # 如果所有的进程都是在同一台服务器连接到本地的mysqld,
- # 这样设置将是增强安全的方法
- # 所有mysqld的连接都是通过Unix sockets 或者命名管道进行的.
- # 注意在windows下如果没有打开命名管道选项而只是用此项
- # (通过 “enable-named-pipe” 选项) 将会导致mysql服务没有任何作用!
- #skip-networking
- # MySQL 服务所允许的同时会话数的上限
- # 其中一个连接将被SUPER权限保留作为管理员登录.
- # 即便已经达到了连接数的上限.
- max_connections = 100
- 一般像在我这个www.bt285.cn pv 10w max_connections=30 就够了。但是如果页面都像http://www.bt285.cn/content.php?id=1196863 这个甜性涩爱页面一样,max_connections=30是不够的。
- # 每个客户端连接最大的错误允许数量,如果达到了此限制.
- # 这个客户端将会被MySQL服务阻止直到执行了”FLUSH HOSTS” 或者服务重启
- # 非法的密码以及其他在链接时的错误会增加此值.
- # 查看 “Aborted_connects” 状态来获取全局计数器.
- max_connect_errors = 10
- # 所有线程所打开表的数量.
- # 增加此值就增加了mysqld所需要的文件描述符的数量
- # 这样你需要确认在[mysqld_safe]中 “open-files-limit” 变量设置打开文件数量允许至少4096
- table_cache = 2048
- # 允许外部文件级别的锁. 打开文件锁会对性能造成负面影响
- # 所以只有在你在同样的文件上运行多个数据库实例时才使用此选项(注意仍会有其他约束!)
- # 或者你在文件层面上使用了其他一些软件依赖来锁定MyISAM表
- #external-locking
- # 服务所能处理的请求包的最大大小以及服务所能处理的最大的请求大小(当与大的BLOB字段一起工作时相当必要)
- # 每个连接独立的大小.大小动态增加
- max_allowed_packet = 16M
- # 在一个事务中binlog为了记录SQL状态所持有的cache大小
- # 如果你经常使用大的,多声明的事务,你可以增加此值来获取更大的性能.
- # 所有从事务来的状态都将被缓冲在binlog缓冲中然后在提交后一次性写入到binlog中
- # 如果事务比此值大, 会使用磁盘上的临时文件来替代.
- # 此缓冲在每个连接的事务第一次更新状态时被创建
- binlog_cache_size = 1M
- # 独立的内存表所允许的最大容量.
- # 此选项为了防止意外创建一个超大的内存表导致永尽所有的内存资源.
- max_heap_table_size = 64M
- # 排序缓冲被用来处理类似ORDER BY以及GROUP BY队列所引起的排序
- # 如果排序后的数据无法放入排序缓冲,
- # 一个用来替代的基于磁盘的合并分类会被使用
- # 查看 “Sort_merge_passes” 状态变量.
- # 在排序发生时由每个线程分配
- sort_buffer_size = 8M
- # 此缓冲被使用来优化全联合(full JOINs 不带索引的联合).
- # 类似的联合在极大多数情况下有非常糟糕的性能表现,
- # 但是将此值设大能够减轻性能影响.
- # 通过 “Select_full_join” 状态变量查看全联合的数量
- # 当全联合发生时,在每个线程中分配
- join_buffer_size = 8M
- # 我们在cache中保留多少线程用于重用
- # 当一个客户端断开连接后,如果cache中的线程还少于thread_cache_size,
- # 则客户端线程被放入cache中.
- # 这可以在你需要大量新连接的时候极大的减少线程创建的开销
- # (一般来说如果你有好的线程模型的话,这不会有明显的性能提升.)
- thread_cache_size = 8
- # 此允许应用程序给予线程系统一个提示在同一时间给予渴望被运行的线程的数量.
- # 此值只对于支持 thread_concurrency() 函数的系统有意义( 例如Sun Solaris).
- # 你可可以尝试使用 [CPU数量]*(2..4) 来作为thread_concurrency的值
- thread_concurrency = 8
- # 查询缓冲常被用来缓冲 SELECT 的结果并且在下一次同样查询的时候不再执行直接返回结果.
- # 打开查询缓冲可以极大的提高服务器速度, 如果你有大量的相同的查询并且很少修改表.
