知道分子的这个事例事实也经常遇到过。只是谁都没有提出来当成一回事
在自己的机器上,各种不同版本的PHP一直存在着,或许,相对稳定的也就apache和mysql吧?每次要升级前都看着changelog,但即使这样,也会有或多或少的问题发生,然而,在公司的版本库里,测试机里等等中早就存在着不同版本的PHP,只是可能从来就没有注意过罢了。
升还是不升这是个问题,但如果真的版本不对了,出现的问题也就稀奇古怪了,所以,保证版本号一致还是有着非常重要的作用(如果为了新特性需要升级,那就通知所有的人一起升,最终仅保留一台两台有明显记号的,旧版本的服务器专门用来调试,开发人员有虚拟机的也通通升级到统一的版本号里,一切为了稳定 )
下面是知识分子的内容:这个版本太新了
以前偶尔听到同事 A 问同事 B,某软件出新版本了,我们要不要升级?同事 B 果断地回答,这个版本太新了,我们还是别急着升级吧。同事 A 深以为然,刚出来的版本就升级,万一出个故障谁负责?何况现在这个软件跑得好好的,没事最好别折腾。后来 A、B 两人都忘了这件事,也就没有了下文。
再后来,同事 C 在另一处需要用到该软件,去官方网站上下载了“最新稳定版”(也就是前面那个“太新了”的版本),用着没问题。又过了一段时间,这个软件又出新版本,同事 D 问同事 E,我们要不要升级?同事 E 说,这个版本太新了,你懂的。于是同事 D 拈花微笑,信受奉行。
如此循环往复,同样一个软件,在开发/测试/生产环境里运行着无数个“太新了”的不同版本。
先不谈管理成本,“这个版本太新了”是否构成不升级的理由,颇值得解析一番。为什么要出新版本?不外乎安全漏洞 修补、bug 修正、新功能三者(或混合)。安全漏洞显然是要尽早尽快修补的,明知有安全漏洞而不及时修补,无异于后门洞开等待爆菊,有受虐倾向。整体或所调用部分相关 的 bug 也是要修补的,紧急程度视 bug 可能造成的损失大小而定。新功能则要看未来是否会用到,才决定要不要升级。
“这个版本太新了”之所以被接受,其中也有一定的合理成分。“太新了”指的是新版本没有经过完整的兼容性、稳定性和性能测试,也许会对现有应用造成影响。这个意思永远是对的,或者不客气地说,就是一句废话。任何一个新版本软件都一样,不去做测试你怎么知道有没有影响?
同一个软件,不同的版本,随意分布在多个环境中,这无疑增加了管理的复杂度,当然也有人认为,这体现了“个性 化”。复杂度也好,“个性化”也罢,都是效率的大敌。标准化的高效运维,应该是同一个软件、同一个版本,并且有统一机制进行追踪、测试、升级,保证安全漏 洞、bug 得到及时修补,新功能尽在掌握。
看到有介绍,当然要了解一下详细情况了。毕竟,我的htc g2当初就是靠这个玩意简单的来判断是沃达丰版还是HTC版的【即32A还是32B】。
解释一下Linux上free命令的输出。
下面是free的运行结果,一共有4行。为了方便说明,我们加上了列号。这样可以把free的输出看成一个二维数组FO(Free Output)。例如:
- FO[2][1] = 999212
- FO[3][2] = 305404
1 2 3 4 5 6
1 total used free shared buffers cached
2 Mem: 999212 967476 31736 0 50668 223000
3 -/+ buffers/cache: 693808 305404
4 Swap: 2048276 154524 1893752
free的输出一共有四行,第四行为交换区的信息,分别是交换的总量(total),使用量(used)和有多少空闲的交换区(free),这 个比较清楚,不说太多。
free输出地第二行和第三行是比较让人迷惑的。这两行都是说明内存使用情况的。第一列是总量(free),第二列是使用量(free),第三 列是可用量(free)。第一行的输出时从操作系统(OS)来看的。也就是说,从OS的角度来看,计算机上一共有:
- 999212KB(缺省时free的单位为KB)物理内存,即FO[2][1];
- 在这些物理内存中有967476KB(即FO[2][2])被使用了;
- 还用31736KB(即FO[2][3])是可用的;
这里得到第一个等式:
- FO[2][1] = FO[2][2] + FO[2][3]
FO[2][4]表示被几个进程共享的内存的,现在已经deprecated,其值总是0(当然在一些系统上也可能不是0,主要取决于free命令 是怎么实现的)。
FO[2][5]表示被OS buffer住的内存。FO[2][6]表示被OS cache的内存。在有些时候buffer和cache这两个词经常混用。不过在一些比较低层的软件里是要区分这两个词的,看老外的洋文:
- A buffer is something that has yet to be "written" to disk.
