Submitted by gouki on 2010, July 21, 9:43 PM
P3P,不算是新名词,但还是有些人不清楚。事实上我也不清楚。。。在百度上看到有这玩意就备份下来。说真的,我只是知道用,但不知道为什么用。额。。很明显,因为在ucenter同步的时候,在discuz的ui/api里有写过。
看内容吧。。。。
IE6/IE7支持的P3P(Platform for Privacy Preferences Project (P3P) specification)协议默认阻止第三方无隐私安全声明的cookie,Firefox目前还不支持P3P安全特性,firefox中自然也不存 在此问题了。
在frameset里面,也就是里面的frame是来自第三方站点(不同IP或不同域名),那么默认情况下IE会自动禁用这些站点的cookie, 也就是在请求某url时在HTTP header里不发送它们的cookie,包括session的cookie。注意,这些站点在response里面设置的cookie还是会被发送到浏 览器的。
在用户浏览a.php时 A.com写入的为第一方Cookie,其嵌入的iframe指向 b.php.这时B.com写入的就为第三方Cookie了,所以它是被IE当在了大门外。 所以,每次当用户提交的cookie提交时,就挂掉了.因为传不到真实的服务器.
解决方案.
PHP的程序,可以直接在B网站中写入www.kobsky.cn 小眼世界ýñ ëÕRÏz-Z
PHP代码
- <?php
- header('P3P: CP="CURa ADMa DEVa PSAo PSDo OUR BUS UNI PUR INT DEM STA PRE COM NAV OTC NOI DSP COR"');
- ?>
这样就能接受第三方的Cookie啦。
lighttpd的服务器
XML/HTML代码
- server.modules = ("mod_setenv")
- setenv.add-response-header = ( "P3P" => "CP='CURa ADMa DEVa PSAo PSDo OUR BUS UNI PUR INT DEM STA PRE COM NAV OTC NOI DSP COR'")
apache的服务器
XML/HTML代码
- <VirtualHost>
- Header set P3P 'CP="CURa ADMa DEVa PSAo PSDo OUR BUS UNI PUR INT DEM STA PRE COM NAV OTC NOI DSP COR"'
- </VirtualHost>
IIS的服务器www.kobsky.cn 小眼世界ýñ ëÕRÏz-Z
增加一个网站http头来解决问题;www.kobsky.cn 小眼世界ýñ ëÕRÏz-Z
管理工具——〉选择一个网站——〉属性——〉 http头,增加一个http头www.kobsky.cn 小眼世界ýñ ëÕRÏz-Z
然后输入头名:P3Pwww.kobsky.cn 小眼世界ýñ ëÕRÏz-Z
输入头内容:CP=CAO PSA OUR
jsp页面:
XML/HTML代码
- <%
- response.setHeader("P3P","CP=CAO PSA OUR");
- %>
java代码最简单的办法,增加一个filte:
Java代码
- public class TransNameFilter extends HttpServlet implements Filter {
- private static org.apache.commons.logging.Log logWriter =
- LogFactory.getLog(TransNameFilter.class.getName());
-
-
-
-
- public TransNameFilter() {
- super();
-
- }
-
-
-
- public void init(FilterConfig arg0) throws ServletException {
-
- }
-
-
-
-
- public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
- throws IOException, ServletException {
-
- HttpServletRequest hreq = (HttpServletRequest) request;
- String transName = hreq.getParameter("transName");
- if (Util.isNullOrEmpty(transName)) {
- logWriter.fatal(" there is no transName for this request");
- } else {
-
- logWriter.info(" transName is " + transName);
- }
-
- HttpServletResponse res = (HttpServletResponse) response;
-
- res.setHeader("P3P","CP=CAO PSA OUR");
- if (chain != null)
- chain.doFilter(request, response);
-
- }
-
-
-
-
- public void destroy() {
-
- }
-
- }
Tags: session, cookie, p3p
PHP | 评论:0
| 阅读:32442
Submitted by gouki on 2010, June 25, 2:14 PM
本以为越狱是一件非常难很有技巧的事情,怎么着也得在身上刻上地图,然后潜入。最后再杀掉两三个人再出去?