- # 查看 “Qcache_lowmem_prunes” 状态变量来检查是否当前值对于你的负载来说是否足够高.
- # 注意: 在你表经常变化的情况下或者如果你的查询原文每次都不同,
- # 查询缓冲也许引起性能下降而不是性能提升.
- query_cache_size = 64M
- # 只有小于此设定值的结果才会被缓冲
- # 此设置用来保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖.
- query_cache_limit = 2M
- # 被全文检索索引的最小的字长.
- # 你也许希望减少它,如果你需要搜索更短字的时候.
- # 注意在你修改此值之后,
- # 你需要重建你的 FULLTEXT 索引
- ft_min_word_len = 4
- # 如果你的系统支持 memlock() 函数,你也许希望打开此选项用以让运行中的mysql在在内存高度紧张的时候,数据在内存中保持锁定并且防止可能被swapping out
- # 此选项对于性能有益
- #memlock
- # 当创建新表时作为默认使用的表类型,
- # 如果在创建表示没有特别执行表类型,将会使用此值
- default_table_type = MYISAM
- # 线程使用的堆大小. 此容量的内存在每次连接时被预留.
- # MySQL 本身常不会需要超过64K的内存
- # 如果你使用你自己的需要大量堆的UDF函数
- # 或者你的操作系统对于某些操作需要更多的堆,
- # 你也许需要将其设置的更高一点.
- thread_stack = 192K
- # 设定默认的事务隔离级别.可用的级别如下:
- # READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE
- transaction_isolation = REPEATABLE-READ
- # 内部(内存中)临时表的最大大小
- # 如果一个表增长到比此值更大,将会自动转换为基于磁盘的表.
- # 此限制是针对单个表的,而不是总和.
- tmp_table_size = 64M
- # 打开二进制日志功能.
- # 在复制(replication)配置中,作为MASTER主服务器必须打开此项
- # 如果你需要从你最后的备份中做基于时间点的恢复,你也同样需要二进制日志.
- log-bin=mysql-bin
- # 如果你在使用链式从服务器结构的复制模式 (A->B->C),
- # 你需要在服务器B上打开此项.
- # 此选项打开在从线程上重做过的更新的日志,
- # 并将其写入从服务器的二进制日志.
- #log_slave_updates
- # 打开全查询日志. 所有的由服务器接收到的查询 (甚至对于一个错误语法的查询)
- # 都会被记录下来. 这对于调试非常有用, 在生产环境中常常关闭此项.
- #log
- # 将警告打印输出到错误log文件. 如果你对于MySQL有任何问题
- # 你应该打开警告log并且仔细审查错误日志,查出可能的原因.
- #log_warnings
- # 记录慢速查询. 慢速查询是指消耗了比 “long_query_time” 定义的更多时间的查询.
- # 如果 log_long_format 被打开,那些没有使用索引的查询也会被记录.
- # 如果你经常增加新查询到已有的系统内的话. 一般来说这是一个好主意,
- log_slow_queries
- # 所有的使用了比这个时间(以秒为单位)更多的查询会被认为是慢速查询.
- # 不要在这里使用”1″, 否则会导致所有的查询,甚至非常快的查询页被记录下来(由于MySQL 目前时间的精确度只能达到秒的级别).
- long_query_time = 2
- # 在慢速日志中记录更多的信息.
- # 一般此项最好打开.
- # 打开此项会记录使得那些没有使用索引的查询也被作为到慢速查询附加到慢速日志里
- log_long_format
- # 此目录被MySQL用来保存临时文件.例如,
- # 它被用来处理基于磁盘的大型排序,和内部排序一样.
- # 以及简单的临时表.
- # 如果你不创建非常大的临时文件,将其放置到 swapfs/tmpfs 文件系统上也许比较好
- # 另一种选择是你也可以将其放置在独立的磁盘上.
- # 你可以使用”;”来放置多个路径
- # 他们会按照roud-robin方法被轮询使用.
- #tmpdir = /tmp
- # *** 复制有关的设置
- # 唯一的服务辨识号,数值位于 1 到 2^32-1之间.
- # 此值在master和slave上都需要设置.
- # 如果 “master-host” 没有被设置,则默认为1, 但是如果忽略此选项,MySQL不会作为master生效.