- A cache is something that has been "read" from the disk and stored for later use.
也就是说buffer是用于存放要输出到disk(块设备)的数据的,而cache是存放从disk上读出的数据。这二者是为了提高IO性能的,并 由OS管理。
Linux和其他成熟的操作系统(例如windows),为了提高IO read的性能,总是要多cache一些数据,这也就是为什么FO[2][6](cached memory)比较大,而FO[2][3]比较小的原因。我们可以做一个简单的测试:
- 释放掉被系统cache占用的数据;
echo 3 >/proc/sys/vm/drop_caches
- 读一个大文件,并记录时间;
- 关闭该文件;
- 重读这个大文件,并记录时间;
第二次读应该比第一次快很多。原来我做过一个BerkeleyDB的读操作,大概要读5G的文件,几千万条记录。在我的环境上,第二次读比第一次大 概可以快9倍左右。
free输出的第二行是从一个应用程序的角度看系统内存的使用情况。
- 对于FO[3][2],即-buffers/cache, 表示一个应用程序认为系统被用掉多少内存;
- 对于FO[3][3],即+buffers/cache, 表示一个应用程序认为系统还有多少内存;
因为被系统cache和buffer占用的内存可以被快速回收,所以通常FO[3][3]比FO[2][3]会大很多。
这里还用两个等式:
- FO[3][2] = FO[2][2] - FO[2][5] - FO[2][6]
- FO[3][3] = FO[2][3] + FO[2][5] + FO[2][6]
这二者都不难理解。
free命令由procps.*.rpm提供(在Redhat系列的OS上)。free命令的所有输出值都是从/proc/meminfo中读 出的。
在系统上可能有meminfo(2)这个函数,它就是为了解析/proc/meminfo的。procps这个包自己实现了meminfo()这个 函数。可以下载一个procps的tar包看看具体实现,现在最新版式3.2.8。
--EOF--
原文来自:http://www.cnblogs.com/coldplayerest/archive/2010/02/20/1669949.html,作者就是coldplayerest
Something from jQuery's Blog :
Happy Birthday to jQuery! jQuery is three years old today, after being released way back on January 14th, 2006 at the first BarCampNYC by John Resig.
We have four announcements for you today, we hope you’ll enjoy them!
Url:http://blog.jquery.com/2009/01/14/jquery-13-and-the-jquery-foundation/
中文翻译:http://shawphy.com/2009/01/release-jquery-1-3.html
jQuery 1.3终于发布了。
min版(gzip后18kb)
源码(114kb)
另外可以用google的代码托管:
http://ajax.googleapis.com/ajax/libs/jquery/1.3/jquery.min.js
下面这个是我自己用Packer压缩的pack版
http://shawphy.com/down/jquery-1.3.pack.js(37kb)
简要来说:
更新了Sizzle选择器引擎,这个之前也提到过。可以查看他的性能:
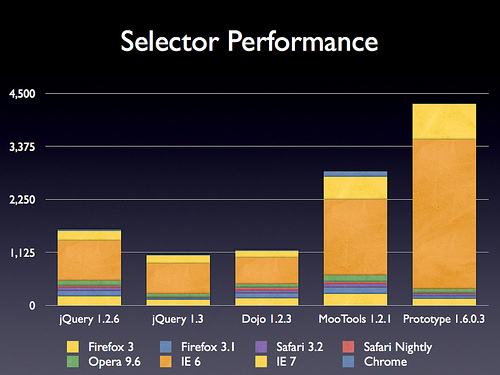
此外据声称,把代码给了dojo基金会。这回Sizzle的野心在于能够让其他各种JS库都能用,包括Prototype, Dojo, Yahoo UI, MochiKit, 和 TinyMCE等等其他库。
live 事件
这也是jQuery 1.3这次更新的第二个重大更新。(注:这里有一个iframe,我没有复制过来,请到原站观赏和测试)
性能比较:
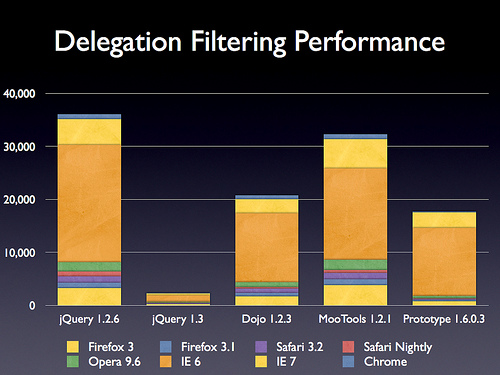
这样,我以前写的关于重复绑定的文章就差不多可以抛弃了
Event 对象
新增了一个jQuery.Event对象,他根据w3c文档,做了一个完整的,兼容所有浏览器的一个对象。具体还得看文档。
append, prepend, before, 和 after 方法重写
据声称,这些方法的效率提升了6倍
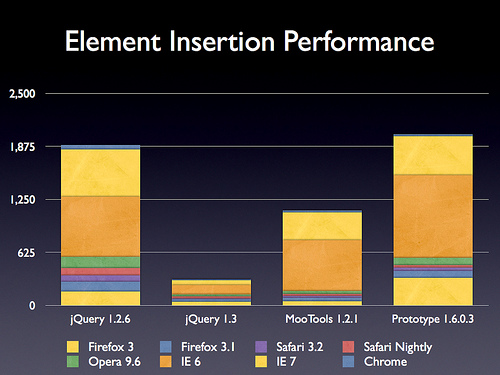
重写了offset方法
这回更快了
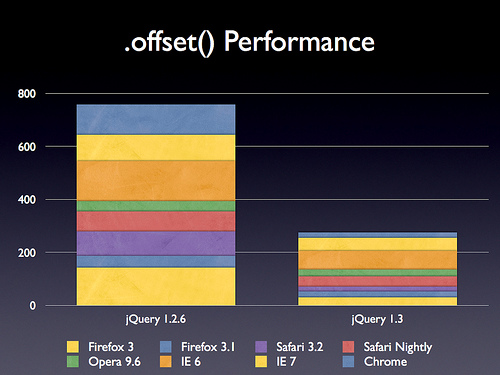
取消了浏览器侦测,全面改用jQuery.support
具体还得看文档了。
变化:
其中与开发者比较密切的是
[@attr] 中的@在1.3里不能用了
用trigger触发的事件现在能冒泡了
ready方法中,再也不等css加载完了再执行其中代码了。直接要求把css放在脚本之前就行
简化了.isFunction方法,那些偏门的就被无视了
用选择器a, b, c选择东西,在支持querySelectorAll (Safari, Firefox 3.1+, Opera 10+, IE 8+)中会按照这些元素在文档中顺序来确定这些数组在获得的对象列表中的位置。而不支持这个方法的浏览器则按照选择器顺序排好
新增了jQuery.Event
要求网页都在标准模式下,不要在怪异模式下使用,否则会报错。
以下3个方法属性已被不推荐使用。
* jQuery.browser
* jQuery.browser.version
* jQuery.boxModel
具体内容:
内核部分:
更好的queue, dequeue
新增selector, context这两个属性,分别指向获取这个元素的原始选择器和被查找的内容(可选)
选择器部分:
Sizzle的使用
复杂的css例如not(a, b)
属性部分:
toggleClass( “className”, state ) - 增加了一个布朗值的参数。
筛选文档:
.closest( selector ) - 找到离这个元素最近的一个父元素。这跟parents不一样。
is() 也支持更复杂的选择器了。
操作文档:
HTML Injection重写了
$(”<script/>”) 就自动转化为 $(document.createElement(”script”))
css:
offset()重写了
事件:
Live 事件
jQuery.Event
trigger()会冒泡了
效果:
hide() .show()之类的加快速度
内置动画效果考虑到了margin和 padding
.toggle( boolean ) 多提供了一个参数
jQuery.fx.off 关闭所有动画
AJAX:
.load()支持了文本格式的数据
工具:
新增jQuery.isArray
内部:
jQuery.support
另外这回改用YUI的工具压脚本了
========================================
最后预告一下,jQuery文档官网已经针对1.3版做了修改,中文文档也在紧张制作中。