后来,在网上找了一下,非常方便。只要两个工具就OK了。
一个是shsh备份工具,一个是spirit。在电脑下运行一下就OK了
额,看这三篇文章吧:
1、iPad 越狱前的准备工作——备份
2、Spirit越狱成功 详细步骤放出
3、iPad越狱失败后怎么办?
4、iPad越狱失败不用怕 iPad白苹果恢复教程
本想放到一篇博客里,但为了记录下来。所以准备每篇文章开一贴,以保存这些数据。
Tags: apple, ipad, spirit
Misc | 评论:0
| 阅读:22033
Submitted by gouki on 2010, June 19, 8:33 AM
原文在这里:http://www.bopor.com/?p=652,我只是做个简单的转述。主要是因为这种架构在单台服务器上也可以做个参考,比如队列,当我一台服务器承受不了太大的访问时,我可以先把很多东西扔到队列里去,交由后台执行(当然是指一些比较重要而又不需要即时显示的。比如图片处理等 )
OK,不多说了,直接上原文的重点为:
分库设计,数据库拆分
XML/HTML代码
- 最初是由一台主库和一台从库组成,当时从库只用作备份和容灾,当主库出现故障时,从库就手动变成主库,一般情况下,从库不作读写操作(同步除外)。随着压力的增加,我们加上了memcached,当时只用其缓存单行数据。但是,单行数据的缓存并不能很好地解决压力问题,因为单行数据的查询通常很快。所以我们把一些实时性要求不高的Query放到从库去执行。后面又通过添加多个从库来分流查询压力,不过随着数据量的增加,主库的写压力也越来越大。
怎么样对应用户和数据库呢?
· 按算法对应
· 按索引/映射表对应
分库会给你在应用的开发和部署上都带来很多麻烦。
· 不能执行跨库的关联查询
· 不能保证数据的一致/完整性
· 所有查询必须提供数据库线索
· 自增ID
XML/HTML代码
- 如果要在节点数据库上使用自增字段,那么我们就不能保证全局唯一。这倒不是很严重的问题,但是当节点之间的数据发生关系时,就会使得问题变得比较麻烦。我们可以再来看看上面提到的评论的例子。如果photo_comments表中的comment_id的自增字段,当我们在DB- 2.photo_comments表插入新的评论时,得到一个新的comment_id,假如值为101,而User-A的ID为1,那么我们还需要在DB-1.user_comments表中插入(1, 101 …)。 User-A是个很活跃的用户,他又评论了User-C的照片,而User-C的数据库是DB-3。很巧的是这条新评论的ID也是101,这种情况很用可能发生。那么我们又在DB-1.user_comments表中插入一行像这样(1, 101 …)的数据。那么我们要怎么设置user_comments表的主键呢(标识一行数据)?可以不设啊,不幸的是有的时候(框架、缓存等原因)必需设置。那么可以以 user_id、 comment_id和photo_id为组合主键,但是photo_id也有可能一样(的确很巧)。看来只能再加上photo_owner_id了,但是这个结果又让我们实在有点无法接受,太复杂的组合键在写入时会带来一定的性能影响,这样的自然键看起来也很不自然。所以,我们放弃了在节点上使用自增字段,想办法让这些ID变成全局唯一。为此增加了一个专门用来生成ID的数据库,这个库中的表结构都很简单,只有一个自增字段id。当我们要插入新的评论时,我们先在ID库的photo_comments表里插入一条空的记录,以获得一个唯一的评论ID。当然这些逻辑都已经封装在我们的框架里了,对于开发人员是透明的。为什么不用其它方案呢,比如一些支持incr操作的Key-Value数据库。我们还是比较放心把数据放在MySQL里。另外,我们会定期清理ID库的数据,以保证获取新ID的效率。