- server-id = 1
- # 复制的Slave (去掉master段的注释来使其生效)
- #
- # 为了配置此主机作为复制的slave服务器,你可以选择两种方法:
- #
- # 1) 使用 CHANGE MASTER TO 命令 (在我们的手册中有完整描述) -
- # 语法如下:
- #
- # CHANGE MASTER TO MASTER_HOST=<host>, MASTER_PORT=<port>,
- # MASTER_USER=<user>, MASTER_PASSWORD=<password> ;
- #
- # 你需要替换掉 <host>, <user>, <password> 等被尖括号包围的字段以及使用master的端口号替换<port> (默认3306).
- #
- # 例子:
- #
- # CHANGE MASTER TO MASTER_HOST=’125.564.12.1′, MASTER_PORT=3306,
- # MASTER_USER=’joe’, MASTER_PASSWORD=’secret’;
- #
- # 或者
- #
- # 2) 设置以下的变量. 不论如何, 在你选择这种方法的情况下, 然后第一次启动复制(甚至不成功的情况下,
- # 例如如果你输入错密码在master-password字段并且slave无法连接),
- # slave会创建一个 master.info 文件,并且之后任何对于包含在此文件内的参数的变化都会被忽略
- # 并且由 master.info 文件内的内容覆盖, 除非你关闭slave服务, 删除 master.info 并且重启slave 服务.
- # 由于这个原因,你也许不想碰一下的配置(注释掉的) 并且使用 CHANGE MASTER TO (查看上面) 来代替
- #
- # 所需要的唯一id号位于 2 和 2^32 - 1之间
- # (并且和master不同)
- # 如果master-host被设置了.则默认值是2
- # 但是如果省略,则不会生效
- #server-id = 2
- #
- # 复制结构中的master - 必须
- #master-host = <hostname>
- #
- # 当连接到master上时slave所用来认证的用户名 - 必须
- #master-user = <username>
- #
- # 当连接到master上时slave所用来认证的密码 - 必须
- #master-password = <password>
- #
- # master监听的端口.
- # 可选 - 默认是3306
- #master-port = <port>
- # 使得slave只读.只有用户拥有SUPER权限和在上面的slave线程能够修改数据.
- # 你可以使用此项去保证没有应用程序会意外的修改slave而不是master上的数据
- #read_only
- #*** MyISAM 相关选项
- # 关键词缓冲的大小, 一般用来缓冲MyISAM表的索引块.
- # 不要将其设置大于你可用内存的30%,
- # 因为一部分内存同样被OS用来缓冲行数据
- # 甚至在你并不使用MyISAM 表的情况下, 你也需要仍旧设置起 8-64M 内存由于它同样会被内部临时磁盘表使用.
- key_buffer_size = 32M
- # 用来做MyISAM表全表扫描的缓冲大小.
- # 当全表扫描需要时,在对应线程中分配.
- read_buffer_size = 2M
- # 当在排序之后,从一个已经排序好的序列中读取行时,行数据将从这个缓冲中读取来防止磁盘寻道.
- # 如果你增高此值,可以提高很多ORDER BY的性能.
- # 当需要时由每个线程分配
- read_rnd_buffer_size = 16M
- # MyISAM 使用特殊的类似树的cache来使得突发插入
- # (这些插入是,INSERT … SELECT, INSERT … VALUES (…), (…), …, 以及 LOAD DATA
- # INFILE) 更快. 此变量限制每个进程中缓冲树的字节数.
- # 设置为 0 会关闭此优化.
- # 为了最优化不要将此值设置大于 “key_buffer_size”.
- # 当突发插入被检测到时此缓冲将被分配.
- bulk_insert_buffer_size = 64M
- # 此缓冲当MySQL需要在 REPAIR, OPTIMIZE, ALTER 以及 LOAD DATA INFILE 到一个空表中引起重建索引时被分配.
- # 这在每个线程中被分配.所以在设置大值时需要小心.
- myisam_sort_buffer_size = 128M
- # MySQL重建索引时所允许的最大临时文件的大小 (当 REPAIR, ALTER TABLE 或者 LOAD DATA INFILE).