我这里只有一个小纲要,更多还是看原文吧。
最后介绍一下Yupoo的资料:
作为国内最大的图片服务提供商之一,Yupoo! 的 Alexa 排名大约在 5300 左右。同时收集到的一些数据如下:
带宽:4000M/S (参考)
服务器数量:60 台左右
Web服务器:Lighttpd, Apache, nginx
应用服务器:Tomcat
其他:Python, Java, MogileFS 、ImageMagick 等
关于 Squid 与 Tomcat
Squid 与 Tomcat 似乎在 Web 2.0 站点的架构中较少看到。我首先是对 Squid 有点疑问,对此阿华的解释是”目前暂时还没找到效率比 Squid 高的缓存系统,原来命中率的确很差,后来在 Squid 前又装了层 Lighttpd, 基于 url 做 hash, 同一个图片始终会到同一台 squid 去,所以命中率彻底提高了”
对于应用服务器层的 Tomcat,现在 Yupoo! 技术人员也在逐渐用其他轻量级的东西替代,而 YPWS/YPFS 现在已经用 Python 进行开发了。
名词解释:
YPWS–Yupoo Web Server YPWS 是用 Python开发的一个小型 Web 服务器,提供基本的 Web 服务外,可以增加针对用户、图片、外链网站显示的逻辑判断,可以安装于任何有空闲资源的服务器中,遇到性能瓶颈时方便横向扩展。
YPFS–Yupoo File System 与 YPWS 类似,YPFS 也是基于这个 Web 服务器上开发的图片上传服务器。
【Updated: 有网友留言质疑 Python 的效率,Yupoo 老大刘平阳在 del.icio.us 上写到 “YPWS用Python自己写的,每台机器每秒可以处理294个请求, 现在压力几乎都在10%以下”】
图片处理层
接下来的 Image Process Server 负责处理用户上传的图片。使用的软件包也是 ImageMagick,在上次存储升级的同时,对于锐化的比率也调整过了(我个人感觉,效果的确好了很多)。”Magickd“ 是图像处理的一个远程接口服务,可以安装在任何有空闲 CPU资源的机器上,类似 Memcached的服务方式。
我们知道 Flickr 的缩略图功能原来是用 ImageMagick 软件包的,后来被雅虎收购后出于版权原因而不用了(?);EXIF 与 IPTC Flicke 是用 Perl 抽取的,我是非常建议 Yupoo! 针对 EXIF 做些文章,这也是潜在产生受益的一个重点。
图片存储层
原来 Yupoo! 的存储采用了磁盘阵列柜,基于 NFS 方式的,随着数据量的增大,”Yupoo! 开发部从07年6月份就开始着手研究一套大容量的、能满足 Yupoo! 今后发展需要的、安全可靠的存储系统“,看来 Yupoo! 系统比较有信心,也是满怀期待的,毕竟这要支撑以 TB 计算的海量图片的存储和管理。我们知道,一张图片除了原图外,还有不同尺寸的,这些图片统一存储在 MogileFS 中。
对于其他部分,常见的 Web 2.0 网站必须软件都能看到,如 MySQL、Memcached 、Lighttpd 等。Yupoo! 一方面采用不少相对比较成熟的开源软件,一方面也在自行开发定制适合自己的架构组件。这也是一个 Web 2.0 公司所必需要走的一个途径。
Tags: 架构, python, php, mq
PHP | 评论:3
| 阅读:30845
Submitted by gouki on 2010, June 18, 9:13 AM
信息架构的定义
根据维基百科的定义,信息架构(Information Architecture, 简称IA)是在信息环境中,影响系统组织、导览、及分类标签的组合结构。它是基于信息架构方法论,并运用计算机技术 管 理和组织信息的一个专门学科。信息架构并非一开始就应用于网站设计,其起源于情报科学,最初应该是用于图书馆等地方的信息组织和信息检索的。
《用户体验的要素——以用户为中心的WEB设计》这本书中对信息架构的定义基于网站设计:信息架构着重于设计组织分类和导航的结构,从而让用户可以 提高效率、有效地浏览网站的内容。
具体的就不再多说的,可能各有各的理解,这里直接来看一个实例——Wordpress的信息架构模式:
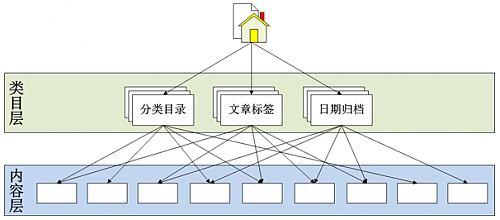
当然,上面这个图只能展示一个大体的网站信息架构,中间的类目层也许不止一层,会有大类、子类、子子类……底层可以是文章也可能是页面或者一些其他 的具体内容。而网站的内部关系也往往因为全局或局部导航、网站内链和内容关联等功能的存在而复杂的多,图上的箭头也会密集很多,但我们无需罗列所有内容间 的关系,关键是在理清基本的结构。
信息架构的类型
还是参考《用户体验的要素——以用户为中心的WEB设计》中对信息架构的几个分类:
层次结构(Hierarchical Structure)
也叫树形结构,是最常见的网站信息架构模式,上面举例的Wordpress的信息架构就是典型的层次结构。树形结构中箭头的方向不一定是自上而下 的,也可能是自下而上或者是双向的,而内容层之间也会因为一些关联链接的存在而存在同层次间的指向箭头。
矩阵结构(Matrix Structure)
矩阵结构比较注重“维”的概念,即从多维的角度来检索信息,如时间、地域、内容分类等,典型的应用就是内容管理系统(CMS)网站或者电子商务类网 站,比如你浏览豆瓣的电影时可以筛选:2010年—美国—科幻,也许这个时候《钢铁侠2》就呈现在你面前了。
线性结构(Sequential Structure)
看到线性结构也许你马上会想到面包屑,它将网站中最重要的一个信息架构路线展现了出来,即使它无法为你提供你在网站上的平面坐标,但至少它显示了你 现在正处于关键线路的哪个点上;当然,网站的一些关键路径一般也是按照线性结构涉及的,比如用户注册流程或电子商务网站的购买流程等。
网站分析与信息架构
根据网站业务模式的不同,可以选择适合自己网站的信息架构的模式,无论是上面的哪种信息架构模式,只要设计和运用合理,用户便能够在你的网站上以最 方便的形式、最快的速度找到他们需要的信息。
但当我浏览某些网站时,有时真的会让我感觉到“找不到北”,结果就是直接关闭该页面,如果不希望让已经进入了你的网站的用户轻易地离开,网站信息架 构的好坏将直接影响网站的用户体验。所以我们需要通过一些方法来检验网站的信息架构是否满足用户的信息检索的需求。
1.尝试整理出类似上面例子中的网站信息架构图
这个是最简单最直观的方法,如果你的网站信息架构足够清晰,那么画出这样的图对你来说也绝非难事;而当网站的应用比较复杂、内容比较宽泛,那么可能 要整理出网站的整体信息架构就会相对困难,但我相信一个设计优秀的网站只要稍加整理,大体的信息架构图还是画得出来的;而当你绞尽脑汁就是理不清你的网站 的信息架构的头绪的时候,那么说明你的网站需要优化了。
2.通过网站分析的方法验证信息架构的合理性
本文的副标题是“让用户更容易地找到需要的信息”,所以我们需要分析用户是否能够在你的网站上方便快捷地找到他们需要的信息,这里推荐一种方法—— 寻找网站中的迷失用户(Lost Visits)。
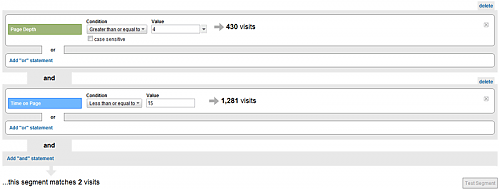