- # 如果文件大小比此值更大,索引会通过键值缓冲创建(更慢)
- myisam_max_sort_file_size = 10G
- # 如果被用来更快的索引创建索引所使用临时文件大于制定的值,那就使用键值缓冲方法.
- # 这主要用来强制在大表中长字串键去使用慢速的键值缓冲方法来创建索引.
- myisam_max_extra_sort_file_size = 10G
- # 如果一个表拥有超过一个索引, MyISAM 可以通过并行排序使用超过一个线程去修复他们.
- # 这对于拥有多个CPU以及大量内存情况的用户,是一个很好的选择.
- myisam_repair_threads = 1
- # 自动检查和修复没有适当关闭的 MyISAM 表.
- myisam_recover
- # 默认关闭 Federated
- skip-federated
- # *** BDB 相关选项 ***
- # 如果你运行的MySQL服务有BDB支持但是你不准备使用的时候使用此选项. 这会节省内存并且可能加速一些事.
- skip-bdb
- # *** INNODB 相关选项 ***
- # 如果你的MySQL服务包含InnoDB支持但是并不打算使用的话,
- # 使用此选项会节省内存以及磁盘空间,并且加速某些部分
- #skip-innodb
- # 附加的内存池被InnoDB用来保存 metadata 信息
- # 如果InnoDB为此目的需要更多的内存,它会开始从OS这里申请内存.
- # 由于这个操作在大多数现代操作系统上已经足够快, 你一般不需要修改此值.
- # SHOW INNODB STATUS 命令会显示当先使用的数量.
- innodb_additional_mem_pool_size = 16M
- # InnoDB使用一个缓冲池来保存索引和原始数据, 不像 MyISAM.
- # 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
- # 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%
- # 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
- # 注意在32位系统上你每个进程可能被限制在 2-3.5G 用户层面内存限制,
- # 所以不要设置的太高.
- innodb_buffer_pool_size = 2G
- # InnoDB 将数据保存在一个或者多个数据文件中成为表空间.
- # 如果你只有单个逻辑驱动保存你的数据,一个单个的自增文件就足够好了.
- # 其他情况下.每个设备一个文件一般都是个好的选择.
- # 你也可以配置InnoDB来使用裸盘分区 - 请参考手册来获取更多相关内容
- innodb_data_file_path = ibdata1:10M:autoextend
- # 设置此选项如果你希望InnoDB表空间文件被保存在其他分区.
- # 默认保存在MySQL的datadir中.
- #innodb_data_home_dir = <directory>
- # 用来同步IO操作的IO线程的数量. This value is
- # 此值在Unix下被硬编码为4,但是在Windows磁盘I/O可能在一个大数值下表现的更好.
- innodb_file_io_threads = 4
- # 如果你发现InnoDB表空间损坏, 设置此值为一个非零值可能帮助你导出你的表.
- # 从1开始并且增加此值知道你能够成功的导出表.
- #innodb_force_recovery=1
- # 在InnoDb核心内的允许线程数量.
- # 最优值依赖于应用程序,硬件以及操作系统的调度方式.
- # 过高的值可能导致线程的互斥颠簸.
- innodb_thread_concurrency = 16
- # 如果设置为1 ,InnoDB会在每次提交后刷新(fsync)事务日志到磁盘上,
- # 这提供了完整的ACID行为.
- # 如果你愿意对事务安全折衷, 并且你正在运行一个小的食物, 你可以设置此值到0或者2来减少由事务日志引起的磁盘I/O
- # 0代表日志只大约每秒写入日志文件并且日志文件刷新到磁盘.
- # 2代表日志写入日志文件在每次提交后,但是日志文件只有大约每秒才会刷新到磁盘上.
- innodb_flush_log_at_trx_commit = 1
- # 加速InnoDB的关闭. 这会阻止InnoDB在关闭时做全清除以及插入缓冲合并.
- # 这可能极大增加关机时间, 但是取而代之的是InnoDB可能在下次启动时做这些操作.
- #innodb_fast_shutdown
- # 用来缓冲日志数据的缓冲区的大小.
- # 当此值快满时, InnoDB将必须刷新数据到磁盘上.
- # 由于基本上每秒都会刷新一次,所以没有必要将此值设置的太大(甚至对于长事务而言)
- innodb_log_buffer_size = 8M
- # 在日志组中每个日志文件的大小.