在一个合理的信息架构下,大多数的用户是不会在你的网站上迷路的;反之,混乱的信息架构会导致大量的用户迷失方向,就像是进入了一个巨大的迷宫。那 么如何寻找这些迷失用户?我们可以先分析下这类用户的行为,最明显特征的就是:连续点击好几个页面,每个页面都只是初步浏览(因为没有找到他们需要的信 息)就转到另外的页面或直接离开了。所以我们可以借助网站分析中的两个度量:
浏览页面数(Depth of Visit):一次访问中用户总的浏览页面数;
页面平均停留时间(Avg. Time on Page):一次浏览中用户在每个页面的平均停留时间,即该次访 问总停留时间(Time on Site)/该次访问页面数(Depth of Visit)。
我们可以用户细分的方法把那些浏览页面数较多,但页面平均停留时间较短的用户浏览看作是迷失用户,具体的数值可 以根据网站自身的特点进行定义,比如我定义我的博客中浏览页面数大于等于4,而页面平均停留时间小于等于15秒的Visits为迷失用户的浏览行为,我们 可以借助Google Analytics中的高级群组(Advanced Segment)来 区分出这类用户,关于如何使用Google Analytics的高级群组功能,可以参考蓝鲸的文章——Google Analytics功能篇—高级群组,如下图:
当然,你可能会说这种用户区分的方法不准确,这类用户不一定就是迷失用户,也有可能他们确实找到并浏览了具体内容,但因为内容不够吸引人或者其他原 因而马上离开了该页面。所以这里用高级群组划分出来的这类Visits的数量不能看作是迷失用户的一个绝对数值,我们只能认为里面的大部分Visits都 是迷失用户,而不排除存在某些另类。所以更合理的方法是通过计算这类Visits占网站总Visits的比例情况来分析网站的信息架构到底是否合理,我们 可以在Google Analytics上面选取网站的All Visits和Lost Visits进行比例和趋势的比较,如下图:
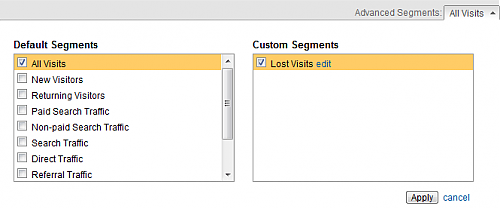

网站中迷失用户浏览的所占比例只需通过Lost Visits/All Visits就可以计算得到,但这个时候你还是无法根据这个计算结果来评判网站的信息架构到底是好是坏,因为还缺少一个基准线(Benchmark)或 者说是评判标准。在Google Analytics上面的Visitors标签下,提供了“Sites of similar size”的基 准比较(Benchmarking),你可以选择与你的网站相似类型的网站作为基准线进行数据比 较,这的确是个很好的参考,因为通过比较能够更加明确你的网站在同类型网站中的优势和劣势,为网站优化指明方向。GA借助其强大的数据平台可以为我们提供 基准线,但也许对于上面这个例子会显得无能为力,这个时候需要我们理性地自己去选择一个合适的基准线,比如我的博客目前类目和内容都还比较少,那么我可能 会定义我的网站的迷失用户比例应该控制在1%以下;但如果对于一个应用和内容比较复杂的网站,那么基准线显然会需要定得更高一点。一旦某段时间的数据越过 了基准线,就需要关注一下网站的信息架构是不是在趋于混乱了,是不是该进行一下整理和优化了。
总之,一个好的信息架构能够帮助用户更容易地找到他们需要的信息,从而有效地提升网站的用户体验,所以,尝试着去优化下你的网站的信息架构。如果你 有更好的方法能够有效地检验网站的信息架构的优劣,或者能够明确地分析得到网站信息架构的哪些细节上存在缺陷,希望能与我交流,我期待网站分析方法在优化 网站信息架构方面的更多的应用。
原文来自:《优 化网站信息架构》。
不过,如果你看过《胜于言传》这本书,其实就会发现,上面的内容和该书有一点雷同,只是胜一书中讲的更多的是如何改善用户体验,让用户看到更多的东西(指有效内容),如果你没有读过,还真是推荐看一下的。点击进入当当书店选购该书。
该书在当当中可是没有差评的,书的简介也真的很简单:
无论是居家还是办公,只要是在网上,我们通常都想快速地获取和使用信息。我们上网不是为了寻求某些问题的答案,就是为了完成某些任务——搜集信息、只阅读 我们需要的内容。我们都很忙.根本没有时间阅读网站中的太多内容。
本书会帮你为网站用户成功地撰写内容。它为网站内容的创建和修改提供了相应的策略、流程和方法。它有助于你对网站内容进行规划,组织、撰写、设计和测试, 从而吸引用户不断地光顾你的网站。
Ginny Redish大师介绍了如何创建有用、可用的网站内容。Ginny大师曾指导过许多写作人员、信息设计人员和内容负责人员,向他们传授过编写网站的原则和 秘诀。帮助他们创建了易于浏览、易于阅读且易于使用的网站信息。
这本具有实践性和教育性的书籍可以帮助所有创建网站内容的人更出色地完成他们的工作。
本书特色:
·全书用全彩图和来自真实网站的例子 清晰地阐述了内容编写原则。
·实例中带有改进前后的对比效果,写作的风格简明易读。
·包含针对网络版新闻稿、网络版法律声明和网 络版其他文档的具体原则。
·为了让有特殊需求的人们也可以使用网站,介绍了相关的编写技巧。
如果真想把内容当成主打对象,这本书还是值得购买的。
Tags: 架构, 胜于言传, 分析, 优化
PHP | 评论:3
| 阅读:23811
Submitted by gouki on 2010, June 14, 10:52 AM
这篇文章写的挺有意思,所以觉得可以复制下来给大家作参考。挺有意思,部分内容也是值得看看的。比如诚信,比如薪资在最后谈的单位需要到网上了解一下平均薪资之类的。
上全文吧
最近经历了本人有屎以来最漫长最离奇的求职旅程。其中之艰难困苦,非一般人可以想象,终于在家人的鼓励以及顽强的求生本能下坚强的挺了过来。现在回想起来,对于这段宝贵的经历,本人实在不敢独美,特此与网友分享。
1.笔试面试。
事情的开始跟所有人一样,我只是在网上向一个公司A(某世界500强)投了一个简历,打算换个工作。后来就收到了面试通知,过去以后,来了一个人非常冷漠 的给我一张卷子,说30分钟答完,说完就走了。我一看,只有两题,数据库的,我对着题看了足足十分钟,都不会,差点就想拔腿走人了。还好我急中生智,用手 机把这题目拍下来,发给另外一个同事,然后就开始等他帮我答。由于实在等得不耐烦了,我就开始瞎玩,这时我猛然发现,背面还有7道题!我狂写到第三道题的 时候,刚才那人过来了,说对不起时间到了,就收走了。我当时就懵了,好歹也工作那么多年了,从来没这么狼狈过。
我以为接下来应该是要通知我谢谢参与了,又进来两个人,我跟他们解释了一番,大概意思是:你们可以不要我,但是我刚才没看到另外一页有题,其实我水平不是 那么差。结果他们说:没事。我们聊聊别的吧。然后开始聊一些.net技术方面的。基本没有什么不会的,除了没做过的,我慢慢心里有点底了。然后是英语面 试,表现也不错。最后面试官提了一句:我发现最近来面试的数据库方面都比较差。我苦笑了一下。
结论:答题看好有没有两面。面试之前对自己最薄弱环节的重点突击一下。对自己有信心,尽量发挥自己的强项。
2.入职体检。
然后就是等。终于来通知了,该公司要求我先体检,然后才能给我答复是否跟我签offer。然后我去 了他们指定的医院体检,在做心电图的时候,我可能是因为跑着去的,结果检出来的结果是心率不齐。我心想不会因为这个不要我把,然后就跟医生商量。又测了一 次。还是不行。后来医生也不耐烦了,她说,你早说你是入职体检,我跟你写好点,但是其实是没关系的。后来我就算了,结果这个体检报告到了应聘单位,还是通 知我去签offer。