- # 你应该设置日志文件总合大小到你缓冲池大小的25%~100%
- # 来避免在日志文件覆写上不必要的缓冲池刷新行为.
- # 不论如何, 请注意一个大的日志文件大小会增加恢复进程所需要的时间.
- innodb_log_file_size = 256M
- # 在日志组中的文件总数.
- # 通常来说2~3是比较好的.
- innodb_log_files_in_group = 3
- # InnoDB的日志文件所在位置. 默认是MySQL的datadir.
- # 你可以将其指定到一个独立的硬盘上或者一个RAID1卷上来提高其性能
- #innodb_log_group_home_dir
- # 在InnoDB缓冲池中最大允许的脏页面的比例.
- # 如果达到限额, InnoDB会开始刷新他们防止他们妨碍到干净数据页面.
- # 这是一个软限制,不被保证绝对执行.
- innodb_max_dirty_pages_pct = 90
- # InnoDB用来刷新日志的方法.
- # 表空间总是使用双重写入刷新方法
- # 默认值是 “fdatasync”, 另一个是 “O_DSYNC”.
- #innodb_flush_method=O_DSYNC
- # 在被回滚前,一个InnoDB的事务应该等待一个锁被批准多久.
- # InnoDB在其拥有的锁表中自动检测事务死锁并且回滚事务.
- # 如果你使用 LOCK TABLES 指令, 或者在同样事务中使用除了InnoDB以外的其他事务安全的存储引擎
- # 那么一个死锁可能发生而InnoDB无法注意到.
- # 这种情况下这个timeout值对于解决这种问题就非常有帮助.
- innodb_lock_wait_timeout = 120
- [mysqldump]
- # 不要在将内存中的整个结果写入磁盘之前缓存. 在导出非常巨大的表时需要此项
- quick
- max_allowed_packet = 16M
- [mysql]
- no-auto-rehash
- # 仅仅允许使用键值的 UPDATEs 和 DELETEs .
- #safe-updates
- [isamchk]
- key_buffer = 512M
- sort_buffer_size = 512M
- read_buffer = 8M
- write_buffer = 8M
- [myisamchk]
- key_buffer = 512M
- sort_buffer_size = 512M
- read_buffer = 8M
- write_buffer = 8M
- [mysqlhotcopy]
- interactive-timeout
- [mysqld_safe]
- # 增加每个进程的可打开文件数量.
- # 警告: 确认你已经将全系统限制设定的足够高!
- # 打开大量表需要将此值设高 j
- open-files-limit = 8192
Tags: mysql, 配置, 翻译
Baby | 评论:0
| 阅读:21872
Submitted by gouki on 2008, December 31, 12:03 AM
时间过的真快,一转眼到XX网也已经有了一年多了。回顾这一年多来,却发现自己不知道在忙些什么,又在折腾些什么。
时间如流水般哗哗的漂过,而自己却依旧在希望的田野上徘徊着。迷惘,则是我一年多来最多的心情写照。
每个人都是希望自己能够做一些事情的,我也不例外。虽然在XX网的时间不长,但也经历了一些我认为比较大的事件:
1、年会:一年前,公司所有的员工欢聚一堂,举杯畅饮,还有抽奖活动,Boss开心的说,今年人人都有奖金;一年后,公司以为人均标准100元为目标,让各部门自由举行活动
2、班车:一年前,作为公司福利,我很幸运的乘着某辆班车天天上下班;一年后,公司说地铁通车了,大家乘地铁去。
3、辞退:一年前,公司说我们要发展,我们要扩张;一年后,公司在裁员,大多是老员工(网上可以查到:XX网裁员内幕)
当然这都是公司的一些变化,也让我们感受到了互联网寒冬的到来。现实情况就是寒风凛冽,而我们就站在这瑟瑟寒风中默默感受着。只要是有远见的人,都会在这段时间求变,以便在春天到来时可以积累下庞大的资源。XX网于是就在改版,而我的事情就准备从改版前开始说起。。。
话说。。。(改版的篇幅实在太长,下篇继续[毕竟我原来写这个就写了一小时],文章会加密处理,熟悉我的朋友可以MSN或者QQ上索取密码)
Tags: xx网, 感慨
Misc | 评论:1
| 阅读:21631