结论:如果你查出来有心率不齐(还有脂肪肝)一般来说不会影响入职,如果你要保险起见,可以先跟医生说明,我这是入职体检,然后让他手下留情。说点好话,一般都不会为难你的。传染病除外。
3.个人诚信调查表
在去公司面试之前,前台要求你填写一张应聘人员信息表,大概是写你的工作经历,学历等信息,我相信大家都填过。也许填的丝毫不差,也许也有人填的比较随意。如果你跟我一样填的比较随意,你就得小心了。
在签玩offer以后,我得到一张个人诚信调查表,我本人是第一次见到这张表,该表要求你填写你前三家就职过的公司的工作时间职位等信息并且要敲上单位的人事章。在入职的当天,凭offer跟这张表到公司报名。
在我向原单位提出辞职,然后递交这张表的时候,问题出现了。我的入职日期写错了。比如我是2008年1月入职,结果我写成2007年12月。这样就造成我 的个人诚信调查表中的入职日期,跟应聘人员信息中的入职日期不相符。我立刻意识到这个问题的严重性,马上联系了新单位,新单位给我的答复是,请你把正确的 信息重新发给我们。我照做了,一天以后,他们给我回复,对不起,我们要收回我们的offer。我原单位已经提出了辞职,新单位又收回了offer,我就这样失业了。另:体检自己先付的2百多体检费也打了水漂,还白白被扎了一针,抽了一管血。
结论:假如你准备去应聘比较正规的单位,比如世界500强,仔细检查您的简历,千万别写错了。
4.没人在乎的期望薪资
失业的日子并不可怕,可怕的是你会渐渐怀疑是不是自己真的诚信出了问题。经过多日辗转,我又联系了 一家国内的公司B,面试非常顺利。HR跟我谈了项目的背景,我非常感兴趣。对方说规模可以达到一百多人,是国内的制造业项目,正在大量的招人。然后我问, 还有下轮面试吗,答:没有了。问:那接下来是等通知然后就谈offer了吗?答:没错,我们会在下个礼拜通知你。然后我告诉了她我的期望薪资。
接下来就是漫长的等待,中间我拒掉了一个世界500强的职位(做维护)。我等到礼拜4还没通知,实在忍不住打过去,对方答复:我们技术 总监还需要跟你面谈一次,但是他没空,要下周。我又等了一周,最后终于等到面试。过去见到技术总监,该总监人很不错,但是基本没有问我问题,只是随便说了 几句,就走了。然后HR来了,跟我说,我们总监觉得你都不错,但是我们给不了你期望的薪资,然后给出了一个比我期望低一年3W左右的数字,我说我没办法接 受。差太多了,而且为什么你不早说呢。对方说,那如果我们给出的工资您不同意的话,你还得等通知,我们商量好了再通知你。
结论:很多公司会把薪资放在最后谈,哪怕是他们能给的远远低于你的期望。如果可以的话尽量现在网上打听好该公司能给多少工资。另外:工作效率差的公司一定要多提防。
5.职位突然被Close
我一直等他们通知,或者告诉我给不了,或者告诉我可以。但是一个电话都没有。我又等了4天,主动联 系了他们。在反复询问后,对方终于说出了:这个职位因为现在不着急,可能被close掉!所以不管多少薪水,根本就不是薪水的问题,而是职位被技术总监 close掉了。我差点昏倒。难怪那天面试他不问我问题,难怪故意杀这么多工资,目的是让我自己走人!但是我分明记得,他们的招聘专员说正在大量招人要招 1百多人。。。的情景音容宛在。
结论:除了offer,什么话都不要相信。另外,主动联系,可以节省很多时间
6.任何时刻保持风度
出了这种事情,任何人都很生气。我也一样,对于他们招聘专员的相当不专业的做法,我实在是无语。但是我依然保持了我的风度,我没有说一 个脏字,也没有任何的抱怨。我说那好吧,我明白了。我再去找工作。对方也许是实在不好意思了,说,我一定给你介绍另外一个职位好吗,我说好吧,但是心里根 本没在意。实际上,我正好就是去了她给介绍的这个职位,另一个外资公司C,各方面我都挺满意。
7.如何写你的期望薪资
在万里长征的最后一步,还是发生了一点小小的不愉快。就是薪资问题。上海这边很多公司都是13薪。13薪的意思是,13个工资,再加奖金。一般年终奖跟第 13个月的工资一起发。而年终奖是浮动的,一般不会体现在合同内。面试之前,他们就会问你期望薪资是多少,也许你心里想的是,我想要10K*13个月再加 上年终奖。但是你回答的时候只会说一个数字,比如说:10k。
你的期望薪资如何被砍:
第一招:偷换13薪概念,他们会告诉你,我们这里是13薪,但是第13薪就是年终奖。一下砍1万。
第二招:期望薪资VS最低薪资。假如你说期望薪资10k,他们会问你,那你的最低底线是多少?你一犹豫:说9k吧。一下又砍一K。
第三招:先贬低你,再杀价。你说你期望10k吗?我们刚刚签了一个人,比你工作时间还长,技术比你还牛,学历比你还高,他才10k,所以我们如果给你 10k,对他就不公平了。这样吧,给你9k如何。一般来说,你经过多轮面试,几乎不会因为1k而放弃这个职位的。
第四招:试用期打折。有的公司试用期100%工资,有的则不然。
因此:你该如何填写你的期望薪资呢?假如你想要10K*13个月再加上年终奖,那么最好首先换算成12个月,就是11k,然后再加1k=12k。然后他们就说了,我们给不了那么多,然后你再问,那你们是13个月工资加奖金呢?还是12个月工资加奖金?千万不要说,我期望的薪资是13薪,每个月11k。他们马上就说,我们是13薪,但是13薪是年终奖,11k我们也给不了,只能给你10k。这样你还是亏一万。
对于一个数千人的公司,一个人省一万,就是几千万,所以千万不要以为他们不会跟你计较这么点钱。
8.认识人比网上投简历效率高
虽然在我求职的一个月中,我在中华英才网,智联招聘等等网站投了数十份简历,居然只有两家给我打过 电话,一家我还没时间去面试。原因至今未知。相反我3年前找工作的时候,反而比现在情况好一点。也许是老年程序员更没人要了吧。而在这三年当中,由于我不 时的更新我的简历,总有些猎头,准确的是招聘专员来联系我,我虽然不打算换工作,但是会留下他们的msn。3年下来,我的msn上有30多位招聘专员的 msn。他们会把一些职位需求写在msn的签名上。这次还是靠以前认识的某位招聘专员给介绍的。
9.平时多背面试题
面试笔试会背问到的问题其实就那么些。目前我经历过最难的要数微软和盛大。可以说问题的深度并没有 特别深。顶多问到垃圾回收的具体原理,或者是聚集索引非聚集索引的物理区别,或者是JavaScript的原型继承。大多数都是死的知识点,没有什么特别 好的问题。只是有的公司问的范围比较广,从.net 框架asp.net,html,js,数据库等等挨个问一遍。
有些我觉得比较好的面试官我印象深刻的,他们大多会根据你的回答把问题深入。比如他问你mvc是什么,你说一种表现模式,那他就接着问,那你知道除了mvc还有别的什么表现模式吗?这就需要你对各个知识点深入的了解。
另外我觉得有些问题问的比较好的,是一些你无法作假,也无法靠短时间突击完成的问题,这些问题可以真正考察出应聘者的能力。比如
:你每年花多少钱购买技术书籍?(我不花钱买书?)
:你觉得在工作中,什么时候最开心?(发工资的时候?)
:你在工作中碰到过什么很诡异的错误?
:你碰到过什么很困难的工作?最后如何解决的?
作者:肖敏(和我是本家,呵呵),地址:http://www.cnblogs.com/xiaomin/archive/2010/06/14/1758077.html
Tags: 求职
Misc | 评论:6
| 阅读:22350


